

In Chapter 4, Logistic Regression we explored a classifier based on a regressor, logistic regression. Its goal was to fit the best probabilistic function associated with the probability of one point to be classified with a label. Now, the core function of the algorithm considers all the training points of the dataset: what if it's only built on the boundary ones? That's exactly the case with the linear Support Vector Machine (SVM) classifier, where a linear decision plane is drawn by only considering the points close to the separation boundary itself.
Beyond working on the support vectors (the closest points to the boundary), SVM uses a new decision loss, called hinge. Here's its formulation:
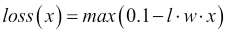
Where t is the intended label of the point x and w the set of weights in the classifier. The hinge loss is also sometimes called softmax, because it's actually a clipped max. In this formula, just the boundary points (that is, the support vectors) are used.
In the first...