

In this topic, we will delve further into evaluating model performance and examine techniques of generalizing models to new data using regularization. Providing the context of a model's performance is extremely important. Our aim is to determine whether our model is performing well compared to trivial or obvious approaches. We do this by creating a baseline model against which machine learning models we train are compared. It is important to stress that all model evaluation metrics are evaluated and reported via the test dataset, since that will give us an understanding of how the model will perform on new data.
A baseline model should be a simple and well-understood procedure, and the performance of this model should be the lowest acceptable performance for any model we build. For classification models, a useful and easy baseline model is to calculate the mode outcome value. For example, in our example, if there are 60% false values, our baseline model would be to predict false for every value, which would give us an accuracy of 60%.
In this exercise, we will put model performance into context. The accuracy we attained from our model seemed good, but we need something to compare it to. Since machine learning model performance is relative, it is important to develop a robust baseline with which to compare models. We are again using the bank dataset, and our target variable is whether or not each customer subscribed to a product. Follow these steps to perform the exercise:
Import all the necessary dependencies and load in the target dataset:
import pandas as pd target = pd.read_csv('data/bank_data_target_e2.csv', index_col=0)Next, we have to calculate the relative proportion of each value of the target variables:
target['y'].value_counts()/target.shape[0]*100
The following figure shows the output of the preceding code:
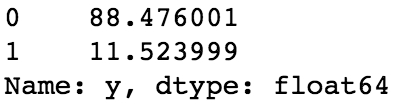
Figure 1.38: Relative proportion of each value
We can see in the dataset that 0 is represented 88.476% of the time – these are the customers that didn't subscribe to any product, and this is our baseline accuracy. Now for the other model evaluation metrics:
from sklearn import metrics y_baseline = pd.Series(data=[0]*target.shape[0]) precision, recall, fscore, _ = metrics.precision_recall_fscore_support(y_pred=y_baseline, y_true=target['y'], average='macro')
Here, we've set the baseline model to predict 0 and have repeated the value to be the same as the number of rows in the test dataset.
Print the final output for precision, recall, and fscore:
print(f'Precision: {precision:.4f}\nRecall:{recall:.4f}\nfscore: {fscore:.4f}')The following figure shows the output of the preceding code:

Figure 1.39: Final output values for precision, recall, and fscore
Now we have a baseline model that we can compare to our previous model, as well as any subsequent models. Now we can tell that while the accuracy of our previous model seemed high, it did not score much better than this baseline model.
We learned earlier in the chapter about overfitting and what it looks like. The hallmark of overfitting is when a model is trained to the training data and performs extremely well, yet performs terribly on test data. One reason for this could be that the model may be relying too heavily on certain features that lead to good performance in the training dataset but do not generalize well to new observations of data or the test dataset. One technique of avoiding this is called regularization. Regularization constrains the values of the coefficients toward zero, which discourages a complex model. There are many different types of regularization techniques. For example, in linear and logistic regression, ridge and lasso regularization are most common. In tree-based models, limiting the maximum depth of the trees acts as regularization.
There are two different types of regularization, namely L1 and L2. This term is either the L2 norm (the sum of the squared values) of the weights, or the L1 norm (the sum of the absolute values) of the weights. Since the l1 regularization parameter acts as a feature selector, it is able to reduce the coefficient of features to zero. We can use the output of this model to observe which features do not contribute much to the performance and remove them entirely if desired. The l2 regularization parameter will not reduce the coefficient of features to zero, so we will observe that they all have non-zero values.
The following code shows how to instantiate the models using these regularization techniques:
model_l1 = LogisticRegressionCV(Cs=Cs, penalty='l1', cv=10, solver='liblinear', random_state=42) model_l2 = LogisticRegressionCV(Cs=Cs, penalty='l2', cv=10, random_state=42)
The following code shows how to fit the models:
model_l1.fit(X_train, y_train['y']) model_l2.fit(X_train, y_train['y'])
The same concepts in lasso and ridge regularization can be applied to ANNs. However, the penalization occurs on the weight matrices rather than the coefficients. Dropout is another form of regularization that's used to prevent overfitting in ANNs. Dropout randomly selects nodes at each iteration and removes them, along with their connections:
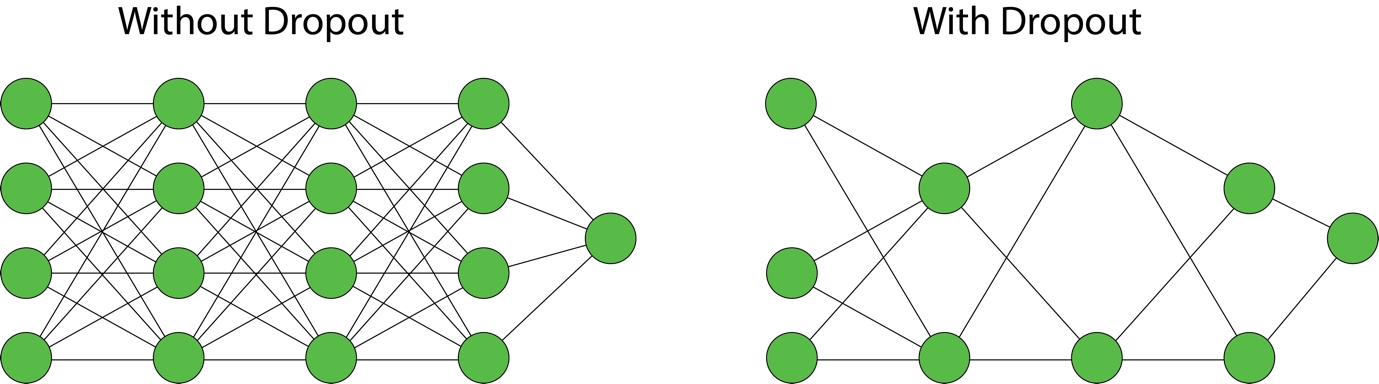
Figure 1.40: Dropout regularization in ANNs
Cross-validation is often used in conjunction with regularization to help tune hyperparameters. Take, for example, the penalization parameter in ridge and lasso regression, or the proportion of nodes to drop out at each iteration using the dropout technique with ANNs. How will you determine which parameter to use? One way is to run models for each value of the regularization parameter and evaluate on the test set; however, using the test set often can introduce bias into the model.
One popular example of cross-validation is called k-fold cross-validation. This technique gives us the ability to test our model on unseen data, while retaining a test set that we will use to test at the end. Using this method, the data is divided into k subsets. In each of the k iterations, k-1 of the subsets are used as training data and the remaining subset is used as a validation set. This is repeated k times until all k subsets have been used as validation sets. By using this technique, there is a significant reduction in bias, since most of the data is used for fitting. There is also a reduction in variation since most of the data is also used for validation. Typically, there are between 5 and 10 folds, and the technique can even be stratified, which is useful when there is a large imbalance of classes.
The following example shows 5-fold cross-validation with 20% held out as a test set. The remaining 80% is separated into 5 folds. 4 of those folds comprise the training data, and the remaining fold is the validation data. This repeated a total of 5 times until every fold has been used once as for validation.
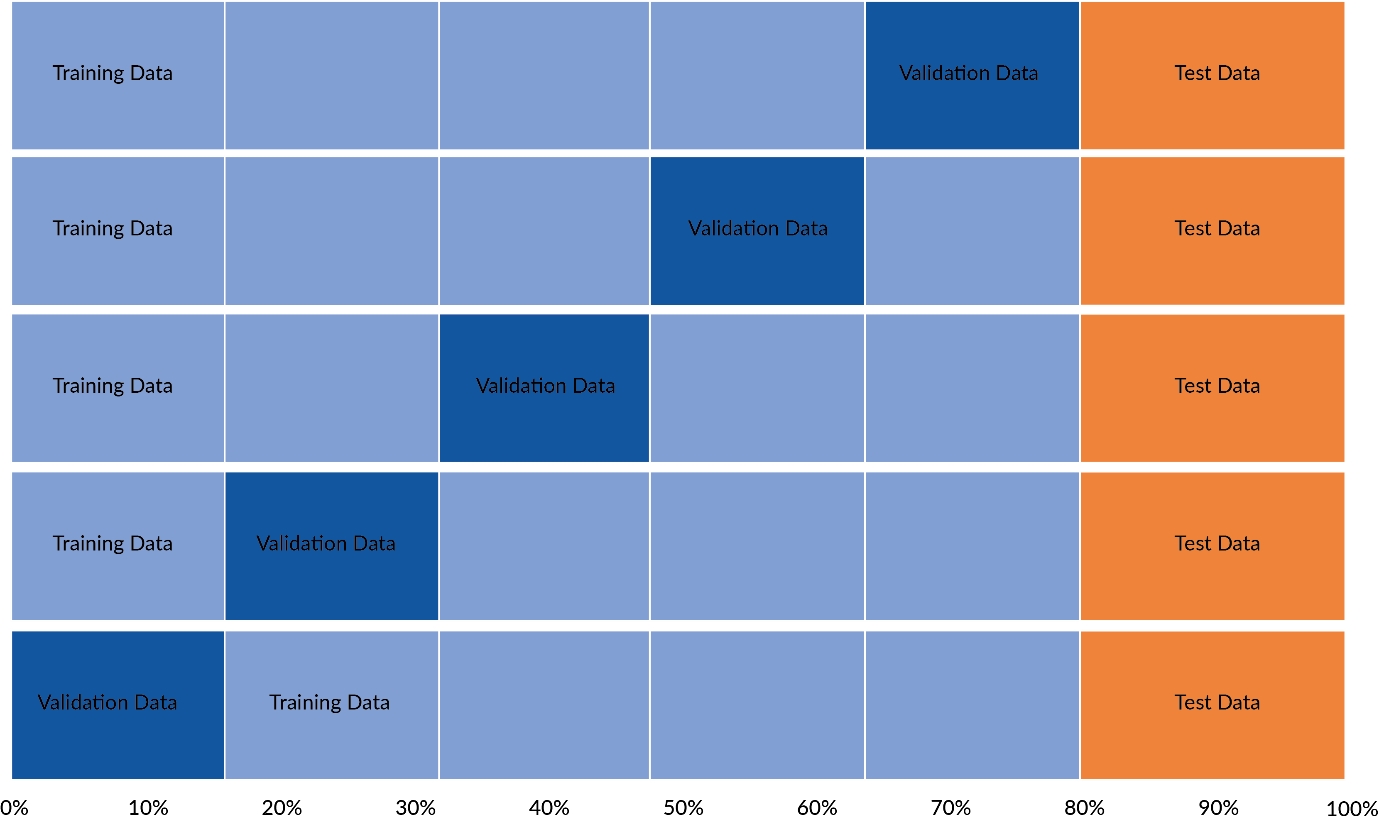
Figure 1.41: A figure demonstrating how 5-fold cross-validation works
In this activity, we will utilize the same logistic regression model from the scikit-learn package. This time, however, we will add regularization to the model and search for the optimum regularization parameter, a process often called hyperparameter tuning. After training the models, we will test the predictions and compare the model evaluation metrics to those produced by the baseline model and the model without regularization.
The steps we will take are as follows:
Load in the feature and target datasets of the bank dataset from 'data/bank_data_feats_e3.csv' and 'data/bank_data_target_e2.csv'.
Create training and testing datasets for each of the feature and target datasets. The training datasets will be used to train on, and the models will be evaluated using the test datasets.
Instantiate a model instance of the LogisticRegressionCV class of scikit-learn's linear_model package.
Fit the model to the training data.
Make predictions of the test dataset using the trained model.
Evaluate the models by comparing how they scored against the true values using the evaluation metrics.