

In this chapter, we will take a look at Git's data model. We will learn how Git references its objects and how the history is recorded. We will learn how to navigate the history, from finding certain text snippets in commit messages, to the introducing a particular string in the code.
The data model of Git is different from other common version control systems (VCSs) in the way Git handles its data. Traditionally, a VCS will store its data as an initial file, followed by a list of patches for each new version of the file:
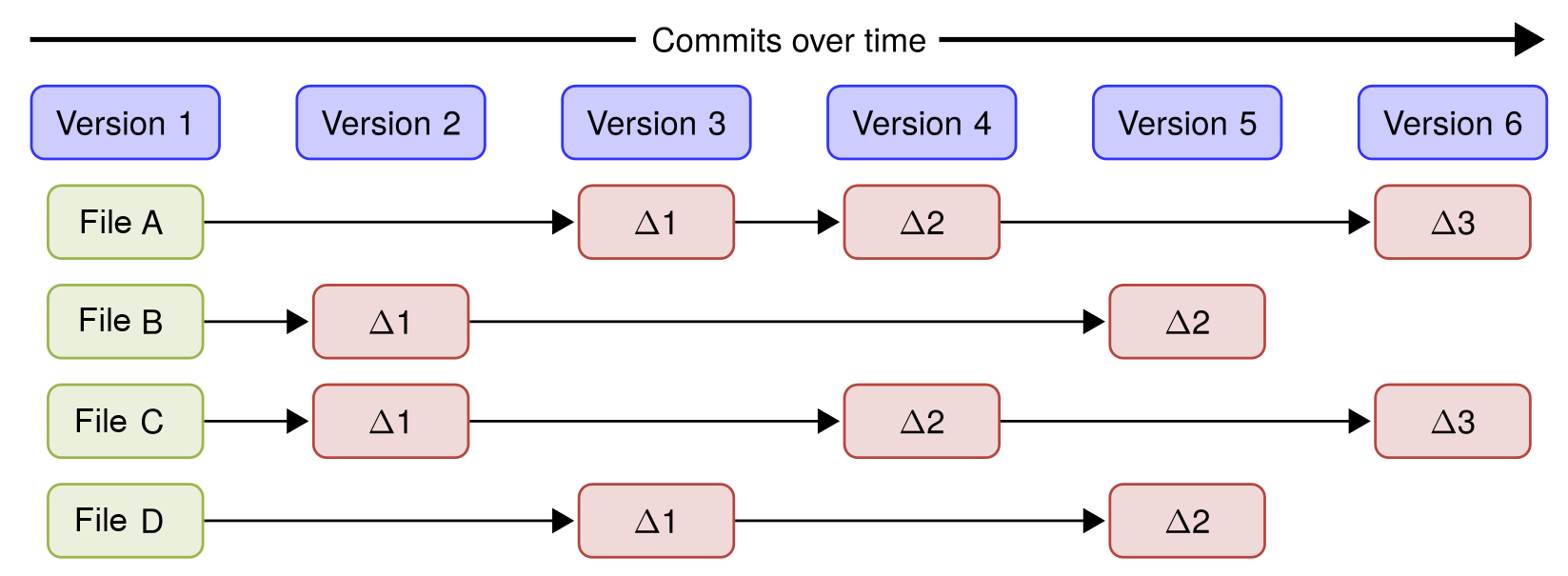
Git is different: Instead of the regular file and patches list, Git records a snapshot of all the files tracked by Git and their paths relative to the repository root—that is, the files tracked by Git in the filesystem tree. Each commit in Git records the full tree state. If a file does not change between commits, Git will not store the file again. Instead, Git stores a link to the file. This is shown in the diagram below where you see how the files will be after every commit/version.
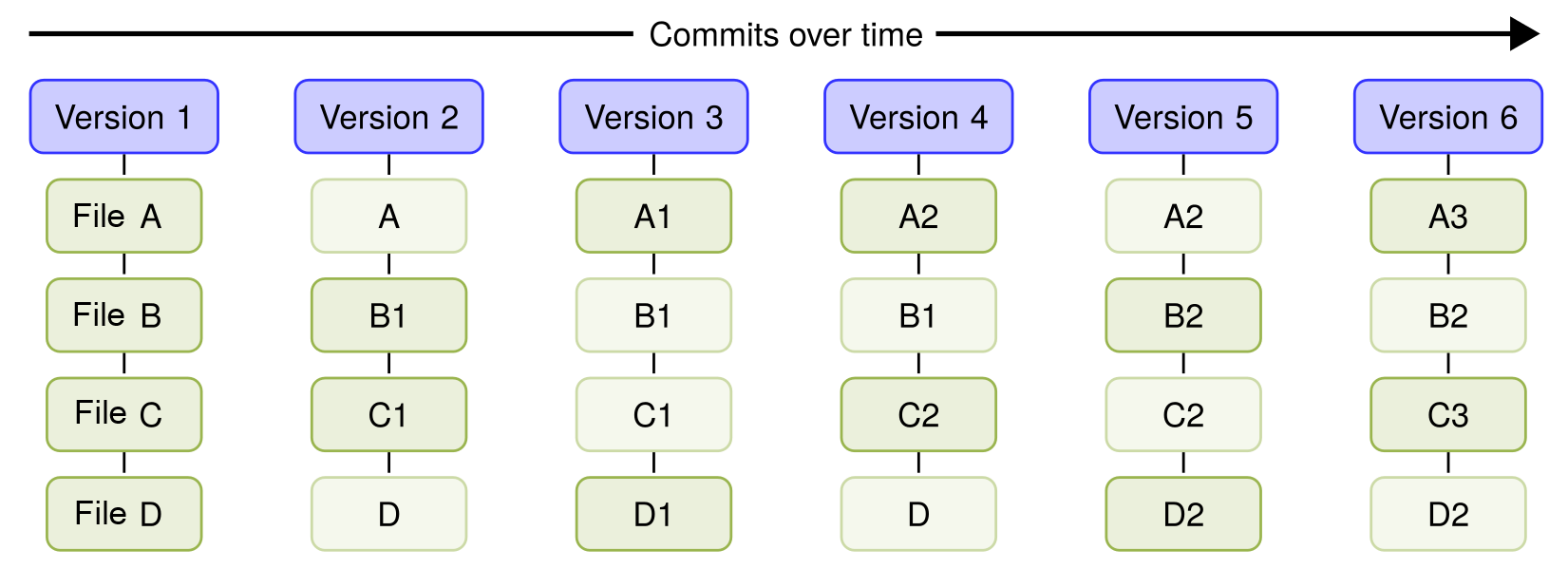
This is what makes Git different from most other VCSs, and, in the following chapters, we will explore some of the benefits of this powerful model.
The way Git references files and directories is directly built into the data model. In short, the Git data model can be summarized as shown in the following diagram:
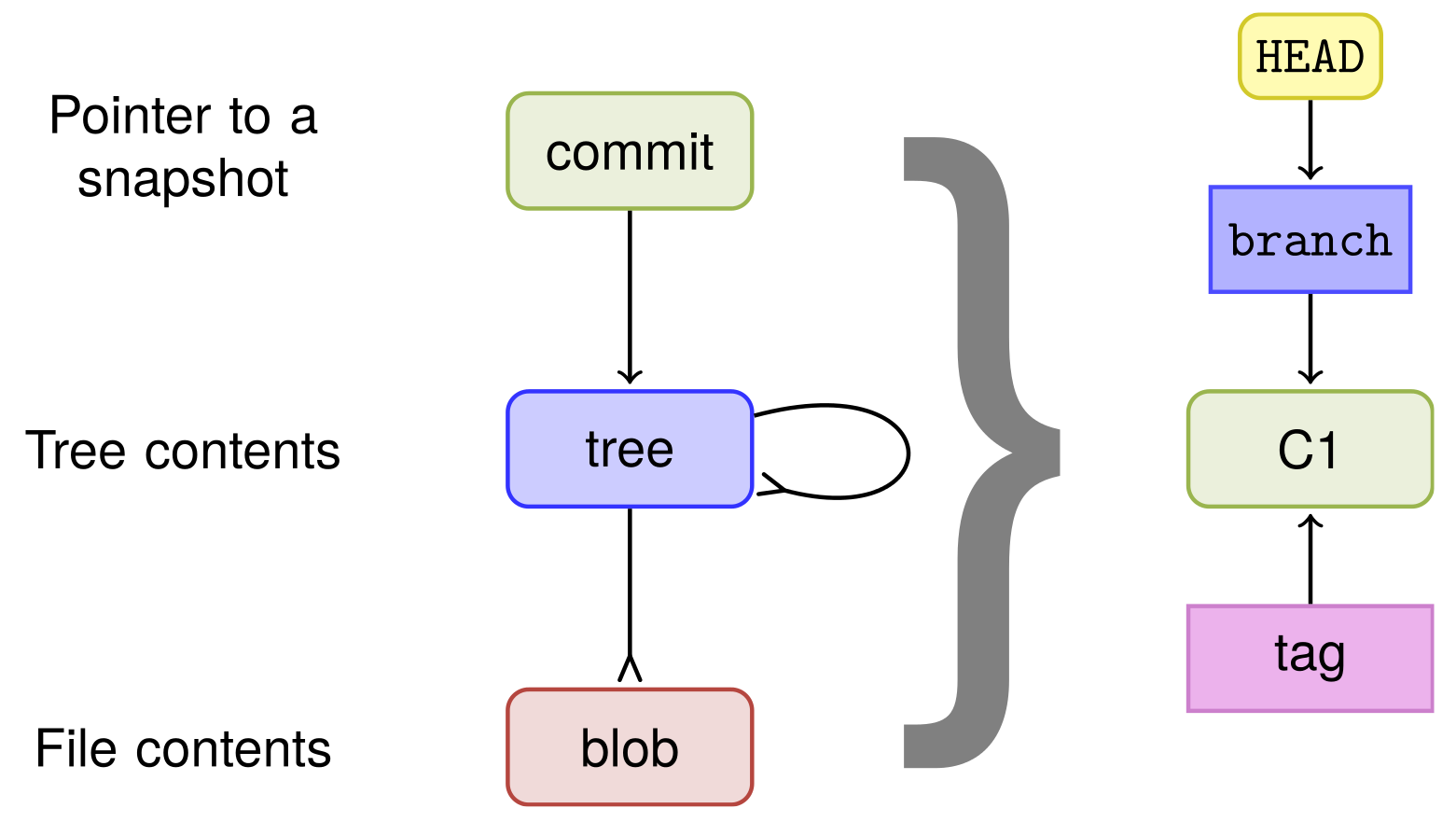
The commit object points to the root tree. The root tree points to subtrees and files.
Branches and tags point to a commit object and the HEAD object points to the branch that is currently checked out. So, for every commit, the full tree state and snapshot are identified by the root tree.