



















Understanding Life Before DevOps
To appreciate the power of GitLab CI/CD pipelines and the DevOps method of software development, we must understand how software was built before tools like GitLab appeared. Although you won’t learn anything practical in this chapter, you’ll learn about the world that GitLab CI/CD pipelines grew out of and get a clear picture of what problems GitLab CI/CD pipelines solve. Having a grasp of these things will set you up to understand why GitLab CI/CD pipelines operate the way they do and will open your eyes to the amazing power that they bring to the software development life cycle. In short, the best way to understand how things are now is to understand how bad they used to be!
This chapter will introduce you to a fictional but realistic web app called Hats for Cats+, which sells – you guessed it – head coverings for felines. You’ll get a quick overview of what’s involved with turning Hats for Cats from an idea into a well-written, tested, and deployed web app. You’ll see how these tasks would have to be done in a world where GitLab CI/CD pipelines don’t exist so that the benefits of GitLab will be even more obvious when you learn about them in later chapters.
In this chapter, we’re going to cover the following main topics:
- Introducing the Hats for Cats web app
- Building and verifying code manually
- Security-testing code manually
- Packaging and deploying code manually
- Problems with manual software development life cycle practices
- Solving problems with DevOps
Introducing the Hats for Cats web app
Hats for Cats is a pretend web app for selling baseball caps, cowboy hats, and bowlers for your favorite furry friends. Imagine that it’s a standard online store like hundreds or thousands of others that you’ve used. It lets people browse through the catalog of hats, put items in a shopping cart, and enter billing and shipping information.
The user experience or graphic design of Hats for Cats doesn’t matter for this book. The web app framework that it’s based on doesn’t matter. Even the computer language that it’s written in doesn’t matter. I’ll say that again because it’s an important but possibly surprising point: this book is language-agnostic. It will include examples in several computer languages, to increase the chances that at least some of the examples are in a language that you’re familiar with. But whether your apps – or the Hats for Cats web app – are written in Java, JavaScript, Python, Ruby, or any other language doesn’t matter. The general GitLab CI/CD principles described in this book apply regardless.
What does matter are the general steps that you need to take to make sure the code is of high quality, behaves as expected, is secure, has adequate performance, is packaged sensibly, and is deployed to the right environments at the right times. This book focuses on how GitLab CI/CD pipelines can make various steps in the software development life cycle (SDLC) easier, faster, and more reliable. It won’t show you how to write the Hats for Cats web app. It will be assumed that all the coding happens behind the scenes, after which you’ll be shown how to build, verify, secure, package, and release that code.
With that in mind, let’s walk through the high-level steps that you’d need to follow to get your code ready for users, in a world before GitLab existed. These are all the manual equivalents of what GitLab CI/CD pipelines can do for you automatically. But understanding the limitations of the manual processes, and the pain and tedium involved with following them, will help you understand the real power of GitLab.
Building and verifying code manually
Before GitLab CI/CD pipelines appeared, you needed to build and verify your code manually. This was often a terrible, soul-crushing experience, for reasons we’ll discuss here.
Building code manually
Building code depends on what language you use. If you use an interpreted language such as Python or Ruby, then building might not be necessary at all. But if you’re writing in a compiled language, you’d need to build your app by compiling its source code.
Imagine that you’re using Java. The following are just some of the different ways to compile Java source code into executable Java classes:
- You could use the
javacJava compiler that ships with the Java Development Kit - You could use the Maven build tool
- You could use the Gradle build tool
There are lots of reasons that this manual build process is a tedious, annoying chore that most developers would happily leave behind:
- It’s subject to user error: how many times have you forgotten whether you need to point
javacat the top-level package that your classes are in, or at the individual class files? - It’s slow, taking anywhere from a few seconds to several minutes, depending on how big your application is. That can add up to a lot of downtime.
- It’s easy to forget, causing confusion when you accidentally execute old code that doesn’t behave like you thought it would.
- Badly written code can fail to compile, causing everyone to waste time as the build engineer sends the code back to the developers for fixes, and waits for those fixes to arrive.
Verifying code manually
Once you’ve built your code, you need to verify that it’s working correctly. Testing takes countless shapes and forms, and there are more kinds of tests than we could describe in this book. But here are some of the most common forms that you may want to subject your code to:
Figure 1.1 – Tests for verifying code
Functional tests
Does your program do what it’s supposed to? That’s the question that functional tests answer. Most programming projects begin with a specification that describes how the software should behave: given a certain input, what output should it provide? The developers are only done with their jobs when the code they write conforms to those specs. How do they know that their code conforms? That’s where functional tests come in.
Just like there are many forms of testing in general, there are many sub-categories of testing that, together, make up functional tests.
Happy path testing makes sure that the program works as expected when it’s fed common, valid input. For example, if you feed 2 + 2 into a calculator, it had better return 4! Happy path tests seem like the most important kind of tests because they check behavior that users are most likely to run into when they use your software. But in fact, you can usually cover the most common use cases with just a few happy path tests. The tests that cover unusual or unexpected cases tend to be far more numerous.
Speaking of unusual cases, that’s where edge- case testing enters the scene. If you imagine a spectrum of input values, most values that users will input will fall in the middle of that spectrum. For example, calculator users are more likely to enter something such as 56 ÷ 209 (where these values are in the middle of the range of values the calculator will accept) than they are to enter 0 + 0 or 999,999 – 999,999 (since those values are at the edges of the range). Edge -case testing makes sure that input values at the far edges of the acceptable spectrum don’t break your software. Can you create a username that consists of a single letter? Can you order 9,999 copies of a book? Can you deposit 1 cent into a bank account? If the specifications say that your software should be able to handle these edge cases, you’d better make sure it really can!
If edge -case testing ensures that your software can handle an input value that’s right up against the edge of acceptable values, corner-case testing confirms that your software can handle two or more simultaneous edge cases. Think of it as turbocharged edge-case testing that challenges your software by placing it in even more uncomfortable (but still valid) situations. For example, does your banking app allow you to schedule a withdrawal for the smallest valid amount of currency at the farthest valid date in the future? There’s no need to limit corner-case testing to two input values: if your software accepts three or ten or 100 input values at a time, you’ll need to make sure it works when every input is pushed all the way to the extreme end of the range of values valid according to the specifications.
That handles cases where the software is given valid values. But do you also need to make sure it behaves correctly when it receives invalid values? Of course you do! This form of testing is sometimes called unhappy path testing and is usually a lot more fun for testers to perform since it’s more likely to reveal bugs. All software must gracefully handle unexpected, invalid, or malformed data, and you need tests to prove that it does so. To return to our earlier examples, you’ll need to make sure your calculator doesn’t crash when you ask it to divide a number by zero. You have to check that the banking app doesn’t accidentally give you a deposit when you ask to withdraw negative-6 dollars. And your currency conversion software should give a sensible error message when you ask about an exchange rate on February 31, 2020.
Since there are usually more ways to enter bad data than good data into an application, developers often concentrate on correctly processing expected data but fail to think through the types of unexpected, malformed, or out-of-range data that their users might enter. Programs need to anticipate and gracefully handle all sorts of data – both good and bad. Writing complete sets of both happy path and unhappy path tests is the best way to make sure that the developer has written code that behaves well no matter what data a user throws at it.
Those are some of the kinds of behavior that involve both valid and invalid data that tests can check for. But there’s another dimension that you can use to categorize tests: the size of the code chunk that a test targets.
In most cases, the smallest piece of code that a test can check is a single method or function. For example, you may want to test a function called alphabetize that takes any number of strings as input and returns those same strings, but now in alphabetical order. To test this function, you would probably use a kind of test called a unit test. It tests a single unit of code, where a unit in this case is a single function. You could have a collection of several unit tests that all cover that function, albeit in different ways:
- Some might cover happy paths. For example, they could pass the
dog,cat, andmousestrings as input. - Some might cover edge or corner cases. For example, they could pass the function a single empty string, strings that consist only of digits, or strings that are already alphabetized.
- Some might cover unhappy paths. For example, they could pass the function an unexpected data type, such as booleans, instead of the expected data type of strings.
To verify the behavior of bigger pieces of code, you can use integration tests. These don’t look at single functions, but instead at how groups of functions interact with each other. For example, imagine that your currency conversion application has four functions:
-
get_input, which takes input from the user in the form of a source currency, a source amount, and a target currency. -
convert, which converts that amount of source currency into the correct amount of the target currency. -
print_output, which tells the user how much target currency the conversion produces. main, which is the main entry point to your app. This is the function that is called when your app is used. It calls the three other functions and passes the output of each function as input to the next.
To make sure these functions play nicely together – that is, to check if they integrate well – you need integration tests that call main, as opposed to unit tests that call get_input, convert, and print_output. This lets you test at a higher level of abstraction, which is to say a level that gets closer to how a real user would use your application. After all, a user isn’t going to call get_input in isolation. Instead, they will call main, which, in turn, will call the other three functions and coordinate passing values between them. It’s easy to write a function that works as expected on its own, but it’s harder to make a collection of functions cooperate to build a larger piece of logic. Integration tests spot this type of problem in a way that pure unit tests can’t.
Testers often think of various sorts of tests as forming a pyramid. According to this model, unit tests occupy the wide, low base of the pyramid: they are low-level in the sense that they test fundamental pieces of code, and there are many of them. Integration tests occupy the middle of the pyramid: they operate at a higher level of abstraction than unit tests, and there are fewer of them. At the top of the pyramid is a third category of tests, which we’ll talk about next – user tests:
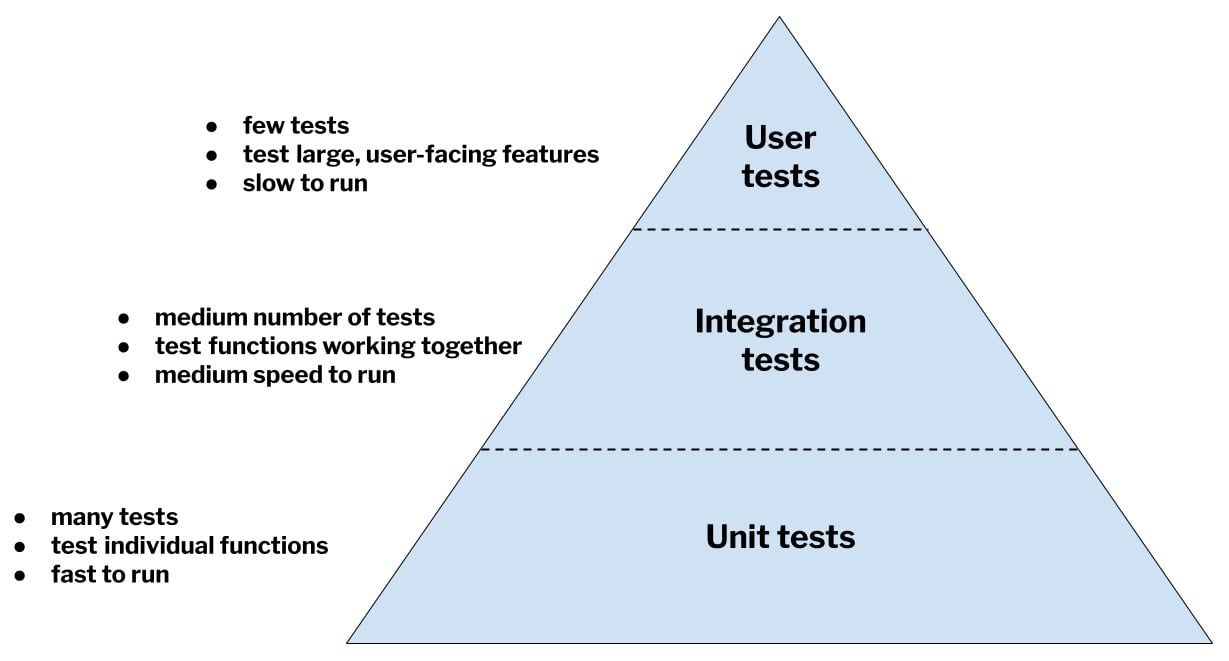
Figure 1.2 – The test pyramid
The final type of test, user tests, simulate a user’s behavior and exercise the software the same way a user would. For example, if users interact with a foreign exchange app by entering a source currency, an amount of that source currency, and a target currency, and then expect to see the output in the form of an amount of the target currency, then that’s exactly what a user test will do. This might mean that it uses the app’s GUI by clicking on buttons and entering values in fields. Or it might mean that it calls the app’s REST API endpoints, passing in input values and inspecting the result for the output value. However, it interacts with the application and does so in a fashion that’s as similar to a real user as possible. As with unit and integration tests, user tests can include happy path tests, edge- and corner-case tests, and unhappy path tests to cover all the scenarios that the software’s specifications describe, as well as any other scenarios that the test designer can concoct.
So far, we’ve explained the different purposes of unit, integration, and user tests, but we haven’t described another fundamental difference. Unit and integration tests are almost always automated. That is, they are computer programs that test other computer programs. While user tests are automated whenever possible, there are enough difficulties with writing reliable, reproducible tests that interact with an application’s GUI that many user tests must be run manually instead. Web applications are notoriously hard to test because of unpredictable behavior around load times, incomplete page rendering, missing or incompletely loaded CSS files, and network congestion. This means that while software development teams often attempt to automate user tests of web applications, more often than not, they end up with a hybrid of automated and manual user tests. As you may have guessed, manual user tests are extraordinarily expensive to run, both in terms of time and tester morale.
Performance tests
After that high-level tour of functional testing, you may be thinking that we’ve covered all the testing bases. But we’re just getting started. Another aspect of your application that should probably be tested is its performance: does it do what it’s supposed to do quickly enough to keep users from getting frustrated? Does it meet performance specifications the developers may have been given before they started coding? Is its performance significantly better or worse than the performance of its competitors? These are some of the questions that performance tests are designed to answer.
Performance testing is notoriously difficult to design and carry out. There are so many variables to consider when gauging how quickly your application runs:
- What environment should it be running in during the tests? Creating an environment identical to the production environment is often prohibitively expensive, but what corners can you cut in the test environment that won’t skew the results of performance tests too badly?
- What input values should your performance tests use? Depending on the application, some input values may take significantly longer to process than others.
- If your application is configurable, what configuration settings should you use? This is especially important if there is no standard configuration that most users settle on.
Even if you can figure out how to design useful performance tests, they often take a long time to run and, in some cases, produce inconsistent results. This leads teams to rerun performance tests frequently, which causes them to take even more time. So, performance tests are among the most critical, and also more expensive, of all the test types.
Load tests
Performance tests have a close cousin called load tests. Whereas performance tests determine how quickly your software can perform one operation (a single currency conversion, a single bank deposit, or a single arithmetic problem, for example), load tests determine how well your application handles many users interacting with it at the same time. Load tests suffer from many of the same design difficulties as performance tests and can produce similarly inconsistent results. They can be even more expensive to set up since they need a way to simulate hundreds or thousands of users.
Soak tests
As your application runs for hours or days, does it allocate memory that it never reclaims? Does it consume huge amounts of disk space with overzealous logging? Does it launch background processes that it never shuts down? If it suffers from any of these resource “leaks,” it could lose performance or even crash as it runs low on memory, disk space, or dedicated CPU cycles. These problems can be found with soak tests, which simply exercise your software over an extended period while monitoring its stability and performance. It’s probably obvious that soak tests are extraordinarily expensive in terms of time and hardware resources to run and monitor.
Fuzz tests
An underutilized but powerful form of testing is called fuzz testing. This approach sends valid but strange input data into your software to expose bugs that traditional functional tests may have missed. Think of it as happy path testing while drunk. So, instead of trying to create an account with the username “Sam,” try a username that consists of 1,000 letters. Or try to create a username that is entirely spaces. Or include Klingon alphabet Unicode characters in a shipping address.
Fuzz testing introduces a strong element of randomness: the input values it sends to your software are either completely randomly generated or are random permutations of input values that are known to be unproblematic for your code. For example, if your code translates PDF files into HTML files, a fuzz test may start by sending slightly tweaked versions of valid, easily handled PDF files, and then progress to asking your software to convert purely random strings that bear no resemblance to PDF files at all. Because fuzz testing can send many thousands of random input values before it stumbles on an input value that causes a crash or other bug, fuzz tests must be automated. They are simply too cumbersome to run manually.
Static code analysis
Another strictly automated form of testing is static code analysis. Whereas the other tests we’ve discussed try to find problems in your code as it runs, static code analysis inspects your source code without executing it. It can look for a variety of different problems, but in general, it checks to make sure you’re conforming to recognized coding best practices and language idioms. These could be established by your team, by the developers of the language itself, or by other programming authorities.
For example, static code analysis could notice that you declare a variable without ever assigning a value to it. Or it could point out that you’ve assigned a value to a variable but then never refer to that variable. It can identify unreachable code, code that uses coding patterns known to be slower than alternative but functionally equivalent patterns, or code that uses whitespace in unorthodox ways. These are all practices that may not cause your code to break exactly but could keep your code from being as readable, maintainable, or speedy as it could have been.
More challenges of verifying code
So far, we’ve described just some of the ways that you may want to verify the behavior, performance, and quality of your code. But once you’ve finished running all these different types of tests, you face the potentially difficult question of how to parse, process, and report the results. If you’re lucky, your test tools will generate reports in a standard format that you can integrate into an automatically updated dashboard. But you’ll likely find yourself using at least one test tool or framework that can’t be shoehorned into your normal reporting structure, and which needs to be manually scanned, cleaned, and massaged into a format that’s easy to read and disseminate.
We’ve already mentioned how performance tests in particular often need to be run repeatedly. But in fact, all of these types of tests need to be run repeatedly to catch regressions or smooth out so-called “flickering” tests, which are tests that sometimes pass and sometimes fail, depending on network conditions, server loads, or countless other unpredictable factors. This means that the burden of either manually running tests, or managing and triggering automated tests, is far greater than it appears at first. If you’re going to run tests repeatedly, you need to figure out when and how often to do so, you need to make sure the right hardware or test environments are available at the right times, and you need to be flexible enough to change your testing cadence when conditions change, or management asks for more up-to-date results. The point is that testing is tough, time-consuming, and error-prone, and all these difficulties are exaggerated every time humans need to get involved with making sure the tests happen in the right way at the right time.
Even though we’ve just said that tests should typically be run and then repeatedly rerun, there’s another countervailing force at play. Because executing tests is expensive and difficult, there’s a tendency to want to run them as infrequently as possible. This tendency is encouraged by a common development model that has developers building a feature (or sometimes an entire product) and then throwing the code over the wall to the Quality Assurance (QA) team for validation. This strict division between building the code and testing the code means that on many teams, tests are only run at the end of the development cycle – whether that’s at the end of a two-week sprint, the end of a year-long project, or somewhere in-between.
The practice of infrequent or delayed testing leads to an enormous problem: when the developers turn over a huge batch of code for testing – thousands or tens of thousands of lines of code that had been developed by different people using different coding styles and idioms over weeks or months – it can be extremely hard to diagnose the root cause of any bugs that the tests unearth. This, in turn, means that it’s hard to fix those bugs. Just like big haystacks hide needles more effectively than small haystacks, large batches of code make it hard to find, understand, and correct any bugs that they contain. The longer a development team waits before passing code on to the QA team, the bigger this problem becomes.
This concludes our lightning-fast survey of functional tests, load tests, soak tests, fuzz tests, and static code analysis. In addition, we explained some of the hidden difficulties involved with running all of these different sorts of tests. You might be wondering why we’ve discussed testing at all. The reason is that understanding the challenges of testing – getting a feel for how many ways there are to verify your code, how important the different forms of tests are, how time-consuming it is to set up test environments, how much of a hassle it is to manually run non-automatable user tests, how tricky it can be to process and report the results, and how tough it can be to find and fix bugs that are lurking within a huge bundle of code – is a huge part of understanding how difficult software development was before the advent of DevOps. Later in this book, when you see how GitLab CI/CD pipelines simplify the process of running different kinds of tests and viewing their results, and when you understand how tests that run early and often make problems easier to detect and cheaper to fix, you can look back at these cumbersome test procedures and feel sympathy for the poor developers who had to wade through this part of the SDLC before GitLab existed. Life is much better in the GitLab era!
Security-testing code manually
We mentioned that functional testing is just one form of testing. Another important form is security testing. It’s so important and so difficult to get right that it’s typically performed by specialized teams that are separate from traditional QA departments. There are many ways approaches to security testing, but most boil down to one of three categories:
- Inspect source code
- Interact with running code
- Inspect the third-party dependencies used by your project
Also, there are different kinds of problems that security tests can look for. At first glance, some of these problems may not look like they fall under the umbrella of security, but they all contribute to potential data loss or manipulation of your software by malicious actors:
- Non-standard coding practices
- Unsafe coding practices
- Source code dependencies that contain known vulnerabilities
Let’s look at some specific varieties of security testing and see how they use different techniques to look for different sorts of problems.
Static code analysis
You can often find unsafe coding practices simply by asking a security expert to review your source code. For example, if you ask for user input and then use that input to query a database, a wily user might be able to launch a so-called SQL injection attack by including database commands in their input. Competent code reviewers will spot this sort of problem immediately and can often propose easy-to-implement solutions.
For example, the following pseudocode accepts input from the user but doesn’t validate the input before using it in a SQL statement. A clever user could enter a malicious value such as Smith OR (0 = 0) and cause more information to be revealed than the developer intended:
employee_name = get_user_input() sql = "SELECT salary FROM employee_records WHERE employee_name = $employee_name" ENTERcall_database(sql)
Code reviews can also identify code that might not be obviously unsafe, but that uses non-standard idioms, unusual formatting, or awkward program structure that make code harder for other team members (or even the original author) to read and maintain. This can indirectly make the code more susceptible to security problems in the future, or at the very least make future security problems harder for code reviewers to find.
For example, the following Python function accepts an unusually large number of parameters and then ignores most of them. Both these traits are considered to be poor programming practices, even if neither threatens the behavior or security of the code:
def sum(i, j, k, l, m, n, o, p, q, r): return i + j
Static code analysis can sometimes happen automatically. Many IDEs offer static code analysis as a built-in feature: they draw red warning lines under any non-standard or unsafe code they detect. This can be a great help but is best thought of as a complement to manual code reviews rather than a full substitute.
Secret detection
You can think of secret detection as a special form of static code analysis. There are many types of sensitive data that you want to keep out of your software’s source code. It’s not hard to think of examples:
- Passwords
- Deploy keys
- Public SSH or GPG keys
- US Social Security numbers
- Unique personal identification numbers that are used by other countries
Just as static code analysis scans source code to search for programming or security problems, secret detection scans source code to find secrets that should be removed and stored in a more secure location. For example, the following Java code contains a Social Security number that can be seen by anyone with read access to the code:
String bethSSN = "555-12-1212";
if (customerSSN.equals(bethSSN))) {
System.out.println("Welcome, Beth!");
}
Dynamic analysis
Looking at source code is useful, but there are many categories of software defects that are more easily found by interacting with executing code. This interaction could take the form of using an application’s GUI just like a human would, sending requests to a REST API endpoint, or hitting various URLs of a web app with different values in the requests’ query strings.
For example, your web server might be configured in such a way as to include its version number in the headers of every response. This might seem like harmless information, but it can provide clues to malicious actors about which web server-targeted exploits are likely to work against your site, and which exploits your web server is probably immune to.
To take another example, complicated logic in your code might obscure the fact that you can trigger an unhandled divide-by-zero error by entering a particular set of input values. As discussed earlier, problems like this may not initially feel like security risks, but a clever hacker can often find ways to exploit simple bugs in ways that expose data, cause data loss, or result in denial-of-service attacks.
For example, the following Ruby code could produce a ZeroDivisionError instance when it runs, which, in turn, could cause the program to crash:
puts 'how many hats do you have?'
num_hats = gets.to_i
puts 'how many cats do you have?'
num_cats = gets.to_i
puts "you have #{num_hats / num_cats} hats per cat"
Dependency scanning
Dependency scanning is the practice of comparing the names and version numbers of each of your product’s dependencies against a database of known vulnerabilities and identifying which of those dependencies should be upgraded to a later version or removed entirely to improve your software’s security. Virtually every non-trivial piece of software written these days relies on tens, hundreds, or thousands of third-party, open source libraries. The source code of the most popular libraries is pored over by Black Hat hackers looking for possible exploits. These exploits are often quickly fixed by the library’s maintainers, but if your project is using old, unpatched versions of those libraries, dependency scanning will let you know that your code might be vulnerable to those known exploits.
A perfect example of the need for this type of security scanning is in the news at the time of writing. Many Java projects rely on an open source Java library called Log4j, which provides a convenient way to log informational, warning, or error messages. A vulnerability was recently discovered that allows hackers to remotely run commands or install malware on any computer Log4j is running on. That’s a huge problem! Fortunately, it’s exactly the kind of problem that dependency scanning can spot. Any up-to-date dependency scanner will let you know if your software has a dependency – either directly or via other dependencies – on an unpatched version of Log4j, and will advise you what version of Log4j you should upgrade to.
Container scanning
These days, many software products are delivered as Docker images. The simplest possible description of a Docker image is that it is a Linux distribution that has your application installed on it and is then packaged in an image format that can be executed by Docker or similar tools. If you build a Docker image that includes an out-of-date version of a Linux distribution that contains security vulnerabilities, your application will not be as secure as it could be.
Container scanning looks at the base Linux image that your Dockerized application is installed on and checks a database of known security vulnerabilities to see if your packaged application might be susceptible to exploits. For example, because CentOS 6 stopped being maintained in 2020, the libraries that it includes have many severe security vulnerabilities. Container scanning would alert you to this problem and suggest that you consider upgrading your application’s Docker image to use CentOS 7 or later as a base image.
Manual security testing summary
With that, we’ve looked at a variety of tests designed to detect security vulnerabilities or security-adjacent problems, such as failing to adhere to coding best practices. While it may seem like a lot of different steps to go through before you can put a simple web app into production, there has never been more ways to steal information or shut down a service, and there’s no reason to think that trend will turn around any time soon. So, like it or not, responsible developers need to think about – and probably implement – all these different security tests:
Figure 1.3 – Some of the many types of security testing
Some of these tests must be performed manually. Others have automated tools to help. But automated tests are still burdensome: you still have to install security testing tools or frameworks, configure testing tools, update test frameworks and dependencies, set up and maintain test environments, massage reports, and display reports in some integrated fashion. If you try to simplify matters by outsourcing some of these tasks to outside companies or Software-as-a-Service (SaaS) tools, you’ll need to learn separate GUIs for each tool, maintain different user accounts for each service, manage multiple licenses, and do a host of other tasks to keep your tests working smoothly.
This section has shown you more ways that life before GitLab was difficult for development teams. As you’ll learn in an upcoming chapter, GitLab’s CI/CD pipelines replace the awkward, multi-step security testing processes described previously with fast, automated security scanners that you configure once and then benefit from for as long as you continue to develop your software project. We’ll revisit this topic in much more detail later.
Packaging and deploying code manually
Now that your software has been built, verified, and is secure, it’s time to think about packaging and deploying it. Just like the other steps we’ve discussed, this process can be an annoying burden when done manually. How you package an application into a deployable state depends not only on the computer language it’s written in but also on the build management tool you’re using. For example, if you’re using the Maven tool to manage a Java product, you’ll need to run a different set of commands than if you’re using the Gradle tool. Packaging Ruby code into a Ruby gem requires another, completely different, process. Packaging often involves collecting tens, hundreds, or thousands of files, bundling them with a language-appropriate tool, double-checking that documentation and license files are complete and in the right place, and possibly cryptographically signing the packaged code to show that it’s coming from a trusted source.
We’ve already mentioned the task of specifying which license your code is being released under. This leads to another kind of testing that needs to be done before you can deploy your code to production: license compliance scanning.
License compliance scanning
Most open source, third-party libraries are released under a particular software license. There are countless licenses that developers can choose from, but the bulk of open source libraries use just a handful of them, including the MIT License, GNU General Public License (GPL), and the Apache License. It’s critical to know which licenses your dependencies use because you are not legally allowed to use dependencies that use licenses that are incompatible with your project’s overall license.
What would make two licenses incompatible? Some licenses, such as the Peaceful Open Source License, explicitly prohibit the use of the software by the military. Another, more common cause of license clashes is between so-called Copyleft licenses and proprietary licenses. Copyleft licenses such as the GPL stipulate that any software that uses libraries covered by the GPL must themselves use the GPL license. Copyleft licenses are sometimes called viral licenses because they pass their license restrictions on to any software that uses dependencies that are covered by those types of licenses.
Since you’re legally required to make sure that your main license is compatible with the licenses of any third-party libraries you use, you need to add a license scanning step to your packaging and deployment workflow. Whether this is done manually or with an automated tool, you must identify and replace any dependencies that you’re not allowed to use.
Deploying software
Once your software has been packaged and you’ve double-checked the licenses of your dependencies, you face the hurdle of deploying the code to the right place at the right time.
Most development teams have several environments they deploy code to. Every organization sets these up differently, but a typical (albeit minimal) environment structure might look like this:
- One or more test environments.
- A staging environment or pre-production environment that’s configured as similarly to the production environment as possible, but usually much smaller in scale.
- A production environment.
We’ll talk about the use of these different environments in more detail later, but for now, you just need to understand how each of these environments is used as part of the basic deployment workflow. As code is being developed, it is normally deployed to the test environment so that the QA team or release engineers can make sure it does what it’s supposed to do, and integrates with the existing code without causing any problems. As the new code is declared to be ready to add to the production code base, it is traditionally deployed to the staging environment so that a final round of tests can be made to make sure there are no incompatibilities between the new code and the environment in which it will ultimately run. If those tests go well, the code is finally deployed to the production environment, where real users can benefit from whatever feature, bug fix, or other improvements the new code introduced.
As you might imagine, making sure that the right code gets deployed to the right environment at the right time is a tricky but critically important job. And deploying is just half the battle! The other half is making sure the various environments are available and healthy. They must be running on the right types and scale of hardware, they must be provisioned with the right user accounts, they must have network and security policies configured correctly, and they must have the correct versions of operating systems, tools, and other infrastructure software installed. Of course, there are maintenance tasks, upgrades, and other system reconfiguration jobs that must be planned, carried out, and fixed when they go awry. The mind-boggling scope and complexity of these tasks are why big organizations have whole teams of release engineers making sure everything works smoothly and frantically troubleshooting when it doesn’t.
This completes our tour through the most common SDLC tasks that happen after you’ve checked in the new code:
- Build the code.
- Verify the code’s functionality, performance, resource usage, and more with a variety of tests.
- Make sure the code doesn’t have security vulnerabilities by using even more tests.
- Package the code into a deployable format.
- Look for and remediate any problems with incompatible licenses.
- Deploy the code to the appropriate environment.
By now, you should be sensing a theme: life before GitLab was complicated, error-prone, and slow. These adjectives certainly apply to the package, license scan, and release tasks that occur near the end of the SDLC. But as you’ll learn in more detail in a later chapter, GitLab CI/CD pipelines take care of the most burdensome aspects of these jobs for you. By letting the pipeline handle the boring and repetitive stuff, you can concentrate on the more creative and satisfying parts of writing software.
Problems with manual software development life cycle practices
Now that you have the general picture of what happens to software between the time that developers have finished writing it and the time that users can get their hands on it, you can start to understand how tough this process can be. Many tasks need to happen along this path of delivering secure, working code to users:

Figure 1.4 – Major tasks in the SDLC
Some of these tasks are normally done manually, while others can be automated either partially or fully. But both approaches have problems associated with them, which turn each task into a potential pain point.
What are the difficulties of manually performing these tasks? Let’s take a look:
- They take time. They often take significantly more time than you budget for them, even after you’ve had experience manually performing them in the past. There are countless ways things can go wrong when performing any of these tasks, all of which require time-consuming troubleshooting and remediation. Even when everything goes right, there is simply a lot of work involved with each of these tasks. And remember the 1979 law proposed by physicist Douglas Hofstadter: It always takes longer than you expect, even when you take into account Hofstadter’s Law.
- They are error-prone. Because you’re relying on humans to perform them – humans who might be tired, bored, or distracted – they’re all susceptible to misconfigurations, data entry mistakes, or steps that have been forgotten or applied in the wrong order, to name just a few ways human error can lead to things going wrong.
- They are tough on employee morale. Nobody likes doing routine, repetitive work, especially when the stakes are high and you must get it right. The prospect of running through a standard 2-hour set of manual tests for the 20th time in 2 weeks has caused many a QA engineer to wonder if maybe software wasn’t the smartest career choice for them after all.
- They have a high potential for miscommunication or misreporting. When a manual tester has finished running their stultifying 2-hour test suite, do they have enough brain cells left to accurately record what worked and what didn’t? All that testing is pointless if we can’t rely on the results being recorded accurately, but anyone who has executed a difficult manual test plan knows how many ambiguities there can be in the results, how many unexpected conditions there can be to potentially skew the tests, and how hard it can be to know how to explain these factors to the people who rely on that reporting. And that’s not even factoring in the very large possibility of simply recording results incorrectly, even when they’re unambiguous.
For all these reasons, you can see how expensive – in terms of time, money, and employee goodwill – manual tasks are likely to be.
But if some of the tasks we’ve described can be automated, would that eliminate the problems that we face with manual tasks? Well, it would solve some problems. But adding a series of automation tools to the SDLC would introduce a whole new set of problems. Consider all the extra effort and expense involved with doing so and all the tasks that building custom toolchains entail:
- Researching and selecting tools for each automatable task.
- Buying and renewing licenses for each tool
- Choosing a hosting solution for each tool
- Provisioning users for each tool
- Learning different GUIs for each tool
- Managing databases and other infrastructure for each tool
- Integrating each tool with other tools in the SDLC
- Figuring out how to display the status and results of each tool in a central location if that’s even possible
- Deal with tools that are buggy, that become deprecated, or that become less compelling as better alternatives appear on the market
Even after all the problems of manual or automated tasks are handled, there’s one big problem that’s unavoidable for teams that use this model: it’s a sequential workflow. Steps happen one after another. One team writes the software, then throws the code over the wall to another team that builds the software. That team, in turn, tosses the code to a third team that’s responsible for validating the software. When they’re done, they generally send it to yet another group of engineers who do security testing. Finally, a release team gets ahold of it so that they can deploy the code to the right place. There are plenty of ways this process can deviate from this basic description, but the fundamental concept of doing one step at a time, passing the code to the next step only after the earlier steps are complete, is a trait that many, many software development teams’ workflows shared.
So far, it might not be obvious why sequential workflows pose a problem, so let’s spell it out. Because of the difficulty of executing these steps manually, or the hassles of keeping automated steps running smoothly and reliably across multiple tools, this workflow typically happens only sporadically. How often the code gets run through these steps varies from team to team, but the time and expense involved means that code changes typically stack up over days, weeks, or sometimes even months before they get built, validated, secured, and deployed properly. And that, in turn, means that problems detected during this process are expensive to fix. If a functional test fails, a security test detects a vulnerability, or an integration test reveals that the code doesn’t play well together once it’s all deployed to the same environment, identifying what code is causing the problem is like finding a needle in a very large haystack. If 5,000 lines of code across 25 classes have changed, 16 dependencies have been upgraded to more recent versions, the Java version has changed from version 16 to version 17, and the test environment is running on a different version of Ubuntu, those are a whole lot of variables to investigate when you’re tracking down the source of the problem and figuring out how to fix it.
At this point, you know enough about traditional, pre-DevOps software development that we can summarize the biggest problem it faces in one sentence: sequential workflows that involve manual tasks or automated tasks performed by different tools cause development to be slow, releases to be infrequent, and the resulting software to be of less high quality than it could be.
But there’s good news: DevOps was invented to solve these problems. And GitLab CI/CD pipelines were invented to make DevOps easier to use. We’ll look at both of those things next.
Solving problems with DevOps
What do we mean by DevOps? Despite the term being used by the software community for at least 10 years (the first session of devopsdays, which is now the biggest DevOps-focused conference, was held in 2009), today, there is no single, standard definition that everyone agrees on.
When GitLab talks about DevOps, it’s referring to a new way of thinking about the SDLC, which focuses on four things:
- Automation
- Collaboration
- Fast feedback
- Iterative improvement
Let’s look at each of these in more detail.
The primary focus of DevOps is to automate as many software development tasks as possible. This removes the challenges associated with manually building, testing, securing, and releasing. But this is of limited usefulness if it exchanges those challenges for the hassles and expense associated with assembling a collection of manual tools. We’ll see how GitLab solves that problem later, but for now, just understand that a proper DevOps workflow is fully automated.
By fostering collaboration among all the teams involved with writing software, and among all the members of each team, DevOps helps dissolve the points of friction and potential trouble that happen every time the code is transferred from one team to another. If there’s no “wall” to throw the code over – if every step in the process is transparent to everyone involved with writing and delivering the software – everyone feels committed to the overall quality of the code and feels like they’re playing for the same team. Different people still have primary responsibility for specific tasks, but the overall culture moves toward joint ownership of the code and commonly shared goals.
Fast feedback might be the most crucial and revolutionary element of DevOps. It can be thought of as the result of two other concepts we talked about previously: concurrent workflows and shifting left. When you stop to think about it, those two terms boil down to the same thing: do all the building, verifying, and securing tasks as soon as possible for each batch of code that developers check in. Do them all concurrently instead of sequentially, to ensure that they happen at the far left of the software development timeline. And run all these tasks immediately for every chunk of new code that’s contributed, no matter how small. By running these tasks early and often, you minimize the size of the code changes that are tested, which makes it cheaper and easier to troubleshoot any software bugs, configuration issues, or security vulnerabilities found by the tests.
If you’re finding and fixing problems quickly, you’ll be able to release your software to customers more often. By getting new features and bug fixes to them sooner, you’re helping them benefit from the iterative improvement of your product. By releasing smaller code changes at shorter intervals with a lower risk of breaking things and needing to roll back, you’re living up to the catchphrase of making your releases boring. In this case, boring is a good thing: most customers would rather have frequent, small upgrades that pose little risk than infrequent, massive changes that have a greater chance of wreaking havoc and needing to be reverted.
By taking advantage of automation, collaboration, fast feedback, and iterative improvement, DevOps practices produce code that’s higher quality, cheaper to develop, and delivered more frequently to users.
How GitLab implements DevOps
GitLab is a tool that enables all the software development tasks we’ve discussed, using the DevOps principles we’ve just outlined. The most important trait of GitLab is that it’s a single tool that unifies all the steps in the SDLC under one umbrella.
Remember how shifting from manual processes to automated processes solved some problems but raised a host of new problems associated with automation? GitLab’s single-tool approach solves those problems as well. Consider the benefits of having the following single, unified toolchain approach:
- One license to buy (unless your team uses the free, feature-limited version of GitLab, in which case there are no licenses to buy)
- One application to maintain and upgrade
- One set of user accounts to provision
- One database to manage
- One GUI to learn
- One place to look – one radar screen, so to speak – to see the reports and statuses of all your build, validation, security, packaging, and deploy steps
So, GitLab being a single tool solves the problems you get from using disparate automation tools. Even better, the fact that it uses a single set of components and entities, all of which are aware of and communicate well with each other, enables and encourages the collaboration, concurrency, transparency, and shared ownership that are such critical aspects of DevOps. Once you have concurrent tasks, you get fast feedback. And that, in turn, allows for iterative improvement via boring releases.
The bulk of the rest of this book deals with the technique that GitLab uses to put those DevOps principles into practice: CI/CD pipelines. We won’t define what that term means quite yet, but you’ll learn all about it in future chapters. For now, you just need to know that CI/CD pipelines are where the GitLab rubber meets the DevOps road: they are how GitLab’s single-tool model performs all the building, verification, securing, packaging, and deploying that your code has to go through.
We’d be remiss not to mention that a large part of GitLab is dedicated to helping you plan, assign, and manage work. But that’s separate from the CI/CD pipelines, and therefore is beyond the scope of this book. We will touch on ancillary topics from time to time, simply because everything in GitLab is so interrelated that there’s no way to stay entirely within the boundaries of CI/CD pipelines. But most of the rest of this book will explain what GitLab pipelines can do, and how to use them.
Summary
People who don’t work for software companies might not realize there’s more to writing software than just... writing software. After it’s checked in, a long and complicated series of steps must be followed to build, verify, secure, package, and deploy code before users can get their hands on it. All these steps can be done manually, or some of them – under certain conditions – can be automated. But both manual and automated approaches to preparing software pose problems.
DevOps is a relatively new approach to accomplishing these steps. It combines automation, collaboration, fast feedback, and iterative improvement in a way that lets teams make software better, faster, and more cheaply.
GitLab is a DevOps tool that collects all these tasks under one umbrella, allowing a software development team to accomplish everything with a single tool, using a single GUI, with all the test results and deployment status displayed in a single place. Its focus on automation addresses the problems raised by manual processes. Its single-tool model addresses the problems raised by automated processes. GitLab puts all the DevOps principles into practice through the use of CI/CD pipelines, which will be the main focus of the rest of this book.
But before we deal with CI/CD pipelines, we need to take a quick, one-chapter detour into Git, the tool around which GitLab is built. Without a solid grounding in the basics of Git, you’ll likely find many of GitLab’s concepts and terminology confusing. So, batten down the hatches, grab a big mug of your favorite caffeinated beverage, and let’s jump into Git.
