

The purpose of machine learning is to teach computers to execute tasks without human intervention. An increasing number of applications such as genomics, social networking, advertising, or risk analysis generate a very large amount of data that can be analyzed or mined to extract knowledge or insight into a process, customer, or organization. Ultimately, machine learning algorithms consist of identifying and validating models to optimize a performance criterion using historical, present, and future data [1:4].
Data mining is the process of extracting or identifying patterns in a dataset.
The goal of unsupervised learning is to discover patterns of regularities and irregularities in a set of observations. The process is known as density estimation in statistics is broken down into two categories: discovery of data clusters and discovery of latent factors. The methodology consists of processing input data to understand patterns similar to the natural learning process in infants or animals. Unsupervised learning does not require labeled data (or expected values), and therefore, it is easy to implement and execute because no expertise is needed to validate an output. However, it is possible to label the output of a clustering algorithm and use it for future classification.
The purpose of data clustering is to partition a collection of data into a number of clusters or data segments. Practically, a clustering algorithm is used to organize observations into clusters by minimizing the distance between observations within a cluster and maximizing the distance between observations across clusters. A clustering algorithm consists of the following steps:
Creating a model by making an assumption on the input data.
Selecting the objective function or goal of the clustering.
Evaluating one or more algorithms to optimize the objective function.
Data clustering is also known as data segmentation or data partitioning.
Dimension reduction techniques aim at finding the smallest but most relevant set of features needed to build a reliable model. There are many reasons for reducing the number of features or parameters in a model, from avoiding overfitting to reducing computation costs.
There are many ways to classify the different techniques used to extract knowledge from data using unsupervised learning. The following taxonomy breaks down these techniques according to their purpose, although the list is far from being exhaustive, as shown in the following diagram:
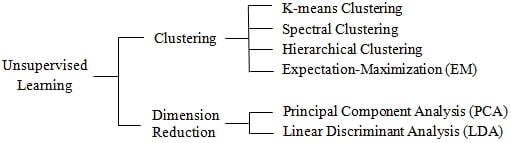
Taxonomy of unsupervised learning algorithms
The best analogy for supervised learning is function approximation or curve fitting. In its simplest form, supervised learning attempts to find a relation or function f: x → y using a training set {x, y}. Supervised learning is far more accurate than any other learning strategy as long as the input (labeled data) is available and reliable. The downside is that a domain expert may be required to label (or tag) data as a training set.
Supervised machine learning algorithms can be broken into two categories:
Generative models
Discriminative models
In order to simplify the description of a statistics formula, we adopt the following simplification: the probability of an X event is the same as the probability of the discrete X random variable to have a value x: p(X) = p(X=x).
The notation for the joint probability is p(X,Y) = p(X=x,Y=y).
The notation for the conditional probability is p(X|Y) = p(X=x|Y=y).
Generative models attempt to fit a joint probability distribution, p(X,Y), of two X and Y events (or random variables), representing two sets of observed and hidden x and y variables. Discriminative models compute the conditional probability, p(Y|X), of an event or random variable Y of hidden variables y, given an event or random variable X of observed variables x. Generative models are commonly introduced through the Bayes' rule. The conditional probability of a Y event, given an X event, is computed as the product of the conditional probability of the X event, given the Y event, and the probability of the X event normalized by the probability of the Y event [1:5].
Note
Bayes' rule
Joint probability for independent random variables, X=x and Y=y, is given by:
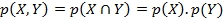
Conditional probability of a random variable, Y = y, given X = x, is given by:
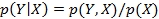
Bayes' formula is given by:
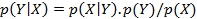
The Bayes' rule is the foundation of the Naïve Bayes classifier, as described in the Introducing the multinomial Naïve Bayes section in Chapter 5, Naïve Bayes Classifiers.
Contrary to generative models, discriminative models compute the conditional probability p(Y|X) directly, using the same algorithm for training and classification.
Generative and discriminative models have their respective advantages and disadvantages. Novice data scientists learn to match the appropriate algorithm to each problem through experimentation. Here is a brief guideline describing which type of models make sense according to the objective or criteria of the project:
|
Objective |
Generative models |
Discriminative models |
|---|---|---|
|
Accuracy |
Highly dependent on the training set. |
This depends on the training set and algorithm configuration (that is, kernel functions) |
|
Modeling requirements |
There is a need to model both observed and hidden variables, which requires a significant amount of training. |
The quality of the training set does not have to be as rigorous as for generative models. |
|
Computation cost |
This is usually low. For example, any graphical method derived from the Bayes' rule has low overhead. |
Most algorithms rely on optimization of a convex function with significant performance overhead. |
|
Constraints |
These models assume some degree of independence among the model features. |
Most discriminative algorithms accommodate dependencies between features. |
We can further refine the taxonomy of supervised learning algorithms by segregating arbitrarily between sequential and random variables for generative models and breaking down discriminative methods as applied to continuous processes (regression) and discrete processes (classification):
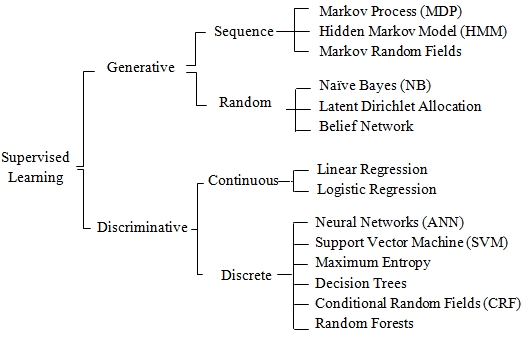
Taxonomy of supervised learning algorithms
Semi-supervised learning is used to build models from a dataset with incomplete labels. Manifold learning and information geometry algorithms are commonly applied to large datasets that are partially labeled. The description of semi-supervised learning techniques is beyond the scope of this book.
Reinforcement learning is not as well understood as supervised and unsupervised learning outside the realms of robotics or game strategy. However, since the 90s, genetic-algorithms-based classifiers have become increasingly popular to solve problems that require collaboration with a domain expert. For some types of applications, reinforcement learning algorithms output a set of recommended actions for the adaptive system to execute. In its simplest form, these algorithms estimate the best course of action. Most complex systems based on reinforcement learning establish and update policies that can be vetoed by an expert, if necessary. The foremost challenge developers of reinforcement learning systems face is that the recommended action or policy may depend on partially observable states.
Genetic algorithms are not usually considered part of the reinforcement learning toolbox. However, advanced models, such as learning classifier systems, use genetic algorithms to classify and reward the most performing rules and policies.
As with the two previous learning strategies, reinforcement learning models can be categorized as Markovian or evolutionary:
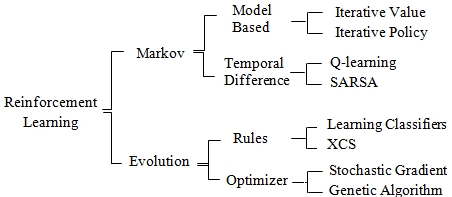
Taxonomy of reinforcement learning algorithms
This is a brief overview of machine learning algorithms with a suggested, approximate taxonomy. There are almost as many ways to introduce machine learning as there are data and computer scientists. We encourage you to browse through the list of references at the end of the book to find the documentation appropriate to your level of interest and understanding.