

Now that we know which function we have to optimize, we can use the line_profiler module that provides information on how time is spent in a line-by-line fashion. This is very useful in situations where it's difficult to determine which statements are costly. The line_profiler module is a third-party module that is available on the Python Package Index and can be installed by following the instructions at https://github.com/rkern/line_profiler.
In order to use line_profiler, we need to apply a @profile decorator to the functions we intend to monitor. Note that you don't have to import the profile function from another module as it gets injected in the global namespace when running the kernprof.py profiling script. To produce profiling output for our program, we need to add the @profile decorator to the evolve function:
@profile
def evolve(self, dt):
# code
The kernprof.py script will produce an output file and will print the result of the profiling on the standard output. We should run the script with two options:
- -l to use the line_profiler function
- -v to immediately print the results on screen
The usage of kernprof.py is illustrated in the following line of code:
$ kernprof.py -l -v simul.py
It is also possible to run the profiler in an IPython shell for interactive editing. You should first load the line_profiler extension that will provide the lprun magic command. Using that command, you can avoid adding the @profile decorator:
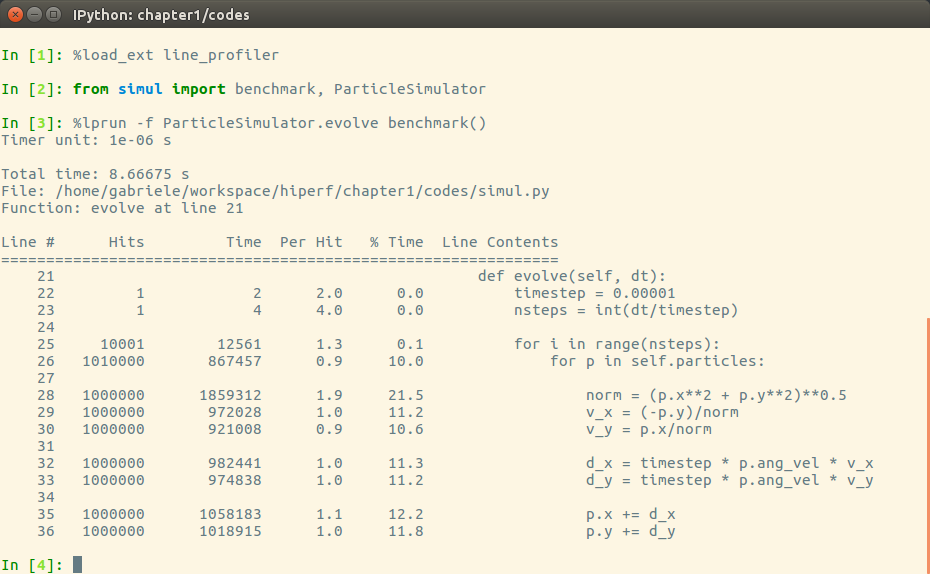
The output is quite intuitive and is divided into six columns:
- Line #: The number of the line that was run
- Hits: The number of times that line was run
- Time: The execution time of the line in microseconds (Time)
- Per Hit: Time/hits
- % Time: Fraction of the total time spent executing that line
- Line Contents: The content of the line
By looking at the percentage column, we can get a pretty good idea of where the time is spent. In this case, there are a few statements in the for loop body with a cost of around 10-20 percent each.