

The default evaluation strategy in Haskell is lazy, which intuitively means that evaluation of values is deferred until the value is needed. To see lazy evaluation in action, we can fire up GHCi and use the :sprint command to inspect only the evaluated parts of a value. Consider the following GHCi session:
> let xs = enumFromTo 1 5 :: [Int] > :sprint xs xs = _ > xs !! 2 3 > :sprint xs xs = 1 : 2 : 3 : _
Tip
The code bundle for the book is also hosted on GitHub at https://github.com/PacktPublishing/Haskell-High-Performance-Programming. We also have other code bundles from our rich catalog of books and videos available at https://github.com/PacktPublishing/. Check them out!
Underscores in the output of :sprint stand for unevaluated values. The enumFromTo function builds a linked list lazily. At first, xs is only an unevaluated thunk. Thunks are in a way pointers to some calculation that is performed when the value is needed. The preceding example illustrates this: after we have asked for the third element of the list, the list has been evaluated up to the third element. Note also how pure values are implicitly shared; by evaluating the third element after binding the list to a variable, the original list was evaluated up to the third element. It will remain evaluated as such in memory until we destroy the last reference to the list head.
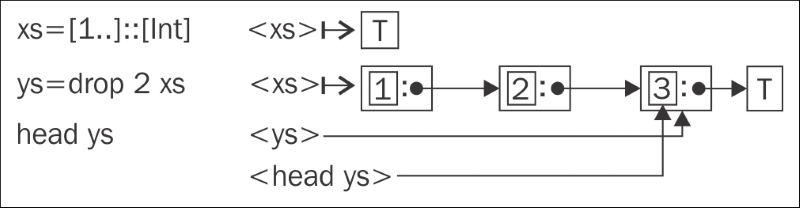
The preceding figure is a graphical representation of how a list is stored in memory. A T stands for a thunk; simple arrows represent pointers.
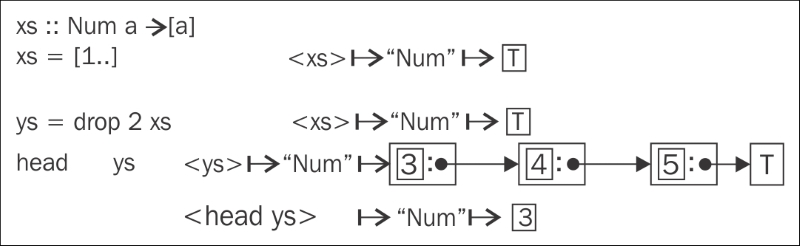
The preceding scenario is otherwise identical to the previous one, but now the list is polymorphic. Polymorphic values are simply functions with implicit parameters that provide the required operations when the type is specialized.
Note
Be careful with :sprint and ad hoc polymorphic values! For example, xs' = enumFromTo 1 5 is by default given the type Num a => [a]. To evaluate such an expression, the type for a must be filled in, meaning that in :sprint xs', the value xs' is different from its first definition. Fully polymorphic values such as xs'' = [undefined, undefined] are okay.
A shared value can be either a performance essential or an ugly space leak. Consider the following seemingly similar scenarios (run with ghci +RTS -M20m to not throttle your computer):
> Data.List.foldl' (+) 0 [1..10^6] 500000500000 > let xs = [1..10^6] :: [Int] > Data.List.foldl' (+) 0 xs <interactive>: Heap exhausted;
So what happened? By just assigning the list to a variable, we exhausted the heap of a calculation that worked just fine previously. In the first calculation, the list could be garbage-collected as we folded over it. But in the second scenario, we kept a reference to the head of the linked list. Then the calculation blows up, because the elements cannot be garbage-collected due to the reference to xs.
Notice that in the previous example we used a strict variant of left-fold called foldl' from Data.List and not the foldl exported from Prelude. Why couldn't we have just as well used the latter? After all, we are only asking for a single numerical value and, given lazy evaluation, we shouldn't be doing anything unnecessary. But we can see that this is not the case (again with ghci +RTS -M20m):
> Prelude.foldl (+) 0 [1..10^6] <interactive>: Heap exhausted;
To understand the underlying issue here, let's step away from the fold abstraction for a moment and instead write our own sum function:
mySum :: [Int] -> Int mySum [] = 0 mySum (x:xs) = x + mySum xs
By testing it, we can confirm that mySum too exhausts the heap:
> :load sums.hs > mySum [1..10^6] <interactive>: Heap exhausted;
Because mySum is a pure function, we can expand its evaluation by hand as follows:
mySum [1..100]
= 1 + mySum [2..100]
= 1 + (2 + mySum [2..100])
= 1 + (2 + (3 + mySum [2..100]))
= ...
= 1 + (2 + (... + mySum [100]))
= 1 + (2 + (... + (100 + 0)))From the expanded form we can see that we build up a huge sum chain and then start reducing it, starting from the very last element on the list. This means that we have all the elements of the list simultaneously in memory. From this observation, the obvious thing we could try is to evaluate the intermediate sum at each step. We could define a mySum2 which does just this:
mySum2 :: Int -> [Int] -> Int mySum2 s [] = s mySum2 s (x:xs) = let s' = s + x in mySum2 s' xs
But to our disappointment mySum2 blows up too! Let's see how it expands:
mySum2 0 [1..100]
= let s1 = 0 + 1 in mySum2 s1 [2..100]
= let s1 = 0 + 1
s2 = s1 + 2
in mySum2 s2 [2..100]
...
= let s1 = 0 + 1
...
s100 = s99 + 100
in mySum2 s100 []
= s100
= s99 + 100
= (s89 + 99) + 100
...
= ((1 + 2) + ... ) + 100Oops! We still build up a huge sum chain. It may not be immediately clear that this is happening. One could perhaps expect that 1 + 2 would be evaluated immediately as 3 as it is in strict languages. But in Haskell, this evaluation does not take place, as we can confirm with :sprint:
> let x = 1 + 2 :: Int > :sprint x x = _
Note that our mySum is a special case of foldr and mySum2 corresponds to foldl.
The problem in our mySum2 function was too much laziness. We built up a huge chain of numbers in memory only to immediately consume them in their original order. The straightforward solution then is to decrease laziness: if we could force the evaluation of the intermediate sums before moving on to the next element, our function would consume the list immediately. We can do this with a system function, seq:
mySum2' :: [Int] -> Int -> Int
mySum2' [] s = s
mySum2' (x:xs) s = let s' = s + x
in seq s' (mySum2' xs s')This version won't blow up no matter how big a list you give it. Speaking very roughly, the seq function returns its second argument and ties the evaluation of its first argument to the evaluation of the second. In seq a b, the value of a is always evaluated before b. However, the notion of evaluation here is a bit ambiguous, as we will see soon.
When we evaluate a Haskell value, we mean one of two things:
Consider the following GHCi session:
> let t = const (Just "a") () :: Maybe String > :sprint t t = _ > t `seq` () > :sprint t t = Just _
Even though we seq the value of t, it was only evaluated up to the Just constructor. The list of characters inside was not touched at all. When deciding whether or not a seq is necessary, it is crucial to understand WHNF and your data constructors. You should take special care of accumulators, like those in the intermediate sums in the mySum* functions. Because the actual value of the accumulator is often used only after the iterator has finished, it is very easy to accidentally build long chains of unevaluated thunks.
Now going back to folds, we recall that both foldl and foldr failed miserably, while (+) . foldl' instead did the right thing. In fact, if you just turn on optimizations in GHC then foldl (+) 0 will be optimized into a tight constant-space loop. This is the mechanism behind why we can get away with Prelude.sum, which is defined as foldl (+) 0.
What do we then have the foldr for? Let's look at the evaluation of foldr f a xs:
foldr f a [x1,x2,x3,x4,...]
= f x1 (foldr f a [x2,x3,x4,...])
= f x1 (f x2 (foldr f a [x3,x4,...]))
= f x1 (f x2 (f x3 (foldr f a [x4,...])))
…Note that, if the operator f isn't strict in its second argument, then foldr does not build up chains of unevaluated thunks. For example, let's consider foldr (:) [] [1..5]. Because (:) is just a data constructor, it is for sure lazy in its second (and first) argument. That fold then simply expands to 1 : (2 : (3 : ...)), so it is the identity function for lists.
Monadic bind (>>) for the IO monad is another example of a function that is lazy in its second argument:
foldr (>>) (return ()) [putStrLn "Hello", putStrLn "World!"]
For those monads whose actions do not depend on later actions, (that is, printing "Hello" is independent from printing "World!" in the IO monad), bind is non-strict in its second argument. On the other hand, the list monad is an example where bind is generally non-strict in its second argument. (Bind for lists is strict unless the first argument is the empty list.)
To sum up, use a left-fold when you need an accumulator function that is strict in both its operands. Most of the time, though, a right-fold is the best option. And with infinite lists, right-fold is the only option.