

Let us get our hands dirty and have a look at our hypothetical web startup, MLAAS, which sells the service of providing machine learning algorithms via HTTP. With the increasing success of our company, the demand for better infrastructure also increases to serve all incoming web requests successfully. We don't want to allocate too many resources as that would be too costly. On the other hand, we will lose money if we have not reserved enough resources for serving all incoming requests. The question now is, when will we hit the limit of our current infrastructure, which we estimated being 100,000 requests per hour. We would like to know in advance when we have to request additional servers in the cloud to serve all the incoming requests successfully without paying for unused ones.
We have collected the web stats for the last month and aggregated them in ch01/data/web_traffic.tsv (tsv because it contains tab separated values). They are stored as the number of hits per hour. Each line contains consecutive hours and the number of web hits in that hour.
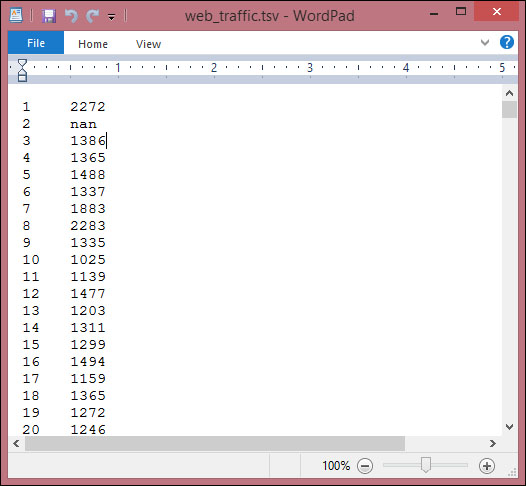
The first few lines look like the following:
Using SciPy's genfromtxt(), we can easily read in the data.
import scipy as sp
data = sp.genfromtxt("web_traffic.tsv", delimiter="\t")We have to specify tab as the delimiter so that the columns are correctly determined.
A quick check shows that we have correctly read in the data.
>>> print(data[:10]) [[ 1.00000000e+00 2.27200000e+03] [ 2.00000000e+00 nan] [ 3.00000000e+00 1.38600000e+03] [ 4.00000000e+00 1.36500000e+03] [ 5.00000000e+00 1.48800000e+03] [ 6.00000000e+00 1.33700000e+03] [ 7.00000000e+00 1.88300000e+03] [ 8.00000000e+00 2.28300000e+03] [ 9.00000000e+00 1.33500000e+03] [ 1.00000000e+01 1.02500000e+03]] >>> print(data.shape) (743, 2)
It is more convenient for SciPy to separate the dimensions into two vectors, each of size 743. The first vector, x, will contain the hours and the other, y, will contain the web hits in that particular hour. This splitting is done using the special index notation of SciPy, using which we can choose the columns individually.
x = data[:,0] y = data[:,1]
Note
There is much more to the way data can be selected from a SciPy array. Check out http://www.scipy.org/Tentative_NumPy_Tutorial for more details on indexing, slicing, and iterating.
One caveat is that we still have some values in y that contain invalid values, nan. The question is, what can we do with them? Let us check how many hours contain invalid data.
>>> sp.sum(sp.isnan(y)) 8
We are missing only 8 out of 743 entries, so we can afford to remove them. Remember that we can index a SciPy array with another array. sp.isnan(y) returns an array of Booleans indicating whether an entry is not a number. Using ~, we logically negate that array so that we choose only those elements from x and y where y does contain valid numbers.
x = x[~sp.isnan(y)] y = y[~sp.isnan(y)]
To get a first impression of our data, let us plot the data in a scatter plot using Matplotlib. Matplotlib contains the pyplot package, which tries to mimic Matlab's interface—a very convenient and easy-to-use one (you will find more tutorials on plotting at http://matplotlib.org/users/pyplot_tutorial.html).
import matplotlib.pyplot as plt
plt.scatter(x,y)
plt.title("Web traffic over the last month")
plt.xlabel("Time")
plt.ylabel("Hits/hour")
plt.xticks([w*7*24 for w in range(10)],
['week %i'%w for w in range(10)])
plt.autoscale(tight=True)
plt.grid()
plt.show()In the resulting chart, we can see that while in the first weeks the traffic stayed more or less the same, the last week shows a steep increase:
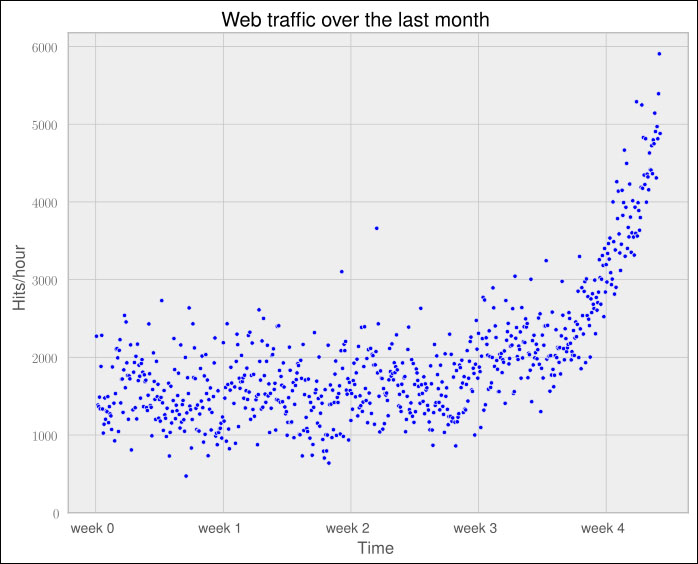
Now that we have a first impression of the data, we return to the initial question: how long will our server handle the incoming web traffic? To answer this we have to:
Find the real model behind the noisy data points
Use the model to extrapolate into the future to find the point in time where our infrastructure has to be extended
When we talk about models, you can think of them as simplified theoretical approximations of the complex reality. As such there is always some inferiority involved, also called the approximation error. This error will guide us in choosing the right model among the myriad of choices we have. This error will be calculated as the squared distance of the model's prediction to the real data. That is, for a learned model function, f, the error is calculated as follows:
def error(f, x, y):
return sp.sum((f(x)-y)**2)The vectors x and y contain the web stats data that we have extracted before. It is the beauty of SciPy's vectorized functions that we exploit here with f(x). The trained model is assumed to take a vector and return the results again as a vector of the same size so that we can use it to calculate the difference to y.
Let us assume for a second that the underlying model is a straight line. The challenge then is how to best put that line into the chart so that it results in the smallest approximation error. SciPy's polyfit() function does exactly that. Given data x and y and the desired order of the polynomial (straight line has order 1), it finds the model function that minimizes the error function defined earlier.
fp1, residuals, rank, sv, rcond = sp.polyfit(x, y, 1, full=True)
The polyfit() function returns the parameters of the fitted model function, fp1; and by setting full to True, we also get additional background information on the fitting process. Of it, only residuals are of interest, which is exactly the error of the approximation.
>>> print("Model parameters: %s" % fp1)
Model parameters: [ 2.59619213 989.02487106]
>>> print(res)
[ 3.17389767e+08]This means that the best straight line fit is the following function:
f(x) = 2.59619213 * x + 989.02487106.
We then use poly1d() to create a model function from the model parameters.
>>> f1 = sp.poly1d(fp1) >>> print(error(f1, x, y)) 317389767.34
We have used full=True to retrieve more details on the fitting process. Normally, we would not need it, in which case only the model parameters would be returned.
Note
In fact, what we do here is simple curve fitting. You can find out more about it on Wikipedia by going to http://en.wikipedia.org/wiki/Curve_fitting.
We can now use f1() to plot our first trained model. In addition to the earlier plotting instructions, we simply add the following:
fx = sp.linspace(0,x[-1], 1000) # generate X-values for plotting plt.plot(fx, f1(fx), linewidth=4) plt.legend(["d=%i" % f1.order], loc="upper left")
The following graph shows our first trained model:
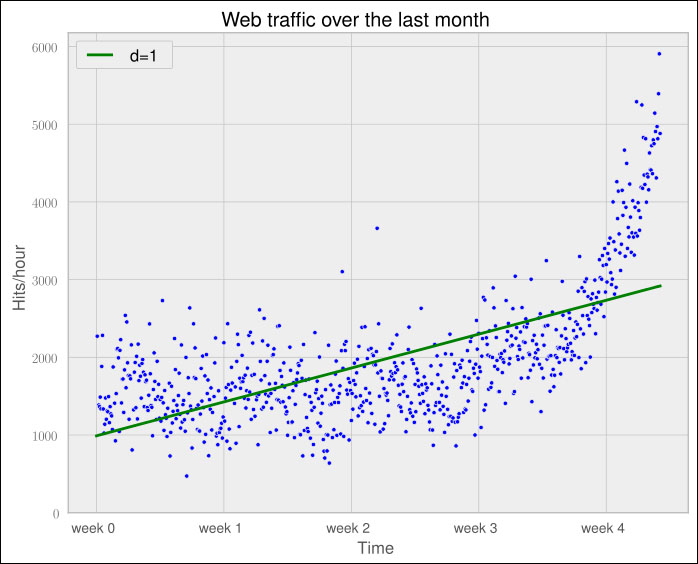
It seems like the first four weeks are not that far off, although we clearly see that there is something wrong with our initial assumption that the underlying model is a straight line. Plus, how good or bad actually is the error of 317,389,767.34?
The absolute value of the error is seldom of use in isolation. However, when comparing two competing models, we can use their errors to judge which one of them is better. Although our first model clearly is not the one we would use, it serves a very important purpose in the workflow: we will use it as our baseline until we find a better one. Whatever model we will come up with in the future, we will compare it against the current baseline.
Let us now fit a more complex model, a polynomial of degree 2, to see whether it better "understands" our data:
>>> f2p = sp.polyfit(x, y, 2) >>> print(f2p) array([ 1.05322215e-02, -5.26545650e+00, 1.97476082e+03]) >>> f2 = sp.poly1d(f2p) >>> print(error(f2, x, y)) 179983507.878
The following chart shows the model we trained before (straight line of one degree) with our newly trained, more complex model with two degrees (dashed):
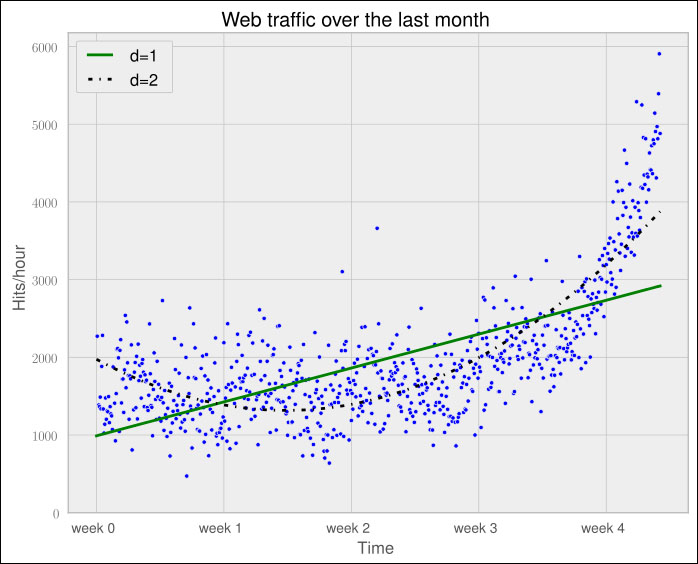
The error is 179,983,507.878, which is almost half the error of the straight-line model. This is good; however, it comes with a price. We now have a more complex function, meaning that we have one more parameter to tune inside polyfit(). The fitted polynomial is as follows:
f(x) = 0.0105322215 * x**2 - 5.26545650 * x + 1974.76082
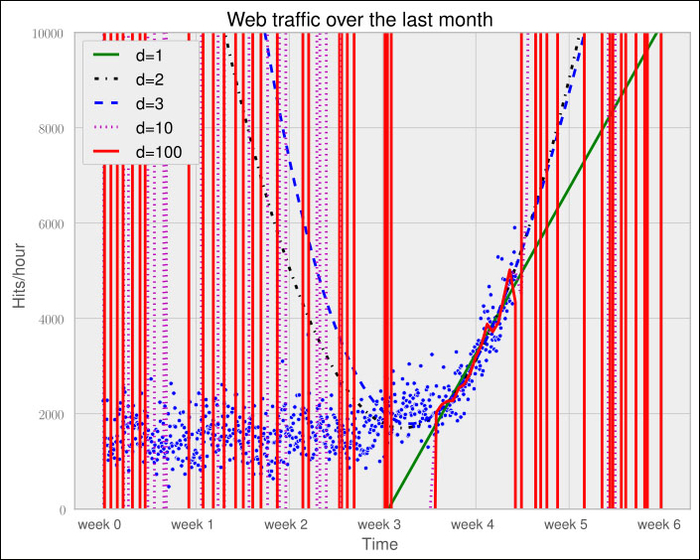
So, if more complexity gives better results, why not increase the complexity even more? Let's try it for degree 3, 10, and 100.
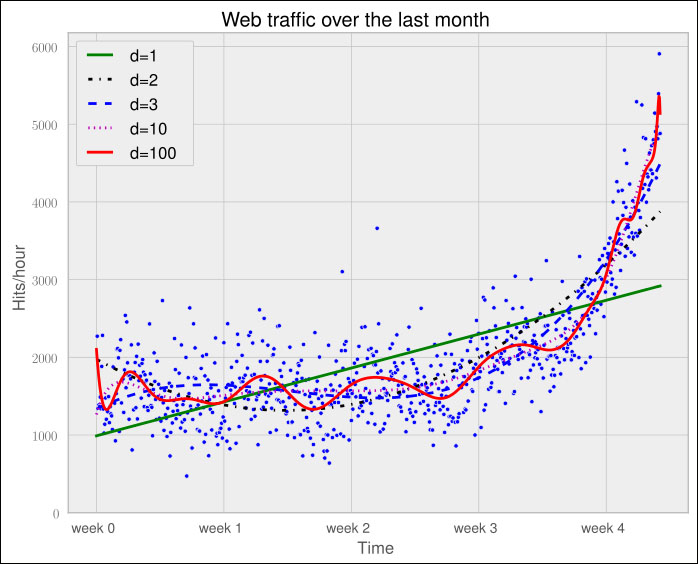
The more complex the data gets, the curves capture it and make it fit better. The errors seem to tell the same story.
Error d=1: 317,389,767.339778 Error d=2: 179,983,507.878179 Error d=3: 139,350,144.031725 Error d=10: 121,942,326.363461 Error d=100: 109,318,004.475556
However, taking a closer look at the fitted curves, we start to wonder whether they also capture the true process that generated this data. Framed differently, do our models correctly represent the underlying mass behavior of customers visiting our website? Looking at the polynomial of degree 10 and 100, we see wildly oscillating behavior. It seems that the models are fitted too much to the data. So much that it is now capturing not only the underlying process but also the noise. This is called overfitting.
At this point, we have the following choices:
Selecting one of the fitted polynomial models.
Switching to another more complex model class; splines?
Thinking differently about the data and starting again.
Of the five fitted models, the first-order model clearly is too simple, and the models of order 10 and 100 are clearly overfitting. Only the second- and third-order models seem to somehow match the data. However, if we extrapolate them at both borders, we see them going berserk.
Switching to a more complex class also seems to be the wrong way to go about it. What arguments would back which class? At this point, we realize that we probably have not completely understood our data.
So, we step back and take another look at the data. It seems that there is an inflection point between weeks 3 and 4. So let us separate the data and train two lines using week 3.5 as a separation point. We train the first line with the data up to week 3, and the second line with the remaining data.
inflection = 3.5*7*24 # calculate the inflection point in hours
xa = x[:inflection] # data before the inflection point
ya = y[:inflection]
xb = x[inflection:] # data after
yb = y[inflection:]
fa = sp.poly1d(sp.polyfit(xa, ya, 1))
fb = sp.poly1d(sp.polyfit(xb, yb, 1))
fa_error = error(fa, xa, ya)
fb_error = error(fb, xb, yb)
print("Error inflection=%f" % (fa + fb_error))
Error inflection=156,639,407.701523Plotting the two models for the two data ranges gives the following chart:
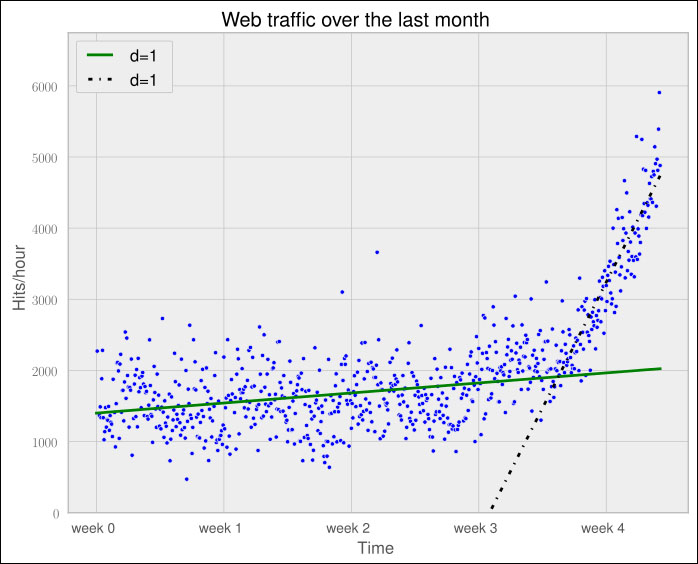
Clearly, the combination of these two lines seems to be a much better fit to the data than anything we have modeled before. But still, the combined error is higher than the higher-order polynomials. Can we trust the error at the end?
Asked differently, why do we trust the straight line fitted only at the last week of our data more than any of the more complex models? It is because we assume that it will capture future data better. If we plot the models into the future, we see how right we are (d=1 is again our initially straight line).
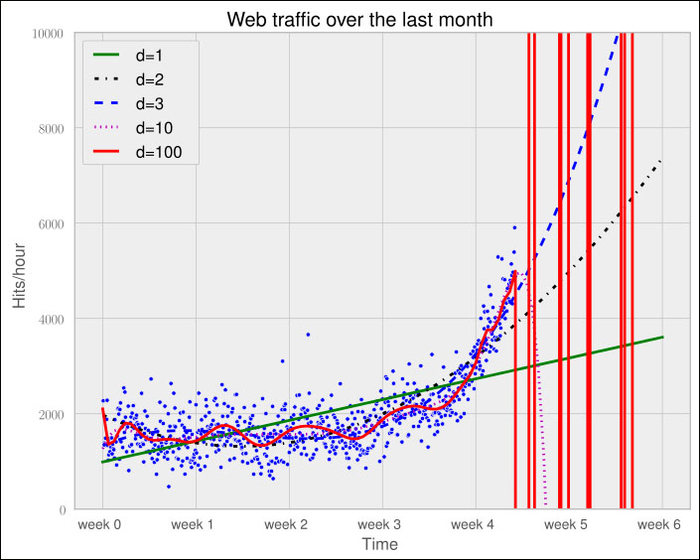
The models of degree 10 and 100 don't seem to expect a bright future for our startup. They tried so hard to model the given data correctly that they are clearly useless to extrapolate further. This is called overfitting. On the other hand, the lower-degree models do not seem to be capable of capturing the data properly. This is called underfitting.
So let us play fair to the models of degree 2 and above and try out how they behave if we fit them only to the data of the last week. After all, we believe that the last week says more about the future than the data before. The result can be seen in the following psychedelic chart, which shows even more clearly how bad the problem of overfitting is:
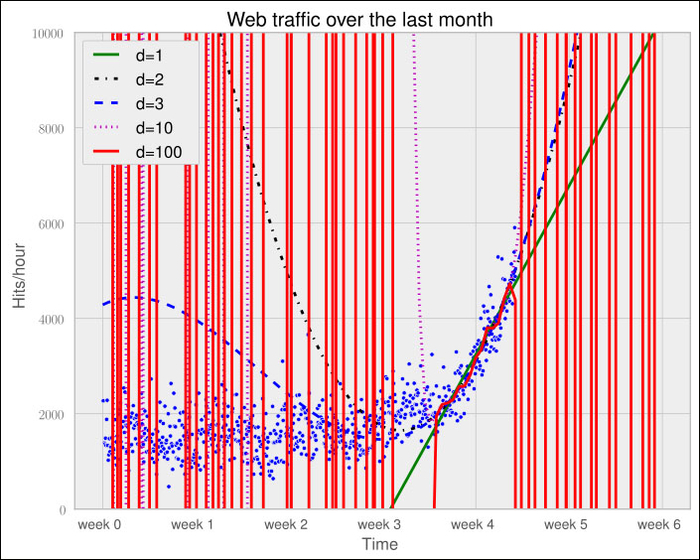
Still, judging from the errors of the models when trained only on the data from week 3.5 and after, we should still choose the most complex one.
Error d=1: 22143941.107618 Error d=2: 19768846.989176 Error d=3: 19766452.361027 Error d=10: 18949339.348539 Error d=100: 16915159.603877
If only we had some data from the future that we could use to measure our models against, we should be able to judge our model choice only on the resulting approximation error.
Although we cannot look into the future, we can and should simulate a similar effect by holding out a part of our data. Let us remove, for instance, a certain percentage of the data and train on the remaining one. Then we use the hold-out data to calculate the error. As the model has been trained not knowing the hold-out data, we should get a more realistic picture of how the model will behave in the future.
The test errors for the models trained only on the time after the inflection point now show a completely different picture.
Error d=1: 7,917,335.831122 Error d=2: 6,993,880.348870 Error d=3: 7,137,471.177363 Error d=10: 8,805,551.189738 Error d=100: 10,877,646.621984
The result can be seen in the following chart:
It seems we finally have a clear winner. The model with degree 2 has the lowest test error, which is the error when measured using data that the model did not see during training. And this is what lets us trust that we won't get bad surprises when future data arrives.
Finally, we have arrived at a model that we think represents the underlying process best; it is now a simple task of finding out when our infrastructure will reach 100,000 requests per hour. We have to calculate when our model function reaches the value 100,000.
Having a polynomial of degree 2, we could simply compute the inverse of the function and calculate its value at 100,000. Of course, we would like to have an approach that is applicable to any model function easily.
This can be done by subtracting 100,000 from the polynomial, which results in another polynomial, and finding the root of it. SciPy's optimize module has the fsolve function to achieve this when providing an initial starting position. Let fbt2 be the winning polynomial of degree 2:
>>> print(fbt2)
2
0.08844 x - 97.31 x + 2.853e+04
>>> print(fbt2-100000)
2
0.08844 x - 97.31 x - 7.147e+04
>>> from scipy.optimize import fsolve
>>> reached_max = fsolve(fbt2-100000, 800)/(7*24)
>>> print("100,000 hits/hour expected at week %f" % reached_max[0])
100,000 hits/hour expected at week 9.827613Our model tells us that given the current user behavior and traction of our startup, it will take another month until we have reached our threshold capacity.
Of course, there is a certain uncertainty involved with our prediction. To get the real picture, you can draw in more sophisticated statistics to find out about the variance that we have to expect when looking farther and further into the future.
And then there are the user and underlying user behavior dynamics that we cannot model accurately. However, at this point we are fine with the current predictions. After all, we can prepare all the time-consuming actions now. If we then monitor our web traffic closely, we will see in time when we have to allocate new resources.