

Let's gradually introduce how logistic regression works. We said that it's a classifier, but its name recalls a regressor. The element we need to join the pieces is the probabilistic interpretation.
In a binary classification problem, the output can be either "0" or "1". What if we check the probability of the label belonging to class "1"? More specifically, a classification problem can be seen as: given the feature vector, find the class (either 0 or 1) that maximizes the conditional probability:
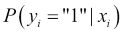
Here's the connection: if we compute a probability, the classification problem looks like a regression problem. Moreover, in a binary classification problem, we just need to compute the probability of membership of class "1", and therefore it looks like a well-defined regression problem. In the regression problem, classes are no longer "1" or "0" (as strings), but 1.0 and 0.0 (as the probability of belonging to class "1").
Let's now try fitting a multiple linear...