

Two of the most common operations on databases besides retrieving data are inserting and updating rows in a table.
PDI has several steps that allow you to perform these operations. In this recipe you will learn to use the Insert/Update step. Before inserting or updating rows in a table by using this step, it is critical that you know which field or fields in the table uniquely identify a row in the table.
Note
If you don't have a way to uniquely identify the records, you should consider other steps, as explained in the There's more... section.
Assume this situation: You have a file with new employees of Steel Wheels. You have to insert those employees in the database. The file also contains old employees that have changed either the office where they work, or the extension number, or other basic information. You will take the opportunity to update that information as well.
Download the material for the recipe from the book's site. Take a look at the file you will use:
NUMBER, LASTNAME, FIRSTNAME, EXT, OFFICE, REPORTS, TITLE 1188, Firrelli, Julianne,x2174,2,1143, Sales Manager 1619, King, Tom,x103,6,1088,Sales Rep 1810, Lundberg, Anna,x910,2,1143,Sales Rep 1811, Schulz, Chris,x951,2,1143,Sales Rep
Explore the Steel Wheels database, in particular the employees table, so you know what you have before running the transformation. In particular execute these statements:
SELECT EMPLOYEENUMBER ENUM
, concat(FIRSTNAME,' ',LASTNAME) NAME
, EXTENSION EXT
, OFFICECODE OFF
, REPORTSTO REPTO
, JOBTITLE
FROM employees
WHERE EMPLOYEENUMBER IN (1188, 1619, 1810, 1811);
+------+----------------+-------+-----+-------+-----------+
| ENUM | NAME | EXT | OFF | REPTO | JOBTITLE |
+------+----------------+-------+-----+-------+-----------+
| 1188 | Julie Firrelli | x2173 | 2 | 1143 | Sales Rep |
| 1619 | Tom King | x103 | 6 | 1088 | Sales Rep |
+------+----------------+-------+-----+-------+-----------+
2 rows in set (0.00 sec)Create a transformation and use a Text File input step to read the file
employees.txt. Provide the name and location of the file, specify comma as the separator, and fill in the Fields grid.Now, you will do the inserts and updates with an Insert/Update step. So, expand the Output category of steps, look for the Insert/Update step, drag it to the canvas, and create a hop from the Text File input step toward this one.
Double-click the Insert/Update step and select the connection to the Steel Wheels database, or create it if it doesn't exist. As target table type
employees.Fill the grids as shown:

Save and run the transformation.
Explore the employees table. You will see that one employee was updated, two were inserted, and one remained untouched because the file had the same data as the database for that employee:
+------+---------------+-------+-----+-------+--------------+ | ENUM | NAME | EXT | OFF | REPTO | JOBTITLE | +------+---------------+-------+-----+-------+--------------+ | 1188 | Julie Firrelli| x2174 | 2 | 1143 |Sales Manager | | 1619 | Tom King | x103 | 6 | 1088 |Sales Rep | | 1810 | Anna Lundberg | x910 | 2 | 1143 |Sales Rep | | 1811 | Chris Schulz | x951 | 2 | 1143 |Sales Rep | +------+---------------+-------+-----+-------+--------------+ 4 rows in set (0.00 sec)
The Insert/Update step, as its name implies, serves for both inserting or updating rows. For each row in your stream, Kettle looks for a row in the table that matches the condition you put in the upper grid, the grid labeled The key(s) to look up the value(s):. Take for example the last row in your input file:
1811, Schulz, Chris,x951,2,1143,Sales Rep
When this row comes to the Insert/Update step, Kettle looks for a row where EMPLOYEENUMBER equals 1811. It doesn't find one. Consequently, it inserts a row following the directions you put in the lower grid. For this sample row, the equivalent INSERT statement would be:
INSERT INTO employees (EMPLOYEENUMBER, LASTNAME, FIRSTNAME,
EXTENSION, OFFICECODE, REPORTSTO, JOBTITLE)
VALUES (1811, 'Schulz', 'Chris',
'x951', 2, 1143, 'Sales Rep')Now look at the first row:
1188, Firrelli, Julianne,x2174,2,1143, Sales Manager
When Kettle looks for a row with EMPLOYEENUMBER equal to 1188, it finds it. Then, it updates that row according to what you put in the lower grid. It only updates the columns where you put Y under the Update column. For this sample row, the equivalent UPDATE statement would be:
UPDATE employees SET EXTENSION = 'x2174'
, OFFICECODE = 2
, REPORTSTO = 1143
, JOBTITLE = 'Sales Manager'
WHERE EMPLOYEENUMBER = 1188Note that the name of this employee in the file (Julianne) is different from the name in the table (Julie), but, as you put N under the column Update for the field FIRSTNAME, this column was not updated.
Here there are two alternative solutions to this use case.
If you just want to insert records, you shouldn't use the Insert/Update step but the Table Output step. This would be faster because you would be avoiding unnecessary lookup operations. The Table Output step is really simply to configure: Just select the database connection and the table where you want to insert the records. If the names of the fields coming to the Table Output step have the same name as the columns in the table, you are done. If not, you should check the Specify database fields option, and fill the Database fields tab exactly as you filled the lower grid in the Insert/Update step, except that here there is no Update column.
If you just want to update rows, instead of using the Insert/Update step, you should use the Update step. You configure the Update step just as you configure the Insert/Update step, except that here there is no Update column.
The following is an alternative way for inserting and updating rows in a table.
Note
This alternative only works if the columns in the Key field's grid of the Insert/Update step are a unique key in the database.
You may replace the Insert/Update step by a Table Output step and, as the error handling stream coming out of the Table Output step, put an Update step.
Tip
In order to handle the error when creating the hop from the Table Output step towards the Update step, select the Error handling of step option.
Alternatively right-click the Table Output step, select Define error handling..., and configure the Step error handling settings window that shows up. Your transformation would look like this:
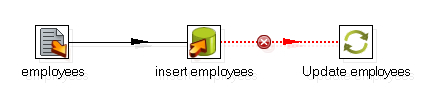
In the Table Output select the table employees, check the Specify database fields option, and fill the Database fields tab just as you filled the lower grid in the Insert/Update step, excepting that here there is no Update column.
In the Update step, select the same table and fill the upper grid—let's call it the Key fields grid—just as you filled the key fields grid in the Insert/Update step. Finally, fill the lower grid with those fields that you want to update, that is, those rows that had Y under the Update column.
In this case, Kettle tries to insert all records coming to the Table Output step. The rows for which the insert fails go to the Update step, and the rows are updated.
If the columns in the Key field's grid of the Insert/Update step are not a unique key in the database, this alternative approach doesn't work. The Table Output would insert all the rows. Those that already existed would be duplicated instead of updated.
This strategy for performing inserts and updates has been proven to be much faster than the use of the Insert/Update step whenever the ratio of updates to inserts is low. In general, for best practices reasons, this is not an advisable solution.
Inserting new rows when a simple primary key has to be generated. If the table where you have to insert data defines a primary key, you should generate it. This recipe explains how to do it when the primary key is a simple sequence.
Inserting new rows when the primary key has to be generated based on stored values. Same as the previous bullet, but in this case the primary key is based on stored values.