

We are using recursion to express looping. However, recursive code could result in a stack overflow. We need to understand an important optimization technique called tail call optimization (TCO). When TCO is applied, behind the scenes, recursion is expressed as a loop. This avoids stack frames, and subsequently, stack overflow.
For example, here is the preceding print method modified to print the range in reverse:
scala> def revprint(low: Int, high: Int): Unit = {
| if (low <= high) {
| revprint(low+1, high)
| println(low)
| }
| }
scala> revprint(1,4)
4
3
2
1
The following diagram shows the stack frames used:
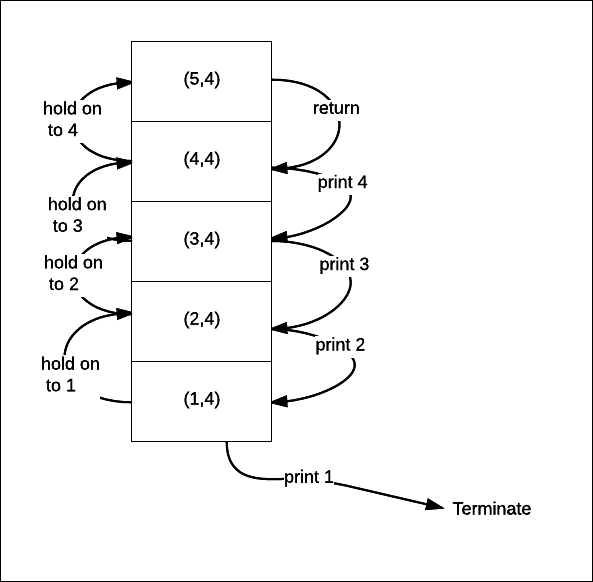
We need the stack to remember the value of low as we need to print it. We remember this value on a stack frame. There are limited stack frames though. So if we call revprint as revprint(1, 10000), then we get StackOverflowError.
If we can express our algorithm...