

Up until now, we looked at how we can employ parallelism in the context of our own computer running R. However, our own machine can only take us so far in terms of its resources. To access the essentially unlimited compute, we need to look further afield, and to those of us mere mortals who don't have our own private data center available, we need to look to the cloud. The market leader in providing cloud services is Amazon with their AWS offering and of particular interest is their EMR service based on Hadoop that provides reliable and scalable parallel compute.
Luckily for us, there is a specific R package, segue, written by James "JD" Long and designed to simplify the whole experience of setting up an AWS EMR Hadoop cluster and utilizing it directly from an R session running on our own computer. The segue package is most applicable to run large-scale simulations or optimization problems—that is, problems that require large amounts of compute but only small amounts of data—and hence is suitable for our puzzle solver.
Before we can start to make use of segue, there are a couple of prerequisites we need to deal with: firstly, installing the segue package and its dependencies, and secondly, ensuring that we have an appropriately set-up AWS account.
Tip
Warning: credit card required!
As we work through the segue example, it is important to note that we will incur expenses. AWS is a paid service, and while there may be some free AWS service offerings that you are entitled to and the example we will run will only cost a few dollars, you need to be very aware of any ongoing billing charges you may be incurring for the various aspects of AWS that you use. It is critical that you are familiar with the AWS console and how to navigate your way around your account settings, your monthly billing statements, and, in particular, EMR, Elastic Compute Cloud (EC2), and Simple Storage
Service (S3) (these are elements as they will all be invoked when running the segue example in this chapter. For introductory information about these services, refer to the following links:
http://docs.aws.amazon.com/awsconsolehelpdocs/latest/gsg/getting-started.html
So, with our bank manager duly alerted, let's get started.
The segue package is not currently available as a CRAN package; you need to download it from the following location: https://code.google.com/p/segue/downloads/detail?name=segue_0.05.tar.gz&can=2&q=
The segue package depends on two other packages: rJava and caTools. If these are not already available within your R environment, you can install them directly from CRAN. In RStudio, this can simply be done from the Packages tab by clicking on the Install button. This will present you with a popup into which you can type the names rJava and caTools to install.
Once you download segue, you can install it in a similar manner in RStudio; the Install Packages popup has an option by which you can switch from Repository (CRAN, CRANextra) to Package Archive File and can then browse to the location of your downloaded segue package and install it. Simply loading the segue library in R will then load its dependencies as follows:
> library(segue) Loading required package: rJava Loading required package: caTools Segue did not find your AWS credentials. Please run the setCredentials() function.
The segue package interacts with AWS via its secure API, and this, in turn, is only accessible through your own unique AWS credentials—that is, your AWS Access Key ID and Secret Access Key. This pair of keys must be supplied to segue through its setCredentials() function. In the next section, we will take a look at how to set up your AWS account in order to obtain your root API keys.
Our assumption at this point is that you have successfully signed up for an AWS account at http://aws.amazon.com, having provided your credit card details and so on and gone through the e-mail verification procedure. If so, then the next step is to obtain your AWS security credentials. When you are logged into the AWS console, click on your name (in the upper-right corner of the screen) and select Security Credentials from the drop-down menu.
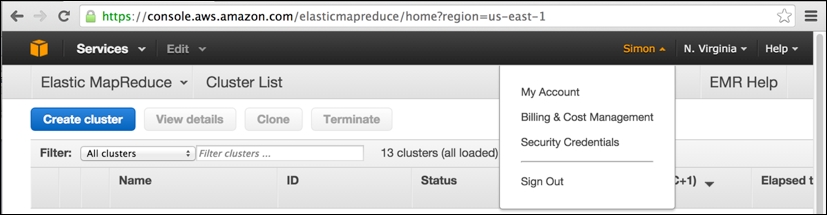
In the preceding screenshot, you can note that I have logged into the AWS console (accessible at the web URL https://console.aws.amazon.com) and have previously browsed to my EMR clusters (accessed via the Services drop-down menu to the upper-left) within the Amazon US-East-1 region in North Virginia.
This is the Amazon data center region used by segue to launch its EMR clusters. Having selected Security Credentials from your account name's drop-down menu, you will be taken to the following page:
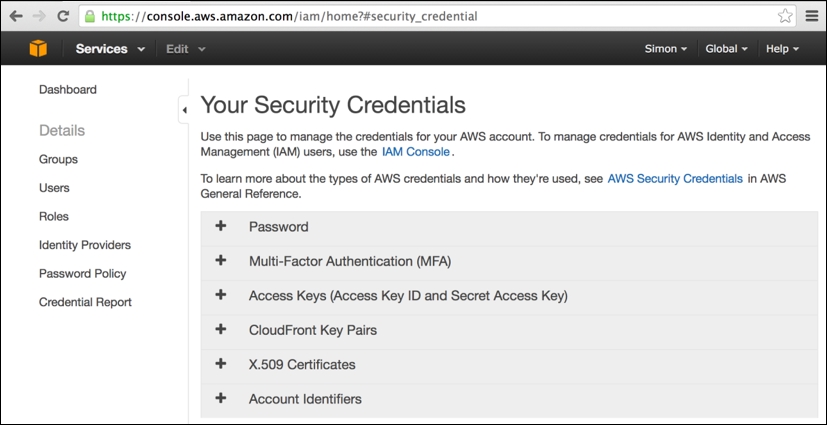
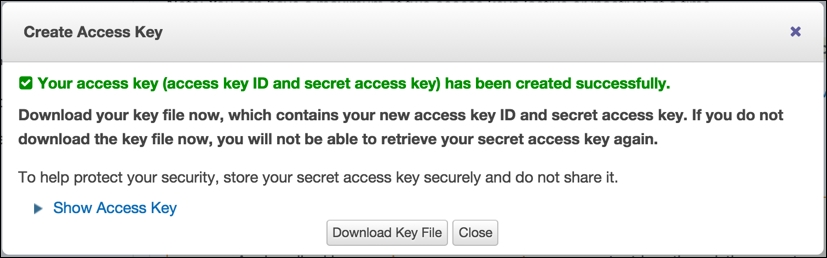
On this page, simply expand the Access Keys tab (click on +) and then click on the revealed Create New Access Key button (note that this button will not be enabled if you already have two existing sets of security keys still active). This will present you with the following popup with new keys created, which you should immediately download and keep safe:
Let's have a look at a tip:
Tip
Warning: Keep your credentials secure at all times!
You must keep your AWS access keys secure at all times. If at any point you think that these keys may have become known to someone, you should immediately log in to your AWS account, access this page, and disable your keys. It is a simple process to create a new key pair, and in any case, Amazon's recommended security practice is to periodically reset your keys. It hopefully goes without saying that you should keep the R script where you make a call to the segue package setCredentials() particularly secure within your own computer.
The basic operation of segue follows a similar pattern and has similar names to the parallel package's cluster functions we looked at in the previous section, namely:
> setCredentials("<Access Key ID>","<Secret Access Key>") > cluster <- createCluster(numInstances=<number of EC2 nodes>) > results <- emrlapply(cluster, tasks, FUN, taskTimeout=<10 mins default>) > stopCluster(cluster) ## Remember to save your bank balance!
A key thing to note is that as soon as the cluster is created, Amazon will charge you in dollars until you successfully call stopCluster(), even if you never actually invoke the emrlapply() parallel compute function.
The createCluster() function has a large number of options (detailed in the following table), but our main focus is the numInstances option as this determines the degree of parallelism used in the underlying EMR Hadoop cluster—that is, the number of independent EC2 compute nodes employed in the cluster. However, as we are using Hadoop as the cloud cluster framework, one of the instances in the cluster must act as the dedicated master process responsible for assigning tasks to workers and marshaling the results of the parallel MapReduce operation. Therefore, if we want to deploy a 15-way parallelism, then we would need to create a cluster with 16 instances.
Another key thing to note with emrlapply() is that you can optionally specify a task timeout option (the default is 10 minutes). The Hadoop master process will consider any task that does not deliver a result (or generate a file I/O) within the timeout period as having failed, the task execution will then be cancelled (and will not be retried by another worker), and a null result will be generated for the task and returned eventually by emrlapply(). If you have individual tasks (such as simulation runs) that you know are likely to exceed the default timeout, then you should set the timeout option to an appropriate higher value (the units are minutes). Be aware though that you do want to avoid generating an infinitely running worker process that will rapidly chew through your credit balance.
The
createCluster() function has a large number of options to select resources for use and to configure the R environment running within AWS EMR Hadoop. The following table summarizes these configuration options. Take a look at the following code:
createCluster(numInstances=2,cranPackages=NULL, customPackages=NULL, filesOnNodes=NULL, rObjectsOnNodes=NULL, enableDebugging=FALSE, instancesPerNode=NULL, masterInstanceType="m1.large", slaveInstanceType="m1.large", location="us-east-1c", ec2KeyName=NULL, copy.image=FALSE, otherBootstrapActions=NULL, sourcePackagesToInstall=NULL, masterBidPrice=NULL, slaveBidPrice=NULL) returns: reference object for the remote AWS EMR Hadoop cluster
In operation, segue has to perform a considerable amount of work to start up a remotely hosted EMR cluster. This includes requesting EC2 resources and utilizing S3 storage areas for the file transfer of the startup configuration and result collection. It's useful to look at the resources that are configured by segue using the AWS API through the AWS console that operates in the web browser. Using the AWS console can be critical to sorting out any problems that occur during the provisioning and running of the cluster. Ultimately, the AWS console is the last resort for releasing resources (and therefore limiting further expense) whenever segue processes go wrong, and occasionally, this does happen for many different reasons.
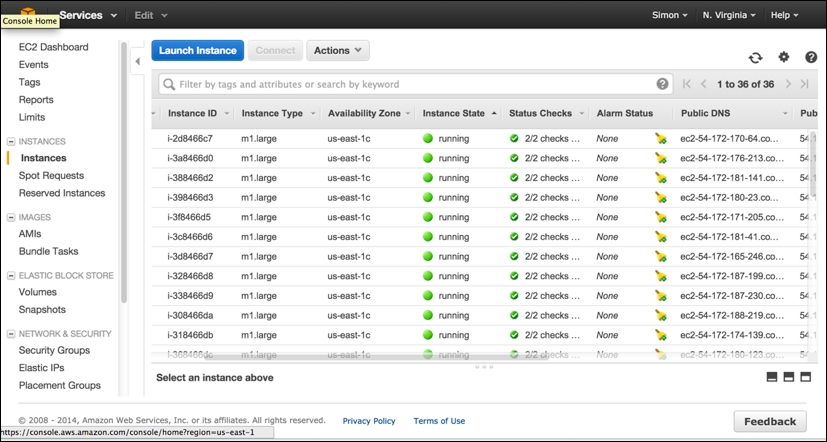
The following is the AWS console view of an EMR cluster that was created by segue. It just finished the emrlapply() parallel compute phase (you can see the step it just carried out , which took 34 minutes, in the center of the screen) and is now in the Waiting state, ready for more tasks to be submitted. You can note, to the lower-left, that it has one master and 15 core workers running as m1.large instances. You can also see that segue carried out two bootstrap actions on the cluster when it was created, installing the latest version of R and ensuring that all the R packages are up to date. Bootstrap actions obviously create extra overhead in readying the cluster for compute operations:
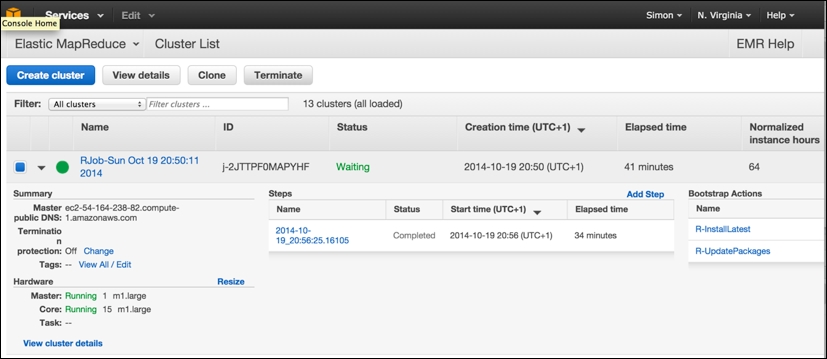
Note that it is from this screen that you can select an individual cluster and terminate it manually, freeing up the resources and preventing further charges, by clicking on the Terminate button.
EMR resources are made up of EC2 instances, and the following view shows the equivalent view of "Hardware" in terms of the individual EC2 running instances. They are still running, clocking up AWS chargeable CPU hours, even though they are idling and waiting for more tasks to be assigned. Although EMR makes use of EC2 instances, you should never normally terminate an individual EC2 instance within the EMR cluster from this screen; you should only use the Terminate cluster operation from the main EMR Cluster List option from the preceding screen.
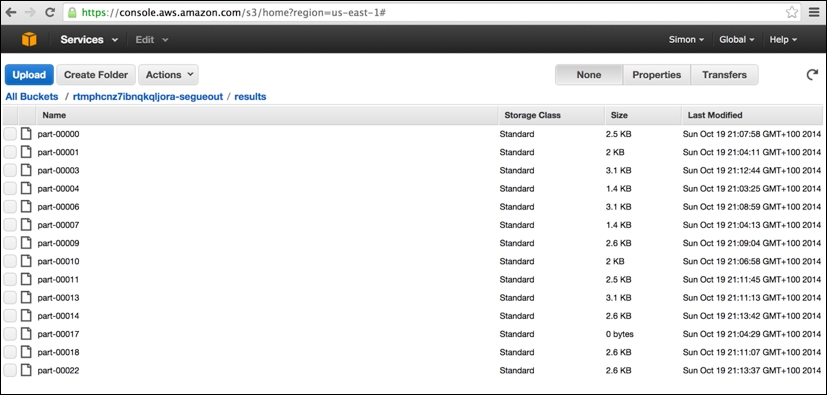
The final AWS console screen worth viewing is the S3 storage screen. The segue package creates three separate storage buckets (the name is prefixed with a unique random string), which, to all intents and purposes, can be thought of as three separate top-level directories in which various different types of files are held. These include a cluster-specific log directory (postfix: segue-logs), configuration directory (postfix: segue), and task results directory (postfix: segueout).
The following is a view of the results subdirectory within the segueout postfix folder associated with the cluster in the previous screens, showing the individual "part-XXXXX" result files being generated by the Hadoop worker nodes as they process the individual tasks:
At long last, we can now finally run our puzzle solver fully in parallel. Here, we chose to run the EMR cluster with 16 EC2 nodes, equating to one master node and 15 core worker nodes (all m1.large instances). It should be noted that there is significant overhead in both starting up the remote AWS EMR Hadoop cluster and in shutting it down again. Run the following code:
> setCredentials("<Access Key ID>","<Secret Access Key>") > > cluster <- createCluster(numInstances=16) STARTING - 2014-10-19 19:25:48 ## STARTING messages are repeated ~every 30 seconds until ## the cluster enters BOOTSTRAPPING phase. STARTING - 2014-10-19 19:29:55 BOOTSTRAPPING - 2014-10-19 19:30:26 BOOTSTRAPPING - 2014-10-19 19:30:57 WAITING - 2014-10-19 19:31:28 Your Amazon EMR Hadoop Cluster is ready for action. Remember to terminate your cluster with stopCluster(). Amazon is billing you! ## Note that the process of bringing the cluster up is complex ## and can take several minutes depending on size of cluster, ## amount of data/files/packages to be transferred/installed, ## and how busy the EC2/EMR services may be at time of request. > results <- emrlapply(cluster, tasks, FUN, taskTimeout=10) RUNNING - 2014-10-19 19:32:45 ## RUNNING messages are repeated ~every 30 seconds until the ## cluster has completed all of the tasks. RUNNING - 2014-10-19 20:06:46 WAITING - 2014-10-19 20:17:16 > stopCluster(cluster) ## Remember to save your bank balance! ## stopCluster does not generate any messages. If you are unable ## to run this successfully then you will need to shut the ## cluster down manually from within the AWS console (EMR).
Overall, the emrlapply() compute phase took around 34 minutes—not bad! However, the startup and shutdown phases took many minutes to run, making this aspect of overhead considerable. We could, of course, run more node instances (up to a maximum of 20 on AWS EMR currently), and we could use a more powerful instance type rather than just m1.large to speed up the compute phase further. However, such further experimentation I will leave to you, dear reader!
Tip
The AWS error in emrapply()
Very occasionally, the call to emrlapply() may fail with an error message of the following type:
Status Code: 404, AWS Service: Amazon S3, AWS Request ID: 5156824C0BE09D70, AWS Error Code: NoSuchBucket, AWS Error Message: The specified bucket does not exist…
This is a known problem with segue. The workaround is to disable your existing AWS credentials and generate a new pair of root security keys, manually terminate the AWS EMR cluster that was created by segue, restart your R session afresh, update your AWS keys in the call to setCredentials(), and then try again.
If we plot the respective elapsed time to compute the potential solution for each of the 90 starting tile-triples using R's built-in barplot() function, as can be noted in the following figure, then we will see some interesting features of the problem domain. Correct solutions found are indicated by the dark colored bars, and the rest are all fails.
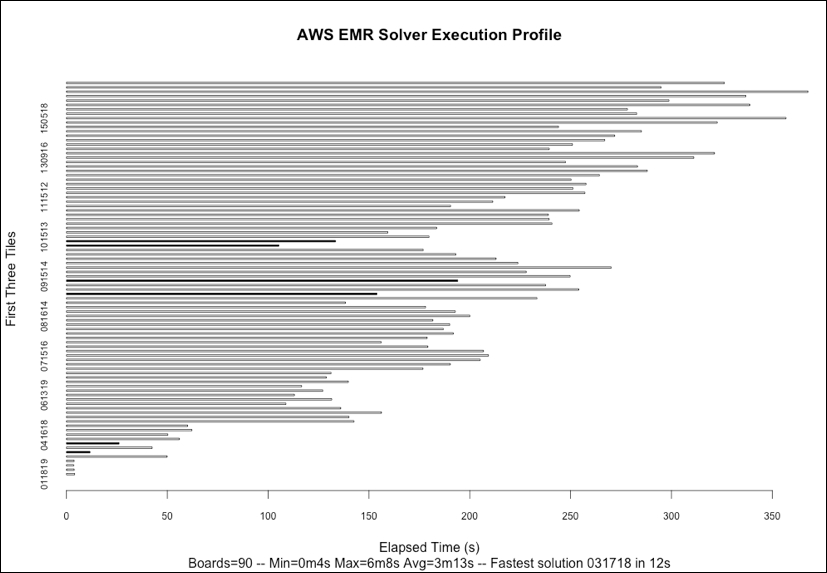
Firstly, we can note that we identified only six board-starting tile-triple configurations that result in a correct solution; I won't spoil the surprise by showing the solution here. Secondly, there is considerable variation in the time taken to explore the search space for each tile-triple with the extremes of 4 seconds and 6 minutes, with the fastest complete solution to the puzzle found in just 12 seconds. The computation is, therefore, very imbalanced, confirming what our earlier sample runs showed. There also appears to be a tendency for the time taken to increase the higher the value of the very first tile placed, something that warrants further investigation if, for example, we were keen to introduce heuristics to improve our solver's ability to choose the next best tile to place.
The cumulative computational time to solve all 90 board configurations was 4 hours and 50 minutes. In interpreting these results, we need to verify that the elapsed time is not adrift of user and system time combined. For the results obtained in this execution, there is a maximum of one percent difference in elapsed time compared to the user + system time. We would of course expect this as we are paying for dedicated resources in the AWS EMR Hadoop cluster spun up through segue.