

The main goal in a decision tree algorithm is to identify a variable and classification on which one can give a more homogeneous distribution with reference to the target variable. The homogeneous distribution means that similar values of the target variable are grouped together so that a concrete decision can be made.
In the preceding example, the first goal would be to find a parameter (out of four: Terrain, Rainfall, Groundwater, and Fertilizers) that results in a better homogeneous distribution of the target variable within those categories.
Without any parameter, the count of harvest type looks as follows:
|
Bumper |
Moderate |
Meagre |
|---|---|---|
|
4 |
9 |
7 |
Let us calculate, for each parameter, how the split on that parameter affects the homogeneity of the target variable split:
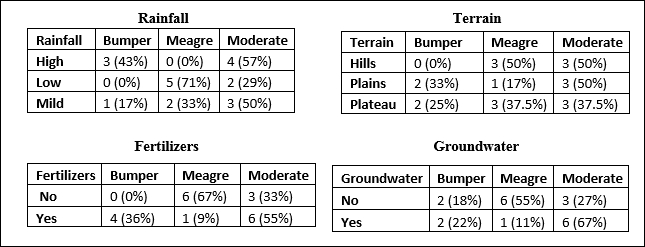
Fig. 8.4: Splitting the predictor and the target variables into categories to see their effect on the homogeneity of the dataset
If one...