

The conceptual origin of statistics is perceived to be from probability theories. We all must have heard something like the probability of rain tomorrow is 50%. While this seems very quantitative and thus should be easily interpretable, it is not very clear what it means. It can be interpreted to mean that for all the days when weather conditions are the same as tomorrow, it will rain on half of those days.
Probability helps us calculate the extent to which something is likely to happen or the likelihood of an event.
Probability is useful in various fields, such as statistics, computer science, physics, finance, gambling, sports, medicine, and even in machine learning and artificial intelligence.
Probability in mathematics is built around sets. Set theory is very useful in probability; it provides a language for expressing and working with events.
The sample space of an experiment is the set of all possible outcomes of the experiment; let's call it S. An event, let's call it A, is a subset of the sample space S, and we say that A occurred if the actual outcome is in A.
Let's take an example of picking a card from a standard deck of 52 cards. The sample space S is the set of all the cards. Let's us consider an event A where the card we pick is an ace. This is a subset of the sample space. So the probability P of picking an ace is:
Probability = (number of elements in the event) / (number of elements in the sample space).
This says that the probability of the intersection of two events A and B can be computed as the product of probability of A given that B has happened times the probability of B:
The law of total probability or law of alternatives can be formulated as follows:
Probability is a way of expressing uncertainties about events. Whenever we observe new evidence or obtain data, we acquire information that may affect our uncertainties. Conditional probability is the concept that tells us how to express the probability which is affected by the newly acquired information. Conditional probability handles situations where you have some additional knowledge about the outcome of a trial or experiment.
Let's consider an event R, It will rain today, before looking at the sky. The probability P(R) will increase when we look at the sky and see dark clouds. So the new probability is P (R|C) where C is the event of dark clouds.
If A and B are events with P (B) > 0,then the conditional probability of A given B, denoted by P(A|B), is defined as:
Let us consider an example and try to perform the same using R. We are rolling two dice and the objective is to find the probability of the sum of the outcomes being greater than or equal to 8, given that the first dice has resulted in 3:
library(prob) S <- rolldie(2, makespace = TRUE) A <- subset(S, X1 + X2 >= 8) B <- subset(S, X1 == 3) #Given Prob(A, given = B)
Bayes' formula gives us a way to test a hypothesis using conditional probabilities. A hypothesis is a suggested explanation for a specific outcome. If we see that a probability P (A | B) is high, we might hypothesize that event B is a cause of the event A. We use Bayes' formula when we know conditional probabilities of the form P (B | A) and want a conditional probability of the form P (A | B):
Two events, A and B, in the same sample space are independent if P (AB) = P (A) P (B).This formula gives us a new and simpler way to characterize independent events. Two events, A and B, are independent if the probability of both events happening together is equal to the product of the probabilities of the two events.
In probability, a random variable is a rule or function that assigns a number to each element of a sample space. In other words, a random variable gives a number for each outcome of a random experiment. In statistics, we define random variables using the letter X. There are different types of random variable.
When we toss two coins, the number of heads we can get is 0, 1, or 2 .We can define X as the number of heads that I get during this experiment. These random variable values have a probability associated with them; these variables can be represented as discrete points on a number line so they are called discrete random variables.
Let's say that we have to look at the physics test scores of 100 class 10 students. The test scores will fall between 0% and 100%. The test scores of the students may vary, such as 95.5%, 88%, 97.2%, and so on. We cannot denote all the test scores using discrete numbers when all values in an interval are possible. This is called a continuous random variable.
Once we have a random variable, we can determine the probability that the random variable will have a certain value; for example, for rolling two dice to get a sum of five outcomes, it can be (1,4) , (4,1) , (3,2) , or (2,3) so there are 4 out of 36 possible outcomes, so:
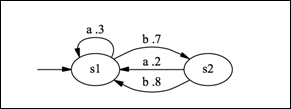
R provides a wide range of probability functions. The generic prefixes for probability functions in R are r, d, p, q, for random number generators, probability density function, cumulative density function, and quantile function, respectively.
A comprehensive list of functions available is as follows:
|
Distribution |
Functions | |||
|---|---|---|---|---|
|
Beta |
|
|
|
|
|
Binomial |
|
|
|
|
|
Cauchy |
|
|
|
|
|
Chi-Square |
|
|
|
|
|
Exponential |
|
|
|
|
|
F |
|
|
|
|
|
Gamma |
|
|
|
|
|
Geometric |
|
|
|
|
|
Hypergeometric |
|
|
|
|
|
Logistic |
|
|
|
|
|
Log Normal |
|
|
|
|
|
Negative Binomial |
|
|
|
|
|
Normal |
|
|
|
|
|
Poisson |
|
|
|
|
|
Student t |
|
|
|
|
|
Studentized Range |
|
|
|
|
|
Uniform |
|
|
|
|
|
Weibull |
|
|
|
|
|
Wilcoxon Rank Sum Statistic |
|
|
|
|
|
Wilcoxon Signed Rank Statistic |
|
|
|
|
This frequency function gives the probabilities for each value in the range of a random variable. For a given value R of the random variable, the cumulative distribution function gives the probability of the random variable taking on a value up to and including the given value R. When R is 3, there are three outcomes, (1, 1), (1, 2), and (2, 1), so:
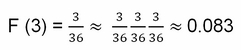
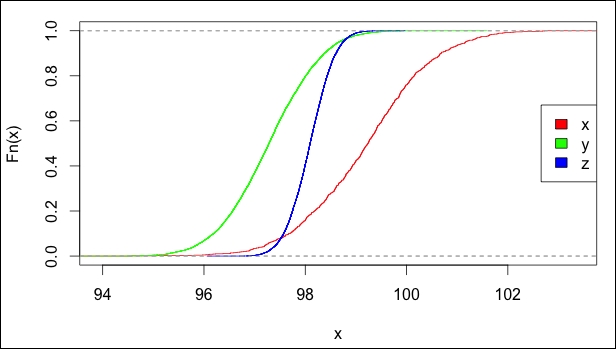
The cumulative distribution function is also called the CDF, or probability distribution or distribution function. The stats package in R provides the function ecdf to compute the empirical cumulative distribution function and plot it using the object created. You can also plot the ecdf object using the ggplot2 package. Let's look at an example for the same:
x <- rnorm(1000, 99.2, 1.2) y <- rnorm(10000, 97.3, 0.85) z <- rnorm(10000, 98.1, 0.4) # Create a chart with all 3 Conditional distribution plots plot(ecdf(x), col=rgb(1,0,0), main=NA) plot(ecdf(y), col=rgb(0,1,0), add=T) plot(ecdf(z), col=rgb(0,0,1), add=T) # Adding legend to the chart. legend('right', c('x', 'y', 'z'), fill=c(rgb(1,0,0), rgb(0,1,0), rgb(0,0,1)))
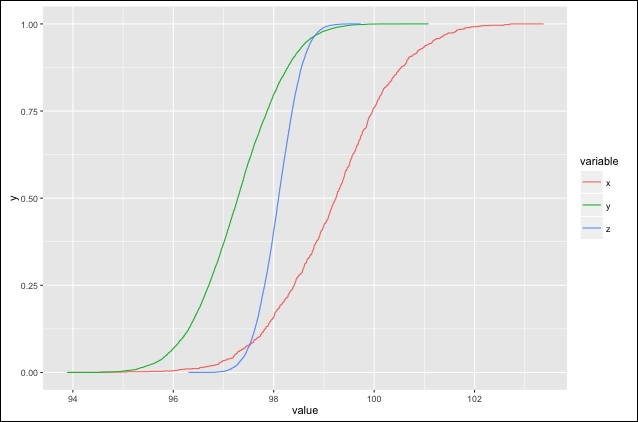
Using the ggplot2 package, create the CDF plot with the ecdf function:
# Load the required packages. library("reshape2","plyr","ggplot2") # transform the data. plot_data <- melt(data.frame(x, y, z)) plot_data <- ddply(plot_data, .(variable), transform, cd=ecdf(value)(value)) # Create the CDF using ggplot. cdf <- ggplot(plot_data, aes(x=value)) + stat_ecdf(aes(colour=variable)) # Generate the Conditional distribution plot. cdf
Two different random variables can be associated with the same sample space. When there are two random variables on the same sample space, we study their interaction using a joint distribution. Let's consider an example: we want to know the probability that the sum of the same dice rolled twice is 6, so S = 6, and that the lowest die is 3, so D = 3. We represent this as follows:
P{S = 6, D = 3}
P {S = 6} = (1, 5) (2, 4) (3, 3) (4, 2) (1, 5);
Of the five outcomes, only one has the lower number equal to 3 so the probability is:
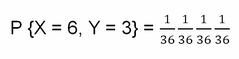
If there are only two outcomes to a trial, one with probability P and the other with probability 1 – P, often one outcome is called a success and the other a failure. When this is the case, P is used as the probability of success and the probability of failure is 1 – P. Such an experiment is called a Bernoulli trial or a binomial trial, because there are only two outcomes. The random variable associated with a Bernoulli trial is the Bernoulli random variable, with value 1 for a successful outcome and value 0 for failure.
Let's take an example of flipping a coin. It gives two outcomes, heads and tails. If we assign the value 1 to heads and 0 to tails, we have a Bernoulli random variable. Let's call this random variable R and since heads and tails are equally likely to occur:
P{R = 1} = 0.5 and P{R = 0} = 0.5
If we repeat a Bernoulli trial many times over, we get a new distribution, called a binomial distribution. So in order to compute the probability of k successes in n trials we can use the following formula:
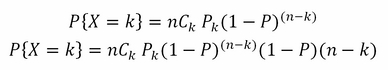
Here:
n: Number of trials
P: Probability of success
The Poisson distribution applies when occurrences are independent, so that one occurrence neither diminishes nor increases the chance of another. The average frequency of occurrence for the time period is known. The probability of an occurrence during a small time interval is proportional to the entire length of the time interval:
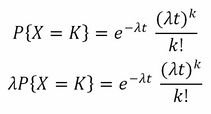
Here:
When we are putting together texts, we will not know the probability distribution of a particular topic. If we consider a corpus of country's economic strategy, written by various economists, it's difficult to understand the probability of what they are emphasizing more – is it infrastructure, manufacturing, banking, and so on – without counting the members associated. One thing to be aware of is no corpus will be balanced. We need to count the occurrences of relevant words in the dataset to get some statistical information. We need to know the frequency distribution of different words. Word frequencies refer to the number of word tokens that are instances of a word type. We can perform word counts over corpora with the R tau package.
Zipf's law is an interesting phenomenon that can be applied universally in many contexts, such as social sciences, cognitive sciences, and linguistics. When we consider a variety of datasets, there will be an uneven distribution of words. Zipf's law says that the frequency of a word, f (w), appears as a nonlinearly decreasing function of the rank of the word, r (w), in a corpus. This law is a power law: the frequency is a function of the negative power of rank. C is a constant that is determined by the particulars of the corpus; it's the frequency of the most frequent word:
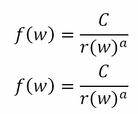
Given a collection of words, we can estimate the frequency of each unique word, which is nothing but the number of times the word occurs in the collection.
If we sort the words in descending order of their frequency of occurrence in the collection, and compute their rank, the product of their frequency and associated rank reveals a very interesting pattern.
N: Sample size or corpus size
V: Vocabulary size, count of distinct type in the corpus
Vm: Count of hapax terms, types that occur just once in a corpus
Let us consider a small sample S: a a a a b b b c c d d:
Here, N= 11, V = 4, Vm = 0.
Load Brown and Dickens frequency data:
library(zipfR) data(Dickens.spc) data(BrownVer.spc)
Check sample size and vocabulary and hapax counts:
N(BrownVer.spc) # 166262 V(BrownVer.spc) # 10007 Vm(BrownVer.spc,1) # 3787 N(Dickens.spc) # 2817208 V(Dickens.spc) # 41116 Vm(Dickens.spc,1) # 14220
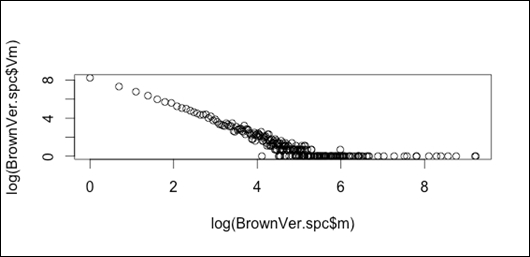
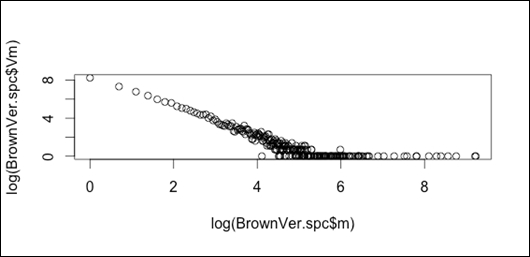
Zipf rank-frequency plot:
plot(log(BrownVer.spc$m),log(BrownVer.spc$Vm))
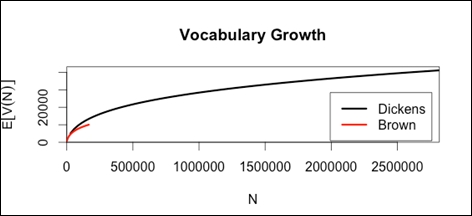
Compute binomially interpolated growth curves:
di.vgc <- vgc.interp(Dickens.spc,(1:100)*28170) br.vgc <- vgc.interp(BrownVer.spc,(1:100)*1662)
Plot vocabulary growth:
plot(di.vgc,br.vgc,legend=c("Dickens","Brown"))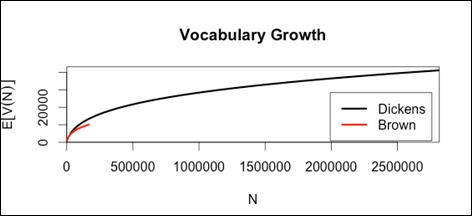
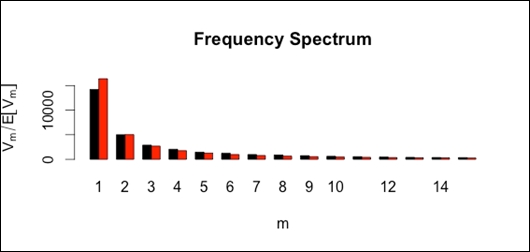
Compute Zipf-Mandelbrot model from Dickens data:
zm <- lnre("zm",Dickens.spc) ## plot observed and expected spectrum zm.spc <- lnre.spc(zm,N(Dickens.spc))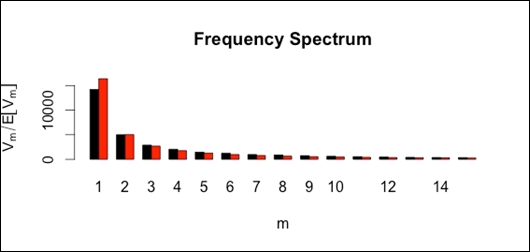
Let there be a word w which has the rank r' in a document and the probability of this word to be at rank r' be defined as P(r'). The probability P(r') can be expressed as the function of frequency of occurrence of the words as follows:
P(r') = Freq(r')/N,
where N is the sample size and Freq(r') is the frequency of occurrence of r' in the corpus
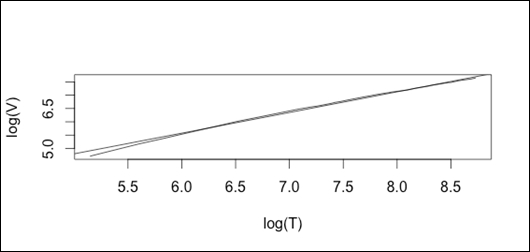
Heaps' law is also known as Herdan's Law. This law was discovered by Gustav Herdan, but the law is sometimes attributed to Harold Heaps. It is an empirical law which describes the relationship between type and tokens in linguistics. In simpler terms, Heaps' law defines the relation between the count of distinct words in document and the length of the specified document.
The relation can be expressed as:
Vr(n) = C* nb
Here, Vr is the count of distinct words in document and n is the size of the document. C and b are parameters defined empirically.
The similarity between Heaps' Law and Zipf's law is attributed to the fact that type-token relation is derivable from type distribution:
library(tm) data("acq") termdoc <- DocumentTermMatrix(acq) Heaps_plot(termdoc)
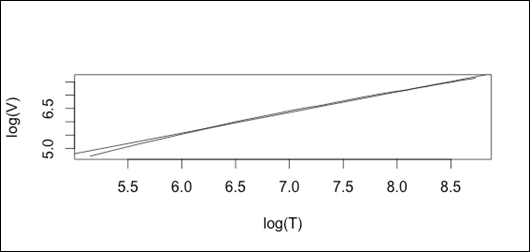
Quantitative analysis of lexical structure is relevant for many activities such as stylometrics, applied linguistics, computational linguistics, natural language processing, lexicology, and so on. There are different approaches to capture vocabulary richness. It can be measured by means of measure or of an index. It can be captured by means of curve, as in the case of Herdan's and Zipf's law. If we consider the empirical distribution of word types, we can derive the distribution based on combinatorial considerations or we can use consider the stochastic processes to derive the distribution.
In applied linguistics, lexical richness explains the qualified proficiency of the author in a document, in terms of language variation, width, length, and productive knowledge of vocabulary. Let's attempt to understand the multiple measures that explain the lexical richness of a text.
Lexical variation in language is considered to be multi-dimensional; all languages go through variations based on time and social settings. There are different lexical variants to the same word in same language. For instance, in the US, what you call a cookie is a biscuit in the UK. Most of us are aware of language variation based on geographical differences, such as elevator and lift, pavement and sidewalk, pants and trousers. Socio-cultural changes lead to the phenomenon of borrowing in cases of dialect contacts. Semantic shifts and broadening give the words different meanings in different contexts. While by semantic broadening, the words take a more generalized meaning, by semantic narrowing, it is bound to take more restricted meaning. Broadly, lexical variations are of two categories: conceptual variation and contextual variation, which is further categorized to formal variation, semasiologically variation, and onomasiolofical variation.
Lexical density is defined as the ratio of content to functional or grammatical words in a sentence. It is used in discourse analysis for texts. In simpler terms, lexical density explains the readability of a text.
Lexical density is determined as follows:
Ld = (Nlex / N) * 100
Here:
Ld = Lexical density
Nlex = Count of lexical tokens
N = Count of all tokens