

This section will discuss about functional programming in C#. We will be discussing both the conceptual aspects of functional programming and write code in C#, as well. We will be kick-starting the discussion by discussing about currying, pipelining, and method chaining.
In functional programming, functions behave the way a mathematical function behaves by returning the same value for a given argument regardless of the context in which it is invoked. This is called Referential Transparency. To understand this in more detail, consider that we have the following mathematical function notation, and we want to turn it into functional programming in C#:
f(x) = 4x2-14x-8
The functional programming in C# is as follows:
public partial class Program
{
public static int f(int x)
{
return (4 * x * x - 14 * x - 8);
}
}
From the preceding function, which we can find in the FunctionF.csproj file, if x is 5, we will obtain f of 5, which is 22. The notation will be as follows:
f(5) = 22
We can also invoke the f function in C#, as follows:
public partial class Program
{
static void Main(string[] args)
{
int i = f(5);
Console.WriteLine(i);
}
}
Every time we run the function with 5 as the argument, which means that x is equal to 5, we always receive 22 as the return value.
Now, compare this with the imperative approach. Let's take a look at the following code, which will be stored in the ImperativeApproach.csproj file:
public partial class Program
{
static int i = 0;
static void increment()
{
i++;
}
static void set(int inpSet)
{
i = inpSet;
}
}
We describe the following code in the Main() method:
public partial class Program
{
static void Main(string[] args)
{
increment();
Console.WriteLine("First increment(), i = {0}", i);
set(6);
increment();
Console.WriteLine("Second increment(), i = {0}", i);
set(2);
increment();
Console.WriteLine("Last increment(), i = {0}", i);
return;
}
}
If we run ImperativeApproach.csproj, the console screen should be like what is shown in the following screenshot:
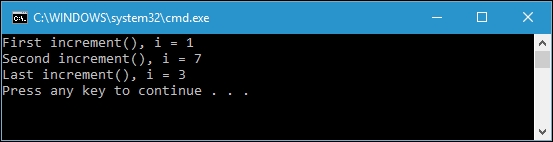
In the preceding imperative approach code, we will get the different i output in every invocation of increment or set although we pass the identical argument. Here, we find the so-called side effect problem of the imperative approach. The increment or set functions are said to have a side effect since they modify the state of i and interact with the outside world.
That was about side effects, and now, we have the following code in C#:
public partial class Program
{
public static string GetSign(int val)
{
string posOrNeg;
if (val > 0)
posOrNeg = "positive";
else
posOrNeg = "negative";
return posOrNeg;
}
}
The preceding code is statement style code, and we can find it in the StatementStyle.csproj file. It is an imperative programming technique that defines actions rather than producing results. We tell the computer what to do. We ask the computer to compare the value of the value variable with zero and then assign the posOrNeg variable to the associated value. We can try the preceding function by adding the following code to the project:
public partial class Program
{
static void Main(string[] args)
{
Console.WriteLine(
"Sign of -15 is {0}",
GetSign(-15));
}
}
The output in the console will be as follow:

And it agrees with our preceding discussion.
We can turn it into a functional approach by modifying it to expression style code. In C#, we can use the conditional operator to achieve this goal. The following is the code we have refactored from the StatementStyle.csproj code, and we can find it in the ExpressionStyle.csproj file:
public partial class Program
{
public static string GetSign(int val)
{
return val > 0 ? "positive" : "negative";
}
}
Now we have compact code that has the same behavior as our preceding many lines of code. However, as we discussed previously, the preceding code has no side-effect since it only returns the string value with no need to prepare the variable first. While in the statement style approach, we have to assign the posOrNeg variable twice. In other words, we can say that the functional approach will produce a side-effect-free function.
In contrast to imperative programming, in functional programming, we describe what we want as the result rather than specifying how to receive the result. Suppose we have a list of data and want to create a new list containing the Nth element from the source list. The imperative approach to achieve this is as follows:
public partial class Program
{
static List<int> NthImperative(List<int> list, int n)
{
var newList = new List<int>();
for (int i = 0; i < list.Count; i++)
{
if (i % n == 0) newList.Add(list[i]);
}
return newList;
}
}
The preceding code can be found in the NthElementImperative.csproj file. As we can see, to retrieve the Nth element from the list in C#, we have to initialize the first element so that we define i as 0. We then iterate through the list element and decide whether the current element is the Nth element. If so, we add newList the new data from the source list. Here, we find that the preceding source code is not a functional approach because the newList variable is assigned more than once when adding the new data. It also contains the loop process, which the functional approach doesn't have. However, we can turn the code into a functional approach as follows:
public partial class Program
{
static List<int> NthFunctional(List<int> list, int n)
{
return list.Where((x, i) => i % n == 0).ToList();
}
}
Again, we have compact code in the functional approach since we are using the power of the LINQ feature. If we want to try the preceding two functions, we can inset the following code to the Main() function:
public partial class Program
{
static void Main(string[] args)
{
List<int> listing =
new List<int>() {
0, 1, 2, 3, 4, 5,
6, 7, 8, 9, 10, 11,
12, 13, 14, 15, 16 };
var list3rd_imper = NthImperative(listing, 3);
PrintIntList("Nth Imperative", list3rd_imper);
var list3rd_funct = NthFunctional(listing, 3);
PrintIntList("Nth Functional", list3rd_funct);
}
}
For the PrintIntList() method, the implementation is as follows:
public partial class Program
{
static void PrintIntList(
string titleHeader,
List<int> list)
{
Console.WriteLine(
String.Format("{0}",
titleHeader));
foreach (int i in list)
{
Console.Write(String.Format("{0}\t", i));
}
Console.WriteLine("\n");
}
}
Although we run the two functions with different approaches, we are still given the same output, as follows:
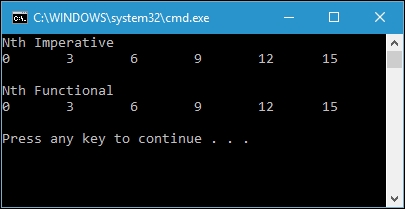
In .NET Framework 4, Tuples is introduced as a new set of generic classes to store a set of different typed elements. Tuples is immutable so it can be applied to functional programming. It is used to represent a data structure when we need the different data type in an object. Here is the available syntax to declare tuple objects:
public class Tuple <T1> public class Tuple <T1, T2> public class Tuple <T1, T2, T3> public class Tuple <T1, T2, T3, T4> public class Tuple <T1, T2, T3, T4, T5> public class Tuple <T1, T2, T3, T4, T5, T6> public class Tuple <T1, T2, T3, T4, T5, T6, T7> public class Tuple <T1, T2, T3, T4, T5, T6, T7, T8>
As we can see in the preceding syntaxes, we can create a tuple with a maximum eight item type (T1, T2, and so on). Tuple has read-only properties that’s why it’s immutable. Let’s look at the following code snippet we can find in Tuple.csproj project:
public partial class Program
{
Tuple<string, int, int> geometry1 =
new Tuple<string, int, int>(
"Rectangle",
2,
3);
Tuple<string, int, int> geometry2 =
Tuple.Create(
"Square",
2,
2);
}To create Tuple, we have two different ways based on the preceding code. The former, we instantiate a new Tuple to a variable. The latter, we use Tuple.Create(). To consume the Tuple data, we can use its Item like the following code snippet:
public partial class Program
{
private static void ConsumeTuple()
{
Console.WriteLine(
"{0} has size {1} x {2}",
geometry1.Item1,
geometry1.Item2,
geometry1.Item3);
Console.WriteLine(
"{0} has size {1} x {2}",
geometry2.Item1,
geometry2.Item2,
geometry2.Item3);
}
}If we run ConsumeTuple() method above, we will get the following on the console:

We can also return a tuple data type like we do in the following code snippet:
public partial class Program
{
private static Tuple<int, int> (
string shape)
{ GetSize
if (shape == "Rectangle")
{
return Tuple.Create(2, 3);
}
else if (shape == "Square")
{
return Tuple.Create(2, 2);
}
else
{
return Tuple.Create(0, 0);
}
}
}As we can see, GetSize() method will return Tuple data type. We can add the following ReturnTuple() method:
public partial class Program
{
private static void ReturnTuple()
{
var rect = GetSize("Rectangle");
Console.WriteLine(
"Rectangle has size {0} x {1}",
rect.Item1,
rect.Item2);
var square = GetSize("Square");
Console.WriteLine(
"Square has size {0} x {1}",
square.Item1,
square.Item2);
}
}And if we run ReturnTuple() method above, we will be displayed exactly same output as ConsumeTuple() method.
Fortunately, in C# 7, we can return Tuple data type without having to state the Tuple like the following code snippet:
public partial class Program
{
(int, int) GetSizeInCS7(
string shape)
{
if (shape == "Rectangle")
{
return (2, 3);
}
else if (shape == "Square")
{
return (2, 2);
}
else
{
return (0, 0);
}
}
}And if we want to name all items in the Tuple, we can now do it in C# 7 by using the technique like the following code snippet:
public partial class Program
{
private static (int x, int y) GetSizeNamedItem(
string shape)
{
if (shape == "Rectangle")
{
return (2, 3);
}
else if (shape == "Square")
{
return (2, 2);
}
else
{
return (0, 0);
}
}
}And now it will be clearer when we access the Tuple items like the following code:
public partial class Program
{
private static void ConsumeTupleByItemName()
{
var rect = GetSizeNamedItem("Rectangle");
Console.WriteLine(
"Rectangle has size {0} x {1}",
rect.x,
rect.y);
var square = GetSizeNamedItem("Square");
Console.WriteLine(
"Square has size {0} x {1}",
square.x,
square.y);
}
}We no longer call the Item1 and Item2, instead we call the x and y name.
In order to gain all new feature of Tuple in C# 7, we have to download System.ValueTuple NuGet package from https://www.nuget.org/packages/System.ValueTuple.
We have theoretically discussed currying at the beginning of this chapter. We apply currying when we split a function that takes multiple arguments into a sequence of functions that occupy part of the argument. In other words, when we pass fewer arguments into a function, it will expect that we get back another function to complete the original function using the sequence of functions. Let's take a look at the following code from the NonCurriedMethod.csproj file:
public partial class Program
{
public static int NonCurriedAdd(int a, int b) => a + b;
}
The preceding function will add the a and b arguments and then return the result. The usage of this function is commonly used in our daily programming; for instance, take a look at the following code snippet:
public partial class Program
{
static void Main(string[] args)
{
int add = NonCurriedAdd(2, 3);
Console.WriteLine(add);
}
}
Now, let's move on to the curried method. The code will be found in the CurriedMethod.csproj file, and the function declaration will be as follows:
public partial class Program
{
public static Func<int, int> CurriedAdd(int a) => b => a + b;
}
We use the Func<> delegate to create the CurriedAdd() method. We can invoke the preceding method in two ways, and the first is as follows:
public partial class Program
{
public static void CurriedStyle1()
{
int add = CurriedAdd(2)(3);
Console.WriteLine(add);
}
}
In the preceding invocation of the CurriedAdd() method, we pass the argument with two brackets, which it might not be familiar with. In fact, we can also curry our CurriedAdd() method by passing one argument only. The code will be as follows:
public partial class Program
{
public static void CurriedStyle2()
{
var addition = CurriedAdd(2);
int x = addition(3);
Console.WriteLine(x);
}
}
From the preceding code, we supply one argument to the CurriedAdd() method in the following:
var addition = CurriedAdd(2);
Then, it waits for the other addition expression, which we provide in the following code:
int x = addition(3);
The result of the preceding code will be completely the same as the NonCurried() method.
Pipelining is a technique used to pass the output of one function as an input to the next function. The data in the operation will flow like the flow of water in a pipe. We usually find this technique in command-line interfaces. Let's take a look at the following command line:
C:\>dir | more
The preceding command line will pass the output of the dir command to the input of the more command. Now, let's take a look at the following C# code that we can find in the NestedMethodCalls.csproj file:
class Program
{
static void Main(string[] args)
{
Console.WriteLine(
Encoding.UTF8.GetString(
new byte[] { 0x70, 0x69, 0x70, 0x65, 0x6C,
0x69, 0x6E, 0x69, 0x6E, 0x67 }
)
);
}
}
In the previous code, we used the nested method calls technique to write pipelining in console screen. If we want to refactor it to the pipelining approach, we can take a look at the following code that we can find in the Pipelining.csproj file:
class Program
{
static void Main(string[] args)
{
var bytes = new byte[] {
0x70, 0x69, 0x70, 0x65, 0x6C,
0x69, 0x6E, 0x69, 0x6E, 0x67 };
var stringFromBytes = Encoding.UTF8.GetString(bytes);
Console.WriteLine(stringFromBytes);
}
}
If run the preceding code, we will get exactly the same pipelining output, but this time, it will be in the pipelining style.
Method chaining is process of chaining multiple methods in one code line. The return from one method will be the input of the next method, and so on. Using method chaining, we don't need to declare many variables to store every method return. Instead, the return of the method will be passed to the next method argument. The following is the traditional method, which doesn't apply method chaining, and we can find the code at TraditionalMethod.csproj:
class Program
{
static void Main(string[] args)
{
var sb = new StringBuilder("0123", 10);
sb.Append(new char[] { '4', '5', '6' });
sb.AppendFormat("{0}{1}{2}", 7, 8, 9);
sb.Insert(0, "number: ");
sb.Replace('n', 'N');
var str = sb.ToString();
Console.WriteLine(str);
}
}
There are five methods of StringBuilder invoked inside the Main function and two variables: sb is used to initialize StringBuilder and str is used to store StringBuilder in the string format. Unfortunately, the five methods we invoked there modify the sb variable. We can refactor the code to apply method chaining in order to make it functional. The following is the functional code, and we can find it at ChainingMethod.csproj:
class Program
{
static void Main(string[] args)
{
var str =
new StringBuilder("0123", 10)
.Append(new char[] { '4', '5', '6' })
.AppendFormat("{0}{1}{2}", 7, 8, 9)
.Insert(0, "number: ")
.Replace('n', 'N')
.ToString();
Console.WriteLine(str);
}
}
The same output will be displayed if we run both types of code. However, we now have functional code by chaining all the invoking methods.