

Digital images are composed of a two-dimensional grid of pixels. These pixels can be thought of as the most fundamental and basic building blocks of images. When you view an image, either in its printed form on paper or in its digital format on computer screens, televisions, and mobile phones, what you see is a dense cluster of pixels arranged in a two-dimensional grid of rows and columns. Our eyes are of course not able to differentiate one individual pixel from its neighbor, and hence, images appear continuous to us. But, in reality, every image is composed of thousands and sometimes millions of discrete pixels.
Every single one of these pixels carries some information, and the sum total of all this information makes up the entire image and helps us see the bigger picture. Some of the pixels are light, some are dark. Each of them is colored with a different hue. There are grayscale images, which are commonly known as black and white images. We will avoid the use of the latter phrase because in image processing jargon, black and white refers to something else all together. It does not take an expert to deduce that colored images hold a lot more visual detail than their grayscale counterparts.
So, what pieces of information do these individual, tiny pixels store that enable them to create the images that they are a part of? How does a grayscale image differ from a colored one? Where do the colors come from? How many of them are there? Let's answer all these questions one by one.
There are countless sophisticated instruments that aid us in the process of acquiring images from nature. At the most basic level, they work by capturing light rays as they enter through the aperture of the instrument's lens and fall on a photographic plate. Depending on the orientation, illumination, and other parameters of the photo-capturing device, the amount of light that falls on each spatial coordinate of the film differs. This variation in the intensity of light falling on the film is encoded as pixel values when the image is stored in a digital format. Therefore, the information stored by a pixel is nothing more than a quantitative measure of the intensity of light that illuminated that particular spatial coordinate while the image was being captured. What this essentially means is that any image that you see, when represented digitally, is reduced to a two-dimensional grid of values where each pixel in the image is assigned a numerical value that is directly proportional to the intensity of light falling on that pixel in the natural image.
Now we come to the issue of encoding light intensity in pixel values. If you have studied a programming language before, you might be aware that the range and the type of values that you can store in any data structure are closely linked to the data type. A single bit can represent two values: 0 and 1. Eight bits (also known as a byte) can accommodate 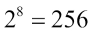 different values. Going further along, an
different values. Going further along, an int (represented using 32 bits in most architectures) data type has the capacity to represent roughly 4.29 billion different entries. Extending the same logic to digital images, the range of values that can be used to represent the pixel intensities depends on the data type we select for storing the image. In the world of image processing, the term color space or color depth is used in place of data type.
The most common and simplest color space for representing images is using 8 bits to represent the value of each pixel. This means that each pixel can have any value between 0 and 255 (inclusive). Images made up of such color spaces are called grayscale images. By convention, 0 represents black, 255 represents white, and each of the other values between 0 and 255 stand for a different shade of gray. The following figure demonstrates such an 8-bit color space. As we move from left to right in the following figure, the grayscale values in the image gradually change from 0 to 255:

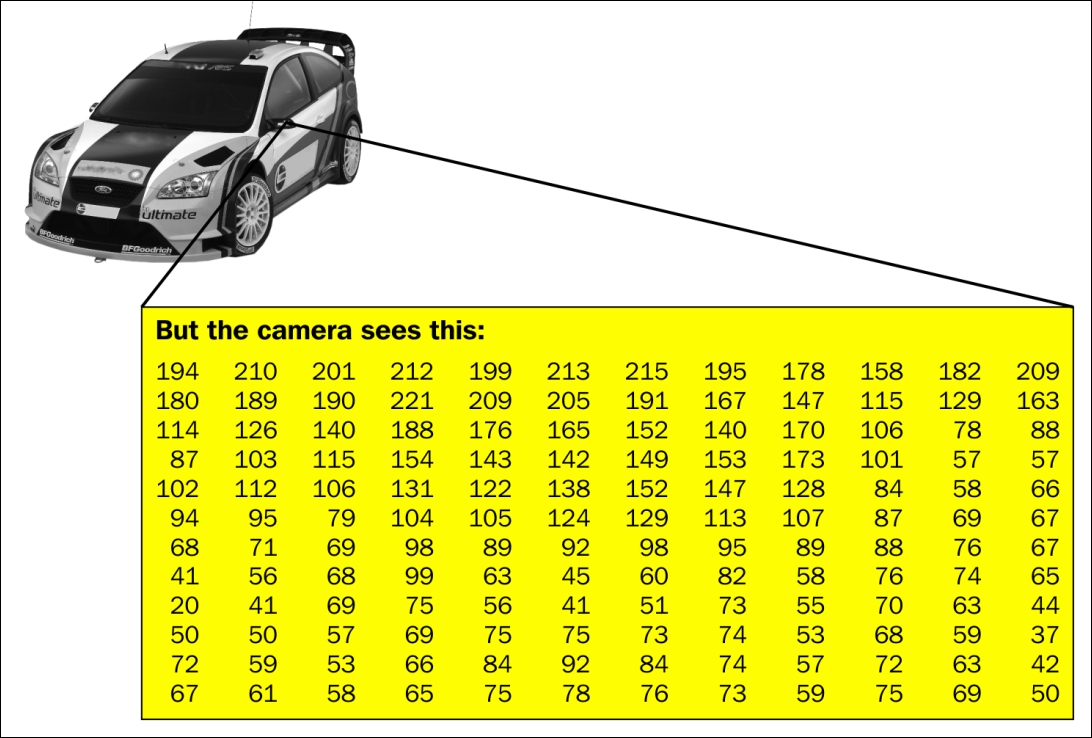
So, if we have a grayscale image, such as the following one, then to a digital medium, it is merely a matrix of values-where each element of the matrix is a grayscale value between 0 (black) to 255 (white). This grid of pixel intensity values is represented for a tiny sub-section of the image (a portion of one of the wing mirrors of the car).
We have seen that using 8 bits is sufficient to represent grayscale images in digital media. But how do we represent colors? This brings us to the concept of color channels. A majority of the images that you come across are colored as opposed to grayscale. In the case of the image we just saw, each pixel is associated with a single intensity value (between 0 and 255). For color images, each pixel has three values or components: the red (R), green (G), and blue (B) components. It is a well-known fact that all possible colors can be represented as a combination of the R, G, and B components, and hence, the triplet of intensity values at each pixel are sufficient to represent the entire spectrum of colors in the image. Also, note that each of the three R, G, and B values at every pixel are stored using 8 bits, which makes it 8 x 3 = 24 bits per pixel. This means that the color space now increases to more than 16 million colors from a mere 256. This is the reason color images store much more information than their grayscale counterparts.
Conceptually, the color image is not treated as having a triplet of intensity values at each pixel. Rather, a more convenient form of representation is adopted. The image is said to possess three independent color channels: the R, G, and B channels. Now, since we are using 8 bits per pixel per channel, each of the three channels are grayscale images in themselves!