

This section covers what Chef is, what you can do with it, and why it's indispensable for anyone who manages more than one server. We will discuss the major components of Chef, the services that it runs, the terminology and concepts, why it exists, and how it works.
Managing even just a few servers can be a daunting task. Keeping a handful of servers provisioned, updated, and patched can be a full-time job for one person. As an application or organization grows, deploying and configuring servers may sometimes occur on a daily basis. One of the most important roles of a system administrator is being able to keep systems up and running and to consistently make changes across a group of systems. Historically, this requires either lots of manual labor or some very clever shell scripting to automate as much of the process as possible. This is where the concept of a "development-operations" (sometimes shortened as "devops") specialist arose.
By modeling infrastructure, Chef makes it much easier to manage those systems in a central location using a combination of recipes and configuration settings that are applied in a consistent manner.
A common task for a modern system administrator involves maintaining infrastructure for a multi-tiered web application. Assuming a fairly typical web application stack, we can very easily find ourselves providing infrastructure for the following set of services:
Apache Web application server
MySQL Database server
Job processing server
Each role is composed of a collection of specific packages, configuration settings, network settings, firewall rules, user accounts, services, and so on that are required to provide its service within the infrastructure.
These packages and their configurations need to be installed on to one or more servers in order for them to run. Due to budget constraints (everyone works in a startup, right?) the application is being deployed to only one or two servers in the initial stage of production deployment. This is not a large undertaking for a system administrator to manage by hand. However, as the customer base grows, that administrator needs to be able to provision new servers to play one or more particular roles within the environment in order to keep up with growth.
Add to this the fact that each service will be configured differently for a given deployment environment (that is, staging, production, performance testing, and so on) and suddenly you have more than a handful of configurations to juggle. Managing this type of infrastructure is exactly the kind of problem we can solve with Chef.
Before we can tackle this problem, we need to learn some more about the basics of Chef in order to see how all the parts fit together and be able to understand what each component does. Let's learn a little about the concepts and terminology and then take a look at how Chef can help us to solve this scenario.
The Chef environment is comprised of a number of different components working together to provide you the tools to manage your infrastructure. This section discusses the various components and concepts that work together to make up Chef.
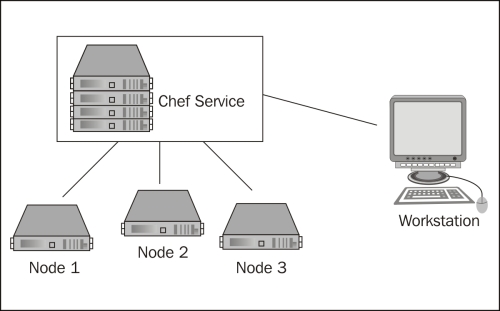
Chef is composed of two primary components, the client that is requesting configuration data to be applied, and the service that provides the configuration. In addition, any client that is used by an administrator to manage data (upload cookbooks, edit data bags, and so on), is referred to as a workstation but is just a client that runs tools, such as shef and knife.
Node: A node is a client that applies roles and recipes, as described by the administrator in the chef service. These are the consumers of the configuration, the elements of your infrastructure such as a server that you are setting up. They can be physical or virtual machines and can run Linux, Windows, or technically any other system that is capable of running Ruby (some systems may not be supported out of the box by Chef). Nodes primarily interact with the Chef service using the
chef-clientcommand-line tool which is responsible for fetching the node's run list and executing it to configure the system.Chef Service: The chef service is composed of several components: a web interface, an API server, Solr for searching configurations, CouchDB for storing data, and RabbitMQ to provide a communications bus between the different processes. This is where the clients (nodes) connect to determine what roles and recipes to apply, and an administrator logs in to build configurations.
As with any other tool or system, there are new concepts and terminologies to be learned when discussing the technology. Chef is no different and for now we will start with a handful of useful terms to get started quickly:
Recipe: A recipe is, as the name implies, a collection of instructions (written in Ruby) and configuration data that achieves a goal. This goal may be to install a particular package, configure a firewall, provision users, and so on. Recipes rely on their custom logic written by the author combined with node-specific and role-specific attributes, data bags and Chef's built-in data searching abilities to be flexible, and generate reproducible results.
Cookbook: A cookbook is a container that holds one or more recipes, templates, configuration settings, and metadata that work together to provide a package or perform an actionable item such as installing PostgreSQL or managing an internal server's connectivity.
Attributes: Attributes are configuration data that is used by recipes either to provide some default settings for a recipe or to override default settings. Attributes can be associated with a specific node or role in the system.
Role: A role is a user-defined collection of recipes and configuration values that describe some sort of common configuration. For example, you might declare a basic "MySQL Server" role that declares that the MySQL server recipe should be run and should have some specific configuration such as which password to use for the root user and what IP addresses to bind to.
Run list: A run list is a combined list of recipes to be applied to a given node in a certain order. A run list can comprise of zero or more roles or recipes, and order is important as the run list's items are executed in the order specified. Therefore, if one recipe is dependent upon the execution of another, you need to ensure that they run in the correct order.
Resource: A resource is, at its core, a unit of work. There are numerous types of resources to be used in a recipe but some of the more commonly used ones would be
packageandservice. Chef tries to be as cross-platform friendly as possible and keeps the implementation details of a resource separate in a provider.Provider: A provider is a concrete implementation of a resource. For example, package is a resource that has an implementation for RPM-based systems that use
yumwhich is different from Debian-based systems that useapt. Even though they have different implementations, they still provide the same type of service, installing a package. Most providers offer implementation-specific resources as well as generic resources. If you use the generic resource provider (that is, package), Chef will use node-specific information, such as the distribution name, to determine which provider to execute. Optionally, you can explicitly use an implementation-specific resource such asredhat_packageif you need to.Data bags: In addition to storing configuration data with a node or a role, Chef has the notion of infrastructure-wide data storage. This data is accessible to any recipe through the data bags interface. Information about users, groups, firewall rules, internal IP address lists, software versions, and other data can be stored here. Data bags contain data about your infrastructure as a whole and are a good way to store any information your recipes need about system-wide configuration.
Environments: Environments allow you to control groups of systems with different configurations. A very common use for environments is to manage multiple instances of the same infrastructure for an application's life-cycle where a development team needs to have a staging and a production environment in which the nodes have the same roles applied to them (database server, application server, job queue server) but unique configuration data such as firewalls, IP addresses, or other environment-specific data.
Now that we're more familiar with some of the terms that Chef uses, let's take a look at how we would organize and model the infrastructure from our case study using Chef.
For this high-level overview, we will assume that that we have an account with a popular Cloud Server hosting company, that the network and operating systems are installed and operational, that we have a functional and configured Chef service and clients (these last two points will be described in detail in the Installation section), and that we have two servers where our configuration looks something like the setup in the following diagram:
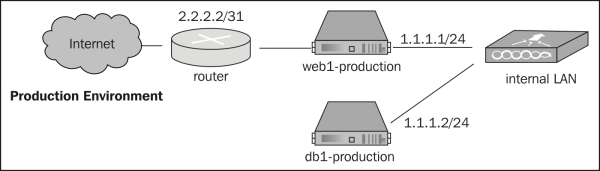
In our hypothetical system, each service can be mapped to a specific role in Chef. To model the infrastructure described, we will have a minimum of two nodes—web1 and db1—and three roles—Apache web server, MySQL database server, and job processing server.
When using Chef to configure infrastructure, we need to analyze our infrastructure and determine how to decompose it into the various building blocks that Chef provides us with in order to provision and configure systems using Chef.
Roles know nothing about the servers we have, they should only know about the software and configuration that is required of them. Roles are, at their core, a run list and a set of attributes that, when combined, work together to model a specific set of functionality (that is, database server or web server). The system administrator, via the Chef console, then assigns a role to the node(s) that it is to be applied to.
A typical web application stack might look something like this:
Apache web server role
Apache HTTP server
PHP 5.x
Memcached and corresponding PHP extension
MySQL client libraries and corresponding PHP extension
Open TCP ports: 80 for HTTP, 443 for HTTPS and 22 for SSH
Open access to internal LAN
MySQL database server role
MySQL 5.x server
Open access to internal LAN
Database backup software to backup data to Amazon Glacier
Job processing server role
Gearman server daemon
PHP Gearman library
Supervisord to manage worker processes
Again, notice that these roles have no specific system configuration. Instead, they are blueprints of what packages we need to install and what ports need to be open. In order for these role definitions to be as reusable as possible, we write our recipes to be flexible and to use node-specific and role-specific attributes or data from our data bags to provide the information about which physical interfaces or IP ranges to open up or interact with.
In order to define these roles, however, Chef needs to have recipes available that these roles are composed of. These recipes define a set of instructions that tell the client how to make sure that the correct packages are installed, what commands to execute in order to open up the firewall, which ports to open, and so on. Like any good cook, Chef has a wide array of cookbooks at its disposal each of which contains recipes relevant to that particular set of functionality. These cookbooks can either be developed by the system administrator or downloaded from a variety of places such as GitHub, Bitbucket, or from a collection of cookbooks maintained by Opscode. We will discuss in later sections how to download and get started with some simple recipes and then further discuss how to develop and distribute our own recipes.
In order to apply a configuration to a node it must be configured to use with Chef, which we will cover in detail in the Installation section. However, once a node is registered with the Chef service, we can set node-specific attributes, assign roles, and then apply our run lists to it. Given our example, we might want to bootstrap and register two servers:
Web1: Ubuntu Linux 12.04
DB1: Ubuntu Linux 11.10
Once they are bootstrapped and registered with the Chef service, we can then configure which roles are to be applied to which nodes, giving us a configuration that might look like the following:
Web1
Apache web server role
Background job server role
DB1
MySQL database server role
As we have learned, Chef also supports applying roles to servers in different environments. Taking our current example one step further, we can apply the same general setup to both a production and a staging environment:
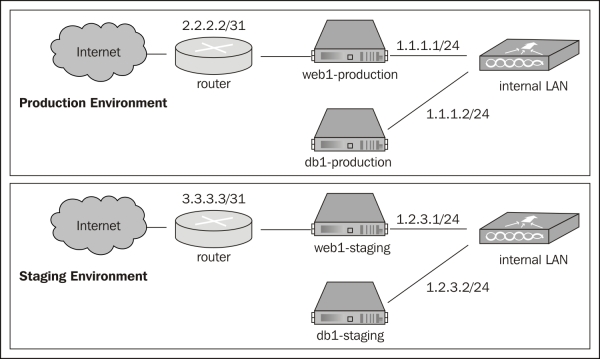
Each environment has a very similar setup but a different set of IP addresses. Using Chef, we can take our system one step further by setting up environments and applying our roles to four nodes now (web1-production, db1-production, web1-staging, db1-staging) and if we update our roles or any recipes for those roles, they will be applied to all our systems in a consistent manner.
Now that we've learned about the basic components and terminologies that Chef uses and dissected our infrastructure a bit, we can conclude the following:
An infrastructure can be decomposed into the various roles that systems play within that infrastructure
Roles are composed of recipes that describe action items such as installing packages or configuring system resources (firewalls, user accounts, and so on)
Roles, when applied to a node, add to the run list that is specific to the node that they are being applied to
That run list is compiled by the Chef service and executed on the node when the Chef Client is run
Next, we will take a look at how to get the Chef service installed and get a new node provisioned and configured using some commonly used system roles and recipes.