



















 Download code from GitHub
Download code from GitHub
Introducing Natural Language Processing
Why in the world would a network analysis book start with Natural Language Processing (NLP)?! I expect you to be asking yourself that question, and it’s a very good question. Here is why: we humans use language and text to describe the world around us. We write about the people we know, the things we do, the places we visit, and so on. Text can be used to reveal relationships that exist. The relationship between things can be shown via network visualization. It can be studied with network analysis.
In short, text can be used to extract interesting relationships, and networks can be used to study those relationships much further. We will use text and NLP to identify relationships and network analysis and visualization to learn more.
NLP is very useful for creating network data, and we can use that network data to learn network analysis. This book is an opportunity to learn a bit about NLP and network analysis, and how they can be used together.
In explaining NLP at a very high level, we will be discussing the following topics:
- What is NLP?
- Why NLP in a network analysis book?
- A very brief history of NLP
- How has NLP helped me?
- Common uses for NLP
- Advanced uses of NLP
- How can a beginner get started with NLP?
Technical requirements
Although there are a few places in this chapter where I show some code, I do not expect you to write the code yet. These examples are only for a demonstration to give a preview of what can be done. The rest of this book will be very hands-on, so take a look and read to understand what I am doing. Don’t worry about writing code yet. First, learn the concepts.
What is NLP?
NLP is a set of techniques that helps computers work with human language. However, it can be used for more than dealing with words and sentences. It can also work with application log files, source code, or anything else where human text is used, and on imaginary languages as well, so long as the text is consistent in following a language’s rules. Natural language is a language that humans speak or write. Processing is the act of a computer using data. So, NLP is the act of a computer using spoken or written human language. It’s that simple.
Many of us software developers have been doing NLP for years, maybe even without realizing it. I will give my own example. I started my career as a web developer. I was entirely self-educated in web development. Early in my career, I built a website that became very popular and had a nice community, so I took inspiration from Yahoo Chats (popular at the time), reverse-engineered it, and built my own internet message board. It grew rapidly, providing years of entertainment and making me some close friends. However, with any good social application, trolls, bots, and generally nasty people eventually became a problem, so I needed a way to flag and quarantine abusive content automatically.
Back then, I created lists of examples of abusive words and strings that could help catch abuse. I was not interested in stopping all obscenities, as I do not believe in completely controlling how people post text online; however, I was looking to identify toxic behavior, violence, and other nasty things. Anyone with a comment section on their website is very likely doing something similar in order to moderate their website, or they should be. The point is that I have been doing NLP since the beginning of my career without even noticing, but it was rule-based.
These days, machine learning dominates the NLP landscape, as we are able to train models to detect abuse, violence, or pretty much anything we can imagine, which is one thing that I love the most about NLP. I feel that I am limited only by the extent of my own creativity. As such, I have created classifiers to detect discussions that contained or were about extreme political sentiment, violence, music, art, data science, natural sciences, and disinformation, and at any given moment, I typically have several NLP models in mind that I want to build but haven’t found time. I have even used NLP to detect malware. But, again, NLP doesn’t have to be against written or spoken words, as my malware classifier has shown. If you keep that in mind, then your potential uses for NLP massively expand. My rule of thumb is that if there are sequences in data that can be extracted as words – even if they are not words – they can potentially be used with NLP techniques.
In the past, and probably still now, analysts would drop columns containing text or do very basic transformations or computations, such as one-hot encoding, counts, or determining the presence/absence (true/false). However, there is so much more that you can do, and I hope this chapter and book will ignite some inspiration and curiosity in you from reading this.
Why NLP in a network analysis book?
Most of you probably bought this book in order to learn applied social network analysis using Python. So, why am I explaining NLP? Here’s why: if you know your way around NLP and are comfortable extracting data from text, that can be extremely powerful for creating network data and investigating the relationship between things that are mentioned in text. Here is an example from the book Alice’s Adventures in Wonderland by Lewis Carroll, my favorite book.
What can we observe from these words? What characters or places are mentioned? We can see that the Dormouse is telling a story about three sisters named Elsie, Lacie, and Tillie and that they lived at the bottom of a well. If you allow yourself to think in terms of relationships, you will see that these relationships exist:
- Three sisters -> Dormouse (he either knows them or knows a story about them)
- Dormouse -> Elsie
- Dormouse -> Lacie
- Dormouse -> Tillie
- Elsie -> bottom of a well
- Lacie -> bottom of a well
- Tillie -> bottom of a well
It’s also very likely that the three sisters all know each other, so additional relationships emerge:
- Elsie -> Lacie
- Elsie -> Tillie
- Lacie -> Elsie
- Lacie -> Tillie
- Tillie -> Elsie
- Tillie -> Lacie
Our minds build these relationship maps so effectively that we don’t even realize that we are doing it. The moment I read that the three were sisters, I drew a mental image that the three knew each other.
Let’s try another example from a current news story: Ocasio-Cortez doubles down on Manchin criticism (CNN, June 2021: https://edition.cnn.com/videos/politics/2021/06/13/alexandria-ocasio-cortez-joe-manchin-criticism-sot-sotu-vpx.cnn).
Who is mentioned, and what is their relationship? What can we learn from this short text?
- Rep. Alexandria Ocasio-Cortez is talking about Sen. Joe Manchin
- Both are Democrats
- Sen. Joe Manchin does not support a house voting rights bill
- Rep. Alexandria Ocasio-Cortez claims that Sen. Joe Manchin is being influenced by the legislation’s reforms
- Rep. Alexandria Ocasio-Cortez claims that Sen. Joe Manchin is being influenced by “dark money” political donations
- There may be a relationship between Sen. Joe Manchin and “dark money” political donors
We can see that even a small amount of text has a lot of information embedded.
If you are stuck trying to figure out relationships when dealing with text, I learned in college creative writing classes to consider the “W” questions (and How) in order to explain things in a story:
- Who: Who is involved? Who is telling the story?
- What: What is being talked about? What is happening?
- When: When does this take place? What time of the day is it?
- Where: Where is this taking place? What location is being described?
- Why: Why is this important?
- How: How is the thing being done?
If you ask these questions, you will notice relationships between things and other things, which is foundational for building and analyzing networks. If you can do this, you can identify relationships in text. If you can identify relationships in text, you can use that knowledge to build social networks. If you can build social networks, you can analyze relationships, detect importance, detect weaknesses, and use this knowledge to gain a really profound understanding of whatever it is that you are analyzing. You can also use this knowledge to attack dark networks (crime, terrorism, and so on) or protect people, places, and infrastructure. This isn’t just insights. These are actionable insights—the best kind.
That is the point of this book. Marrying NLP with social network analysis and data science is extremely powerful for acquiring a new perspective. If you can scrape or get the data you need, you can really gain deep knowledge of how things relate and why.
That is why this chapter aims to explain very simply what NLP is, how to use it, and what it can be used for. But before that, let’s get into the history for a bit, as that is often left out of NLP books.
A very brief history of NLP
If you research the history of NLP, you will not find one conclusive answer as to its origins. As I was planning the outline for this chapter, I realized that I knew quite a bit about the uses and implementation of NLP but that I had a blind spot regarding its history and origins. I knew that it was tied to computational linguistics, but I did not know the history of that field, either. The earliest conceptualization of Machine Translation (MT) supposedly took place in the seventeenth century; however, I am deeply skeptical that this was the origin of the idea of MT or NLP, as I bet people have been puzzling over the relationships between words and characters for as long as language has existed. I would assume that to be unavoidable, as people thousands of years ago were not simpletons. They were every bit as clever and inquisitive as we are, if not more. However, let me give some interesting information I have dug up on the origins of NLP. Please understand that this is not the complete history. An entire book could be written about the origins and history of NLP. So that I quickly move on, I am going to keep this brief. I am going to just list some of the highlights that I found. If you want to know more, this is a rich topic for research.
One thing that puzzles me is that I rarely see cryptology (cryptography and cryptanalysis) mentioned as being part of the origins of NLP or even MT when cryptography is the act of translating a message into gibberish, and cryptanalysis is the act of reversing secret gibberish into a useful message. So, to me, any automation, even hundreds or thousands of years ago, that could assist in carrying out cryptography or cryptanalysis should be part of the conversation. It might not be MT in the same way that modern translation is, but it is a form of translation, nonetheless. So, I would suggest that MT goes back even to the Caesar cipher invented by Julius Caesar, and probably much earlier than that. The Caesar cipher translated a message into code by shifting the text by a certain number. As an example, let’s take the sentence:
I really love NLP.
First, we should probably remove the spaces and casing so that any eavesdropper can’t get hints on word boundaries. The string is now as follows:
ireallylovenlp
If we do a shift-1, we shift each letter by one character to the right, so we get:
jsfbmmzmpwfomq
The number that we shift is arbitrary. We could also use a reverse shift. Wooden sticks were used for converting text into code, so I would consider that as a translation tool.
After the Caesar cipher, many, many other techniques were invented for encrypting human text, some of which were quite sophisticated. There is an outstanding book called The Code Book by Simon Singh that goes into the several thousand-year-long history of cryptology. With that said, let’s move on to what people typically think of with regard to NLP and MT.
In the seventeenth century, philosophers began to submit proposals for codes that could be used to relate words between languages. This was all theoretical, and none of them were used in the development of an actual machine, but ideas such as MT came about first by considering future possibilities, and then implementation was considered. A few hundred years later, in the early 1900s, Ferdinand de Saussure, a Swiss linguistics professor, developed an approach for describing language as a system. He passed away in the early 1900s and almost deprived the world of the concept of language as a science, but realizing the importance of his ideas, two of his colleagues wrote the Cours de linguistique generale in 1916. This book laid the foundation for the structuralist approach that started with linguistics but eventually expanded to other fields, including computers.
Finally, in the 1930s, the first patents for MT were applied for.
Later, World War II began, and this is what caused me to consider the Caesar cipher and cryptology as early forms of MT. During World War II, Germany used a machine called the Enigma machine to encrypt German messages. The sophistication of the technique made the codes nearly unbreakable, with devastating effects. In 1939, along with other British cryptanalysts, Alan Turing designed the bombe after the Polish bomba that had been decrypting Enigma messages the seven years prior. Eventually, the bombe was able to reverse German codes, taking away the advantage of secrecy that German U-boats were enjoying and saving many lives. This is a fascinating story in itself, and I encourage readers to learn more about the effort to decrypt messages that were encrypted by the Enigma machines.
After the war, research into MT and NLP really took off. In 1950, Alan Turing published Computing Machinery and Intelligence, which proposed the Turing Test as a way of assessing intelligence. To this day, the Turing Test is frequently mentioned as a criterion of intelligence for Artificial Intelligence (AI) to be judged by.
In 1954, the Georgetown experiment fully automated translations of more than sixty Russian sentences into English. In 1957, Noam Chomsky’s Syntactic Structures revolutionized linguistics with a rule-based system of syntactic structures known as Universal Grammar (UG).
To evaluate the progress of MT and NLP research, the US National Research Council (NRC) created the Automatic Language Processing Advisory Committee (ALPAC) in 1964. At the same time, at MIT, Joseph Weizenbaum had created ELIZA, the world’s first chatbot. Based on reflection techniques and simple grammar rules, ELIZA was able to rephrase any sentence into another sentence as a response to users.
Then winter struck. In 1966, due to a report by ALPAC, an NLP stoppage occurred, and funding for NLP and MT was discontinued. As a result, AI and NLP research were seen as a dead end by many people, but not all. This freeze lasted until the late 1980s, when a new revolution in NLP would begin, driven by a steady increase in computational power and the shift to Machine Learning (ML) algorithms rather than hard-coded rules.
In the 1990s, the popularity of statistical models for NLP arose. Then, in 1997, Long Short-Term Memory (LSTM) and Recurrent Neural Network (RNN) models were introduced, and they found their niche for voice and text processing in 2007. In 2001, Yoshua Bengio and his team provided the first feed-forward neural language model. In 2011, Apple’s Siri became known as one of the world’s first successful AI and NLP assistants to be used by general consumers.
Since 2011, NLP research and development has exploded, so this is as far as I will go into history. I am positive that there are many gaps in the history of NLP and MT, so I encourage you to do your own research and really dig into the parts that fascinate you. I have spent much of my career working in cyber security, so I am fascinated by almost anything having to do with the history of cryptology, especially old techniques for cryptography.
How has NLP helped me?
I want to do more than show you how to do something. I want to show you how it can help you. The easiest way for me to explain how this may be useful to you is to explain how it has been useful to me. There are a few things that were really appealing to me about NLP.
Simple text analysis
I am really into reading and grew up loving literature, so when I first learned that NLP techniques could be used for text analysis, I was immediately intrigued. Even something as simple as counting the number of times a specific word is mentioned in a book can be interesting and spark curiosity. For example, how many times is Eve, the first woman mentioned in the Bible, mentioned in the book of Genesis? How many times is she mentioned in the entire Bible? How many times is Adam mentioned in Genesis? How many times is Adam mentioned in the entire Bible? For this example, I’m using the King James Version.
Let’s compare:
|
Name |
Genesis Count |
Bible Count |
|
Eve |
2 |
4 |
|
Adam |
17 |
29 |
Figure 1.1 – Table of biblical mentions of Adam and Eve
These are interesting results. Even if we do not take the Genesis story as literal truth, it’s still an interesting story, and we often hear about Adam and Eve. Hence, it is easy to assume they would be mentioned as frequently, but Adam is actually mentioned over eight times as often as Eve in Genesis and over seven times as often in the entire Bible. Part of understanding literature is building a mental map of what is happening in the text. To me, it’s a little odd that Eve is mentioned so rarely, and it makes me want to investigate the amount of male versus female mentions or maybe investigate which books of the Bible have the largest number of female characters and then what those stories are about. If nothing else, it sparks curiosity, which should lead to deeper analysis and understanding.
NLP gives me tools to extract quantifiable data from raw text. It empowers me to use that quantifiable data in research that would have been impossible otherwise. Imagine how long it would have taken to do this manually, reading every single page without missing a detail, to get to these small counts. Now, consider that this took me about a second once the code was written. That is powerful, and I can use this functionality to research any person in any text.
Community sentiment analysis
Second, and related to the point I just made, NLP provides ways to investigate themes and sentiments carried by groups of people. During the Covid-19 pandemic, a group of people has been vocally anti-mask, spreading fear and misinformation. If I capture text from those people, I can use sentiment analysis techniques to determine and measure sentiment shared by that group of people across various topics. I did exactly that. I was able to scrape thousands of tweets and understand what they really felt about various topics such as Covid-19, the flag, the Second Amendment, foreigners, science, and many more. I did this exact analysis for one of my projects, #100daysofnlp, on LinkedIn (https://www.linkedin.com/feed/hashtag/100daysofnlp/), and the results were illuminating.
NLP allows us to objectively investigate and analyze group sentiment about anything, so long as we are able to acquire text or audio. Much of Twitter data is posted openly and is consumable by the public. Just one caveat: if you are going to scrape, please use your abilities for good, not evil. Use this to understand what people are thinking about and what they feel. Use it for research, not surveillance.
Answer previously unanswerable questions
Really, what ties these two together is that NLP helps me answer questions that were previously unanswerable. In the past, we could have conversations discussing what people felt and why or describing literature we had read but only at a surface level. With what I am going to show you how to do in this book, you will no longer be limited to the surface. You will be able to map out complex relationships that supposedly took place thousands of years ago very quickly, and you will be able to closely analyze any relationship and even the evolution of relationships. You will be able to apply these same techniques to any kind of text, including transcribed audio, books, news articles, and social media posts. NLP opens up a universe of untapped knowledge.
Safety and security
In 2020, the Covid-19 pandemic hit the entire world. When it hit, I was worried that many people would lose their jobs and their homes, and I feared that the world would spin out of control into total anarchy. It’s gotten bad but we do not have armed gangs raiding towns and communities around the world. Tension is up, but I wanted a way to keep an eye on violence in my area in real time. So, I scraped police tweets from several police accounts in my area, as they report all kinds of crime in near real time, including violence. I created a dataset of violent versus non-violent tweets, where violent tweets contained words such as shooting, stabbing, and other violence-related words. I then trained an ML classifier to detect tweets having to do with violence. Using the results of this classifier, I can keep an eye on violence in my area. I can keep an eye on anything that I want, so long as I can get text but knowing how my area is doing in terms of street violence could serve as a warning or give me comfort. Again, replacing what was limited to feeling and emotion with quantifiable data is powerful.
Common uses for NLP
One thing that I like the most about NLP is that you are primarily limited by your imagination and what you can do with it. If you are a creative person, you will be able to come up with many ideas that I have not explained.
I will explain some of the common uses of NLP that I have found. Some of this may not typically appear in NLP books, but as a lifelong programmer, when I think of NLP, I automatically think about any programmatic work with string, with a string being a sequence of characters. ABCDEFG is a string, for instance. A is a character.
Note
Please don’t bother writing the code for now unless you just want to experiment with some of your own data. The code in this chapter is just to show what is possible and what the code may look like. We will go much deeper into actual code throughout this book.
True/False – Presence/Absence
This may not fit strictly into NLP, but it is very often a part of any text operation, and this also happens in ML used in NLP, where one-hot encoding is used. Here, we are looking strictly for the presence or absence of something. For instance, as we saw earlier in the chapter, I wanted to count the number of times that Adam and Eve appeared in the Bible. I could have similarly written some simple code to determine whether Adam and Eve were in the Bible at all or whether they were in the book of Exodus.
For this example, let’s use this DataFrame that I have set up:

Figure 1.2 – pandas DataFrame containing the entire King James Version text of the Bible
I specifically want to see whether Eve exists as one of the entities in df['entities']. I want to keep the data in a DataFrame, as I have uses for it, so I will just do some pattern matching on the entities field:
check_df['entities'].str.contains('^Eve$')
0 False
1 False
1 False
2 False
3 False
...
31101 False
31101 False
31102 False
31102 False
31102 False
Name: entities, Length: 51702, dtype: bool
Here, I am using what is called a regular expression (regex) to look for an exact match on the word Eve. The ^ symbol means that the E in Eve sits at the very beginning of the string, and $ means that the e sits at the very end of the string. This ensures that there is an entity that is exactly named Eve, with nothing before and after. With regex, you have a lot more flexibility than this, but this is a simple example.
In Python, if you have a series of True and False values, .min() will give you False, and .max() will give you True, and that makes sense as another way of looking at True and False is a 1 and 0, and 1 is greater than 0. There are other ways to do this, but I am going to do it this way. So, to see whether Eve is mentioned even once in the whole Bible, I can do the following:
check_df['entities'].str.contains('^Eve$').max()
True
If I want to see if Adam is in the Bible, I can replace Eve with Adam:
check_df['entities'].str.contains('^Adam$').max()
True
Detecting the presence or absence of something in a piece of text can be useful. For instance, if we want to very quickly get a list of Bible verses that are about Eve, we can do the following:
check_df[check_df['entities'].str.contains('^Eve$')]
This will give us a DataFrame of Bible verses mentioning Eve:

Figure 1.3 – Bible verses containing strict mentions of Eve
If we want to get a list of verses that are about Noah, we can do this:
check_df[check_df['entities'].str.contains('^Noah$')].head(10)
This will give us a DataFrame of Bible verses mentioning Noah:
Figure 1.4 – Bible verses containing strict mentions of Noah
I have added .head(10) to only see the first ten rows. With text, I often find myself wanting to see more than the default five rows.
And if we didn’t want to use the entities field, we could look in the text instead.
df[df['text'].str.contains('Eve')]
This will give us a DataFrame of Bible verses where the text of the verse included a mention of Eve.

Figure 1.5 – Bible verses containing mentions of Eve
That is where this gets a bit messy. I have already done some of the hard work, extracting entities for this dataset, which I will show how to do in a later chapter. When you are dealing with raw text, regex and pattern matching can be a headache, as shown in the preceding figure. I only wanted the verses that contained Eve, but instead, I got matches for words such as even and every. That’s not what I want.
Anyone who works with text data is going to want to learn the basics of regex. Take heart, though. I have been using regex for over twenty years, and I still very frequently have to Google search to get mine working correctly. I’ll revisit regex, but I hope that you can see that it is pretty simple to determine if a word exists in a string. For something more practical, if you had 400,000 scraped tweets and you were only interested in the ones that were about a specific thing, you could easily use the preceding techniques or regex to look for an exact or close match.
Regular expressions (regex)
I briefly explained regex in the previous section, but there is much more that you can use it for than to simply determine the presence or absence of something. For instance, you can also use regex to extract data from text to enrich your datasets. Let’s look at a data science feed that I scrape:

Figure 1.6 – Scraped data science Twitter feed
There’s a lot of value in that text field, but it is difficult to work with in its current form. What if I only want a list of links that are posted every day? What if I want to see the hashtags that are used by the data science community? What if I want to take these tweets and build a social network to analyze who interacts? The first thing we should do is enrich the dataset by extracting things that we want. So, if I wanted to create three new fields that contained lists of hashtags, mentions, and URLs, I could do the following:
df['text'] = df['text'].str.replace('@', ' @')
df['text'] = df['text'].str.replace('#', ' #')
df['text'] = df['text'].str.replace('http', ' http')
df['users'] = df['text'].apply(lambda tweet: [token for token in tweet.split() if token.startswith('@')])
df['tags'] = df['text'].apply(lambda tweet: [token for token in tweet.split() if token.startswith('#')])
df['urls'] = df['text'].apply(lambda tweet: [token for token in tweet.split() if token.startswith('http')])
In the first three lines, I am adding a space behind each mention, hashtag, and URL just to give a little breathing room for splitting. In the next three lines, I am splitting each tweet by space and then applying rules to identify mentions, hashtags, and URLs. In this case, I don’t use fancy logic. Mentions start with @, hashtags start with #, and URLs start with HTTP (to include HTTPS). The result of this code is that I end up with three additional columns, containing lists of users, tags, and URLs.
If I then use explode() on the users, tags, and URLs, I will get a DataFrame where each individual user, tag, and URL has its own row. This is what the DataFrame looks like after explode():

Figure 1.7 – Scraped data science Twitter feed, enriched with users, tags, and URLs
I can then use these new columns to get a list of unique hashtags used:
sorted(df['tags'].dropna().str.lower().unique()) ['#', '#,', '#1', '#1.', '#10', '#10...', '#100daysofcode', '#100daysofcodechallenge', '#100daysofcoding', '#15minutecity', '#16ways16days', '#1bestseller', '#1m_ai_talents_in_10_years!', '#1m_ai_talents_in_10_yrs!', '#1m_ai_talents_in_10yrs', '#1maitalentsin10years', '#1millionaitalentsin10yrs', '#1newrelease', '#2'
Clearly, the regex used in my data enrichment is not perfect, as punctuation should not be included in hashtags. That’s something to fix. Be warned, working with human language is very messy and difficult to get perfect. We just have to be persistent to get exactly what we want.
Let’s see what the unique mentions look like. By unique mentions, I mean the deduplicated individual accounts mentioned in tweets:
sorted(df['users'].dropna().str.lower().unique()) ['@', '@027_7', '@0dust_himanshu', '@0x72657562656e', '@16yashpatel', '@18f', '@1ethanhansen', '@1littlecoder', '@1njection', '@1wojciechnowak', '@20,', '@26th_february_2021', '@29mukesh89', '@2net_software',
That looks a lot better, though @ should not exist alone, the fourth one looks suspicious, and a few of these look like they were mistakenly used as mentions when they should have been used as hashtags. That’s a problem with the tweet text, not the regular expression, most likely, but worth investigating.
I like to lowercase mentions and hashtags so that it is easier to find unique tags. This is often done as preprocessing for NLP.
Finally, let’s get a list of unique URLs mentioned (which can then be used for further scraping):
sorted(df['urls'].dropna().unique()) ['http://t.co/DplZsLjTr4', 'http://t.co/fYzSPkY7Qk', 'http://t.co/uDclS4EI98', 'https://t.co/01IIAL6hut', 'https://t.co/01OwdBe4ym', 'https://t.co/01wDUOpeaH', 'https://t.co/026c3qjvcD', 'https://t.co/02HxdLHPSB', 'https://t.co/02egVns8MC', 'https://t.co/02tIoF63HK', 'https://t.co/030eotd619', 'https://t.co/033LGtQMfF', 'https://t.co/034W5ItqdM', 'https://t.co/037UMOuInk', 'https://t.co/039nG0jyZr'
This looks very clean. How many URLs was I able to extract?
len(sorted(df['urls'].dropna().unique())) 19790
That’s a lot of links. As this is Twitter data, a lot of URLs are often photos, selfies, YouTube links, and other things that may not be too useful to a researcher, but this is my scraped data science feed, which pulls information from dozens of data science related accounts, so many of these URLs likely include exciting news and research.
Regex allows you to extract additional data from your data and use it to enrich your datasets to do easier or further analysis, and if you extract URLs, you can use that as input for additional scraping.
I’m not going to give a long lesson into regex. There are a whole lot of books dedicated to the topic. It is likely that, eventually, you will need to learn how to use regex. For what we are doing in this book, the preceding regex is probably all you will need, as we are using these tools to build social networks that we can analyze. This book isn’t primarily about NLP. We just use some NLP techniques to create or enrich our data, and then we will use network analysis for everything else.
Word counts
Word counts are also useful, especially when we want to compare things against each other. For instance, we already compared the number of times that Adam and Eve were mentioned in the Bible, but what if we want to see the number of times that all entities are mentioned in the Bible? We can do this the simple way, and we can do this the NLP way. I prefer to do things the simple way, where possible, but frequently, the NLP or graph way ends up being the simpler way, so learn everything that you can and decide for yourself.
We will do this the simple way by counting the number of times entities were mentioned. Let’s use the dataset again and just do some aggregation to see who the most mentioned people are in the Bible. Keep in mind we can do this for any feed that we scrape, so long as we have enriched the dataset to contain a list of mentions. But for this demonstration, I’ll use the Bible.
On the third line, I am keeping entities with a name longer than two characters, effectively dropping some junk entities that ended up in the data. I am using this as a filter:
check_df = df.explode('entities')
check_df.dropna(inplace=True) # dropping nulls
check_df = check_df[check_df['entities'].apply(len) > 2] # dropping some trash that snuck in
check_df['entities'] = check_df['entities'].str.lower()
agg_df = check_df[['entities', 'text']].groupby('entities').count()
agg_df.columns = ['count']
agg_df.sort_values('count', ascending=False, inplace=True)
agg_df.head(10)
This is shown in the following DataFrame:

Figure 1.8 – Entity counts across the entire Bible
This looks pretty good. Entities are people, places, and things, and the only oddball in this bunch is the word thou. The reason that snuck in is that in the Bible, often the word thou is capitalized as Thou, which gets tagged as an NNP (Proper Noun) when doing entity recognition and extraction in NLP. However, thou is in reference to You, and so it makes sense. For example, Thou shalt not kill, thou shalt not steal.
If we have the data like this, we can also very easily visualize it for perspective:
agg_df.head(10).plot.barh(figsize=(12, 6), title='Entity Counts by Bible Mentions', legend=False).invert_yaxis()
This will give us a horizontal bar chart of entity counts:
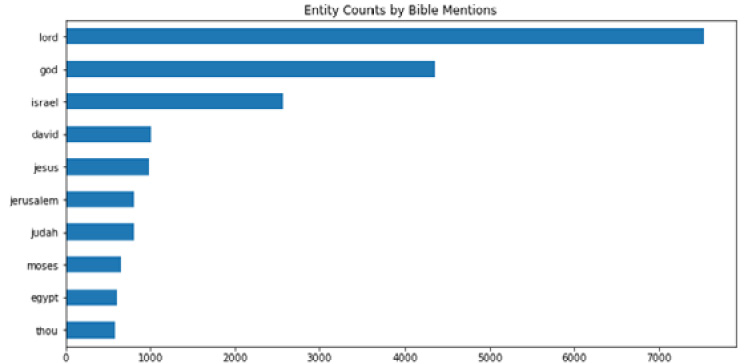
Figure 1.9 – Visualized entity counts across the entire Bible
This is obviously not limited to use on the Bible. If you have any text at all that you are interested in, you can use these techniques to build a deeper understanding. If you want to use these techniques to pursue art, you can. If you want to use these techniques to help fight crime, you can.
Sentiment analysis
This is my favorite technique in all of NLP. I want to know what people are talking about and how they feel about it. This is an often underexplained area of NLP, and if you pay attention to how most people use it, you will see many demonstrations on how to build classifiers that can determine positive or negative sentiment. However, we humans are complicated. We are not just happy or sad. Sometimes, we are neutral. Sometimes we are mostly neutral but more positive than negative. Our feelings are nuanced. One book that I have used a lot for my own education and research into sentiment analysis mentions a study that mapped out human emotions as having primary, secondary, and tertiary emotions (Liu, Sentiment Analysis, 2015, p. 35). Here are a few examples:
|
Primary Emotion |
Secondary Emotion |
Tertiary Emotion |
|
Anger |
Disgust |
Contempt |
|
Anger |
Envy |
Jealousy |
|
Fear |
Horror |
Alarm |
|
Fear |
Nervousness |
Anxiety |
|
Love |
Affection |
Adoration |
|
Love |
Lust |
Desire |
Figure 1.10 – A table of primary, secondary, and tertiary emotions
There are a few primary emotions, there are more secondary emotions, and there are many, many more tertiary emotions. Sentiment analysis can be used to try to classify yes/no for any emotion as long as you have training data.
Sentiment analysis doesn’t have to only be used for detecting emotions. The techniques can also be used for classification, so I don’t feel that sentiment analysis is quite the complete wording, and maybe that is why there are so many demonstrations of people simply detecting positive/negative sentiment from Yelp and Amazon reviews.
I have more interesting uses for sentiment classification. Right now, I use these techniques to detect toxic speech (really abusive language), positive sentiment, negative sentiment, violence, good news, bad news, questions, disinformation research, and network science research. You can use this as intelligent pattern matching, which learns the nuances of how text about a topic is often written about. For instance, if we wanted to catch tweets related to disinformation, we could train a model on text having to do with misinformation, disinformation, and fake news. The model would learn other related terms during training, and it would do a much better and much faster job of catching them than any human could.
Sentiment analysis and text classification advice
Here is some advice before I move on to the next section: for sentiment analysis and text classification, in many cases, you do not need a neural network for something this simple. If you are building a classifier to detect hate speech, a “bag of words” approach will work for preprocessing, and a simple model will work for classification. Always start simple. A neural network may give you a couple of percents better accuracy if you work at it, but it’ll take more time and be less explainable. A linearsvc model can be trained in a split second and often do as well, sometimes even better, and some other simple models and techniques should be attempted as well.
Another piece of advice: experiment with stopword removal, but don’t just remove stopwords because that’s what you have been told. Sometimes it helps, and sometimes it hurts your model. The majority of the time, it might help, but it’s simple enough to experiment.
Also, when building your datasets, you can often get the best results if you do sentiment analysis against sentences rather than large chunks of text. Imagine that we have the following text:
Today, I woke up early, had some coffee, and then I went outside to check on the flowers. The sky was blue, and it was a nice, warm June morning. However, when I got back into the house, I found that a pipe had sprung a leak and flooded the entire kitchen. The rest of the day was garbage. I am so angry right now.
Do you think that the emotions of the first sentence are identical to the emotions of the last sentence? This imaginary story is all over the place, starting very cheerful and positive and ending in disaster and anger. If you classify at the sentence level, you are able to be more precise. However, even this is not perfect.
Today started out perfectly, but everything went to hell and I am so angry right now.
What is the sentiment of that sentence? Is it positive or negative? It’s both. And so, ideally, if you could capture that a sentence has multiple emotions on display, that would be powerful.
Finally, when you build your models, you always have the choice of whether you want to build binary or multiclass language models. For my own uses, and according to research that has resonated with me, it is often easiest to build small models that simply look for the presence of something. So, rather than building a neural network to determine whether the text is positive, negative, or neutral, you could build a model that looks for positive versus other and another one that looks for negative versus other.
This may seem like more work, but I find that it goes much faster, can be done with very simple models, and the models can be chained together to look for an array of different things. For instance, if I wanted to classify political extremism, I could use three models: toxic language, politics, and violence. If a piece of text was classified as positive for toxic language, was political, and was advocating violence, then it is likely that the poster may be showing some dangerous traits. If only toxic language and political sentiment were being displayed, well, that’s common and not usually politically extreme or dangerous. Political discussion is often hostile.
Information extraction
We have already done some information extraction in previous examples, so I will keep this brief. In the previous section, we extracted user mentions, hashtags, and URLs. This was done to enrich the dataset, making further analysis much easier. I added the steps that extract this into my scrapers directly so that I have the lists of users, mentions, and URLs immediately when I download fresh data. This allows me to immediately jump into network analysis or investigate the latest URLs. Basically, if there is information you are looking for, and you come up with a way to repeatedly extract it from text, and you find yourself repeating the steps over and over on different datasets, you should consider adding that functionality to your scrapers.
The most powerful data that is enriching my Twitter datasets are two fields: publisher, and users. Publisher is the account that posted the tweet. Users are the accounts mentioned by the publisher. Each of my feeds has dozens of publishers. With publishers and users, I can build social networks from raw text, which will be explained in this book. It is one of the most useful things I have figured out how to do, and you can use the results to find other interesting accounts to scrape.
Community detection
Community detection is not typically mentioned with regard to NLP, but I do think that it should be, especially when using social media text. For instance, if we know that certain hashtags are used by certain groups of people, we can detect other people that may be affiliated with or are supporters of those groups by the hashtags that they use. It is very easy to use this to your advantage when researching groups of people. Just scrape a bunch of them, see what hashtags they use, then search those hashtags. Mentions can give you hints of other accounts to scrape as well.
Community detection is commonly mentioned in social network analysis, but it can also very easily be done with NLP, and I have used topic modeling and the preceding approach as ways of doing so.
Clustering
Clustering is a technique commonly found in unsupervised learning but also done in network analysis. In clustering, we are looking for things that are similar to other things. There are different approaches for doing this, and even NLP topic modeling can be used as clustering. In unsupervised ML, you can use algorithms such as k-means to find tweets, sentences, or books that are similar to other tweets, sentences, or books. You could do similar with topic modeling, using TruncatedSVD. Or, if you have an actual sociogram (map of a social network), you could look at the connected components to see which nodes are connected or apply k-means against certain network metrics (we will go into this later) to see nodes with similar characteristics.
Advanced uses of NLP
Most of the NLP that you will do on a day-to-day basis will probably fall into one of the simpler uses, but let’s also discuss a few advanced uses. In some cases, what I am describing as advanced uses is really a combination of simpler uses to deliver a more complicated solution. So, let’s discuss some of the more advanced uses, such as chatbots and conversational agents, language modeling, information retrieval, text summarization, topic discovery and modeling, text-to-speech and speech-to-text conversion, MT, and personal assistants.
Chatbots and conversational agents
A chatbot is a program that can hold a conversation with its user. These have existed for years, with the earliest chatbots being created in the 1960s, but they have been steadily improving and are now an effective means of forwarding a user to a more specific form of customer support, for instance. If you go to a website’s support section, you may be presented with a small chatbox popup that’ll say something like, “What can we help you with today?”. You may then type, “I want to pay off my credit card balance.” When the application receives your answer, it’ll be able to use it to determine the correct form of support that you need.
While a chatbot is built to handle human text, a conversational agent can handle voice audio. Siri and Alexa are examples of conversational agents. You can talk to them and ask them questions.
Chatbots and conversational agents are not limited to text, though; we often run into similar switchboards when we call a company with our phones. We will get the same set of questions, either looking for a word answer or numeric input. So, behind the scenes, where voice is involved, there will be a voice-to-text conversion element in place. Applications also need to determine whether someone is asking a question or making a statement, so there is likely text classification involved as well.
Finally, to provide an answer, text summarization could convert search results into a concise statement to return as text or speech to the user to complete the interaction.
Chatbots are not just rudimentary question-and-answer systems, though. I believe that they will be an effective way for us to interact with text. For instance, you could build a chatbot around the book Alice’s Adventures in Wonderland (or the Bible) to give answers to questions specifically about the book. You could build a chatbot from your own private messages and talk to yourself. There’s a lot of room for creativity here.
Language modeling
Language modeling is concerned with predicting the next word given a sequence of words. For instance, what would come after this: “The cow jumped over the ______.” Or this: “Green eggs and _____.” If you go to Google and start typing in the search bar, take note that the next predicted word will show in a drop-down list to speed up your search.
We can see that Google has predicted the next word to be ham but that it is also finding queries that are related to what you have already typed. This looks like a combination of language modeling as well as clustering or topic modeling. They are looking to predict the next word before you even type it, and they are even going a step further to find other queries that are similar to the text you have already typed.
Data scientists are also able to use language modeling as part of the creation of generative models. In 2020, I trained a model on thousands of lines of many Christmas songs and trained it to write Christmas poetry. The results were rough and humorous, as I only spent a couple of days on it, but it was able to take seed text and use it to create entire poems. For instance, seed text could be, “Jingle bells,” and then the model would continuously take previous text and use it to create a poem until it reached the end limits for words and lines. Here is my favorite of the whole batch:
youre the angel and the manger is the king of kings and sing the sea of door to see to be the christmas night is the world and i know i dont want to see the world and much see the world is the sky of the day of the world and the christmas is born and the world is born and the world is born to be the christmas night is the world is born and the world is born to you to you to you to you to you to a little child is born to be the world and the christmas tree is born in the manger and everybody sing fa la la la la la la la la la la la la la la la la la la la la la la la la la la la la la la
I built the generative process to take a random first word from any of the lines of the training data songs. From there, it would create lines of 6 words for a total of 25 lines. I only trained it for 24 hours, as I wanted to quickly get this done in time for Christmas. There are several books on creating generative models, so if you would like to use AI to augment your own creativity, then I highly suggest looking into them. It feels like a collaboration with a model rather than replacing ourselves with a model.
These days, generative text models are becoming quite impressive. ChatGPT – released in November 2022 – has grabbed the attention of so many people with its ability to answer most questions and give realistic-looking answers. The answers are not always correct, so generative models still have a long way to go, but there is now a lot of hype around generative models, and people are considering how they can use them in their own work and lives and what they mean for our future.
Text summarization
Text summarization is pretty much self-explanatory. The goal is to take text as input and return a summary as output. This can be very powerful when you are managing thousands or millions of documents and want to provide a concise sentence about what is in each. It is essentially returning similar to an “abstract” section you would find in an academic article. Many of the details are removed, and only the essence is returned.
However, this is not a perfect art, so be aware that if you use this, the algorithm may throw away important concepts from the text while keeping those that are of less importance. ML is not perfect, so keep an eye on the results.
However, this is not for search so much as it is for returning a short summary. You can use topic modeling and classification to determine document similarity and then use this to summarize the final set of documents.
If you were to take the content of this entire book and feed it to a text summarization algorithm, I would hope that it would capture that the marriage of NLP and network analysis is powerful and approachable by everyone. You do not need to be a genius to work with ML, NLP, or social network analysis. I hope this book will spark your creativity and make you more effective at problem solving and thinking critically about things. There are a lot of important details in this text, but that is the essence.
Topic discovery and modeling
Topic discovery and modeling is very similar to clustering. This is used in Latent Semantic Indexing (LSI), which can be powerful for identifying themes (topics) that exist in text, and it can also be an effective preprocessing step for text classification, allowing models to be trained on context rather than words alone. I mentioned previously, in the Clustering and Community detection subsections, how this could be used to identify subtle groups within communities based on the words and hashtags they place into their account descriptions.
For instance, topic modeling would find similar strings in topics. If you were to do topic modeling on political news and social media posts, you will notice that in topics, like attracts like. Words will be found with other similar words. For instance, 2A may be spelled out as the Second Amendment, USA may be written in its expanded form (United States of America), and so on.
Text-to-speech and speech-to-text conversion
This type of NLP model aims to convert text into speech audio or audio into text transcripts. This is then used as input into classification or conversational agents (chatbots, personal assistants).
What I mean by that is that you can’t just feed audio to a text classifier. Also, it’s difficult to capture context from audio alone without any language analysis components, as people speak in different dialects, in different tones, and so on.
The first step is often transcribing the audio into text and then analyzing the text itself.
MT
Judging by the history of NLP, I think it is safe to say that translating from language A to language B has probably been on the minds of humans for as long as we have had to interact with other humans who use a different language. For instance, there is even a story in the Bible about the Tower of Babel and we lost the ability to understand each other’s words when it was destroyed. MT has so many useful implications, for collaboration, security, and even creativity.
For instance, for collaboration, you need to be able to share knowledge, even if team members do not share the same language. In fact, this is useful anywhere that sharing knowledge is desirable, so you will often find a see translation link in social media posts and comments. Today, MT seems almost perfect, though there are occasionally entertaining mistakes.
For security, you want to know what your enemies are planning. Spying is probably not very useful if you can’t actually understand what your enemies are saying or planning on doing. Translation is a specialized skill and is a long and manual process when humans are involved. MT can greatly speed up analysis, as the other language can be translated into your own.
And for creativity, how fun would it be to convert text from one language into your own created language? This is completely doable.
Due to the importance of MT and text generation, massive neural networks have been trained to handle text generation and MT.
Personal assistants
Most of us are probably aware of personal assistants such as Alexa and Siri, as they have become an integral part of our lives. I suspect we are going to become even more dependent on them, and we will eventually talk to our cars like on the old TV show Knight Rider (broadcast on TV from 1982 to 1986). “Hey car, drive me to the grocery store” will probably be as common as “Hey Alexa, what’s the weather going to be like tomorrow?”
Personal assistants use a combination of several NLP techniques previously mentioned. They may use classification to determine whether your query is a question or a statement. They may then search the internet to find web content most related to the question that you asked. It can then capture the raw text from one or more of the results and then use summarization to build a concise answer. Finally, it will convert text to audio and speak the answer back to the user.
Personal assistants use a combination of several NLP techniques mentioned previously:
- They may use classification to determine whether your query is a question or a statement.
- They may then search the internet to find web content that is most related to the question that you asked.
- They can then capture the raw text from one or more of the results and then use summarization to build a concise answer.
- Finally, they will convert text to audio and speak the answer back to the user.
I am very excited about the future of personal assistants. I would love to have a robot and car that I can talk to. I think that creativity is probably our only limitation for the different types of personal assistants that we can create or for the modules that they use.
How can a beginner get started with NLP?
This book will be of little use if we do not eventually jump into how to use these tools and technologies. The common and advanced uses that I described here are just some of the uses. As you become comfortable with NLP, I want you to constantly consider other uses for NLP that are possibly not being met. For instance, in text classification alone, you can go very deep. You could use text classification to attempt to classify even more difficult concepts, such as sarcasm or empathy, for instance, but let’s not get ahead of ourselves. This is what I want you to do.
Start with a simple idea
Think simply, and only add complexity as needed. Think of something that interests you that you would like to know more about, and then find people who talk about it. If you are interested in photography, find a few Twitter accounts that talk about it. If you are looking to analyze political extremism, find a few Twitter accounts that proudly show their unifying hashtags. If you are interested in peanut allergy research, find a few Twitter accounts of researchers that post their results and articles in their quest to save lives. I mention Twitter over and over because it is a goldmine for investigating how groups of people talk about issues, and people often post links, which can lead to even more scraping. But you could use any social media platform, as long as you can scrape it.
However, start with a very simple idea. What would you like to know about a piece of text (or a lot of Tweets)? What would you like to know about a community of people? Brainstorm. Get a notebook and start writing down every question that comes to mind. Prioritize them. Then you will have a list of questions to seek answers for.
For instance, my research question could be, “What are people saying about Black Lives Matter protests?” Or, we could research something less serious and ask, “What are people saying about the latest Marvel movie?” Personally, I prefer to at least attempt to use data science for good, to make the world a bit safer, so I am not very interested in movie reviews, but others are. We all have our preferences. Study what interests you.
For this demonstration, I will use my scraped data science feed. I have a few starter questions:
- Which accounts post the most frequently every week?
- Which accounts are mentioned the most?
- Which are the primary hashtags used by this community of people?
- What follow-up questions can we think of after answering these questions?
We will only use NLP and simple string operations to answer these questions, as I have not yet begun to explain social network analysis. I am also going to assume that you know your way around Python programming and are familiar with the pandas library. I will cover pandas in more detail in a later chapter, but I will not be giving in-depth training. There are a few great books that cover pandas in depth.
Here is what the raw data for my scraped data science feed looks like:

Figure 1.11 – Scraped and enriched data science Twitter feed
To save time, I have set up the regex steps in the scraper to create columns for users, tags, and URLs. All of this is scraped or generated as a step during automated scraping. This will make it much easier and faster to answer the four questions I posed. So, let’s get to it.
Accounts that post most frequently
The first thing I want to do is see which accounts post the most in total. I will also take a glimpse at which accounts post the least to see whether any of the accounts have dried up since adding them to my scrapers. For this, I will simply take the columns for publisher (the account that posted the tweet) and tweet, do a groupby operation on the publisher, and then take the count:
Check_df = df[['publisher', 'tweet']]
check_df = check_df.groupby('publisher').count()
check_df.sort_values('tweet', ascending=False, inplace=True)
check_df.columns = ['count']
check_df.head(10)
This will display a DataFrame of publishers by tweet count, showing us the most active publishers:

Figure 1.12 – User tweet counts from the data science Twitter feed
That’s awesome. So, if you want to break into data science and you use Twitter, then you should probably follow these accounts.
However, to me, this is of limited use. I really want to see each account’s posting behavior. For this, I will use a pivot table. I will use publisher as the index, created_week as the columns, and run a count aggregation. Here is what the top ten looks like, sorted by the current week:
Check_df = df[['publisher', 'created_week', 'tweet']].copy() pvt_df = pd.pivot_table(check_df, index='publisher', columns='created_week', aggfunc='count').fillna(0) pvt_df = pvt_df['tweet'] pvt_df.sort_values(202129, ascending=False, inplace=True) keep_weeks = pvt_df.columns[-13:-1] # keep the last twelve weeks, but excluding current pvt_df = pvt_df[keep_weeks] pvt_df.head(10)
This creates the following DataFrame:

Figure 1.13 – Pivot table of user tweet counts by week
This looks much more useful, and it is sensitive to the week. This should also be interesting to see as a visualization, to get a feel for the scale:
_= pvt_df.plot.bar(figsize=(13,6), title='Twitter Data Science Accounts – Posts Per Week', legend=False)
We get the following plot:

Figure 1.14 – Bar chart of user tweet counts by week
It’s a bit difficult to see individual weeks when visualized like this. With any visualization, you will want to think about how you can most easily tell the story that you want to tell. As I am mostly interested in visualizing which accounts post the most in total, I will use the results from the first aggregation instead. This is interesting and cool to look at, but it’s not very useful:
_= check_df.plot.bar(figsize=(13,6), title='Twitter Data Science Accounts – Posts Per Week', legend=False)
This code gives us the following graph:

Figure 1.15 – A bar chart of user tweet counts in total
That is much easier to understand.
Accounts mentioned most frequently
Now, I want to see which accounts are mentioned by publishers (the account making the tweet) the most often. This can show people who collaborate, and it can also show other interesting accounts that are worth scraping. For this, I’m just going to use value_counts of the top 20 accounts. I want a fast answer:
Check_df = df[['users']].copy().dropna() check_df['users'] = check_df['users'].str.lower() check_df.value_counts()[0:20] users @dataidols 623 @royalmail 475 @air_lab_muk 231 @makcocis 212 @carbon3it 181 @dictsmakerere 171 @lubomilaj 167 @brittanymsalas 164 @makererenews 158 @vij_scene 151 @nm_aist 145 @makerereu 135 @packtpub 135 @miic_ug 131 @arm 127 @pubpub 124 @deliprao 122 @ucberkeley 115 @mitpress 114 @roydanroy 112 dtype: int64
This looks great. I bet there are some interesting data scientists in this bunch of accounts. I should look into that and consider scraping them and adding them to my data science feed.
Top 10 data science hashtags
Next, I want to see which hashtags are used the most often. The code is going to be very similar, other than I need to run explode() against the tags field in order to create one row for every element of each tweet’s list of hashtags. Let’s do that first. For this, we can simply create the DataFrame, drop nulls, lowercase the tags for uniformity, and then use value_counts() to get what we want:
Check_df = df[['tags']].copy().dropna() check_df['tags'] = check_df['tags'].str.lower() check_df.value_counts()[0:10] tags #datascience 2421 #dsc_article 1597 #machinelearning 929 #ai 761 #wids2021 646 #python 448 #dsfthegreatindoors 404 #covid19 395 #dsc_techtarget 340 #datsciafrica 308 dtype: int64
This looks great. I’m going to visualize the top ten results. However, value_counts() was somehow causing the hashtags to get butchered a bit, so I did a groupby operation against the DataFrame instead:

Figure 1.16 – Hashtag counts from the data science Twitter feed
Let’s finish up this section with a few more related ideas.
Additional questions or action items from simple analysis
In total, this analysis would have taken me about 10 minutes to do if I was not writing a book. The code might seem strange, as you can chain commands together in Python. I prefer to have significant operations on their own line so that the next person who will have to manage my code will not miss something important that was tacked on to the end of a line. However, notebooks are pretty personal, and notebook code is not typically written with perfectly clean code. When investigating data or doing rough visualizations, focus on what you are trying to do. You do not need to write perfect code until you are ready to write the production version. That said, do not throw notebook quality code into production.
Now that we have done the quick analysis, I have some follow-up questions that I should look into answering:
- How many of these accounts are actually data science related and that I am not already scraping?
- Do any of these accounts give me ideas for new feeds? For instance, I have feeds for data science, disinformation research, art, natural sciences, news, political news, politicians, and more. Maybe I should have a photography feed, for instance.
- Would it be worth scraping by keyword for any of the top keywords to harvest more interesting content and accounts?
- Have any of the accounts dried up (no new posts ever)? Which ones? When did they dry up? Why did they dry up?
You try. Do you have any questions you can think of, given this dataset?
Next, let’s try something similar but slightly different, using NLP tools against the book Alice’s Adventures in Wonderland. Specifically, I want to see whether I can take the tf-idf vectors and plot out character appearance by chapter. If you are unfamiliar with it, term frequency-inverse of document frequency (TF-IDF) is an appropriate name because that is exactly the math. I won’t go into the code, but this is what the results look like:

Figure 1.17 – TF-IDF character visualization of Alice’s Adventures in Wonderland by book chapter
By using a stacked bar chart, I can see which characters appear together in the same chapters, as well as their relative importance based on the frequency with that they were named. This is completely automated, and I think it would allow for some very interesting applications, such as a more interactive way of researching various books. In the next chapter, I will introduce social network analysis, and if you were to add that in as well, you could even build the social network of Alice in Wonderland, or any other piece of literature, allowing you to see which characters interact.
In order to perform a tf-idf vectorization, you need to split sentences apart into tokens. Tokenization is NLP 101 stuff, with a token being a word. So, for instance, if we were to tokenize this sentence:
I would end up with a list of the following tokens:
['Today', 'was', 'a', 'wonderful', 'day', '.']
If you have a collection of several sentences, you can then feed it to tf-idf to return the relative importance of each token in a corpus of text. This is often very useful for text classification using simpler models, and it can also be used as input for topic modeling or clustering. However, I have never seen anyone else use it to determine character importance by book chapters, so that’s a creative approach.
This example only scratches the surface of what we can do with NLP and investigates only a few of the questions we could come up with. As you do your own research, I encourage you to keep a paper notebook handy, so that you can write down questions to investigate whenever they come to mind.
Summary
In this chapter, we covered what NLP is, how it has helped me, some common and advanced uses of NLP, and how a beginner can get started.
I hope this chapter gave you a rough idea of what NLP is, what it can be used for, what text analysis looks like, and some resources for more learning. This chapter is in no way the complete picture of NLP. It was difficult to even write the history, as there is just so much to the story and so much that has been forgotten over time.
Thank you for reading. This is my first time writing a book, and this is my first chapter ever written for a book, so this really means a lot to me! I hope you are enjoying this so far, and I hope I gave you an adequate first look into NLP.
Next up: network science and social network analysis!
