

Statistical simulation is a numerical method for conducting experiments on a computer in order to solve mathematical problems in a data-driven manner.
Each experiment is carried out in two steps:
Drawing a random outcome.
The subsequent application of an estimation function to the drawn data.
Random draws are made by means of simulating random numbers, such as the numbers produced by a chosen random number generator.
Simulation is applied in different ways. It is applied in sampling to gather information about a random object by observing many realizations of it (Kroese et al., 2014).
As computational power keeps increasing, and new methods and algorithms are being developed, opportunities present themselves to not only conduct innovative research, but also to design better social and economic policies and programs through micro-simulation and agent-based modeling, where states change over time according to defined transition probabilities. Another example is the area of system dynamics, which describes the interaction of populations or individuals. Both topics are part of Chapter 11, System Dynamics and Agent-Based Models.
With simulation experiments, one can even show the concepts of probability theory and the basic theorems of statistics. The (weak and strong) law of large numbers can be explained. We may repeatedly do some experiments with related probability mechanisms. The outcomes of these experiments are random – random events have outcomes that are not known with certainty, but in the long run we know the properties. To toss coins is the simplest example. The most fundamental theorem in mathematical statistics, the central limit theorem, can also be shown by simulation. Using simulation experiments, readers will be able to fully understand this important theorem, while the proof with mathematics needs very detailed knowledge of mass and probability theory. More information on simulation to show the basics in statistics is provided in Chapter 6, Probability Theory Shown by Simulation.
Statistical simulation is also used to show the properties of an estimation method regarding different conditions. One example is the question of how an estimator behaves under different kinds of missing values pattern, or how outliers may corrupt the estimator. When samples have been drawn with complex sampling designs from finite populations, the influence of the sampling design on the estimator of interest can be shown with design-based simulations. Both model-based simulation and design-based simulation are shown in Chapter 10, Simulation with Complex Data. How data might be simulated for different kind of problems is also discussed. This covers the high-dimensional data and complex synthetic populations needed for design-based simulations.
Usually, when statisticians talk about simulations, they mean Monte Carlo simulations. The Monte Carlo simulation method uses repeated random sampling to mimic the null hypothesis or simulate data from a model where an estimation function is applied to the simulated data.
The Monte Carlo simulation approach is also essential in Bayesian statistics, where Markov chain Monte Carlo (MCMC) methods are used to sample parameter values from a posterior distribution (see also Kroese et al., 2014). This will be intensively discussed in Chapter 4, Simulation of Random Numbers. Generally, it is crucial to have an excellent random number generator at hand that allows you to simulate uniformly distributed values. Additionally, it is crucial to transform a uniform distribution into a distribution of interest. We can do this with inversion, rejection sampling, or MCMC methods; see also Chapter 4, Simulation of Random Numbers.
The Monte Carlo simulation approach is also central to estimating certain numerical quantities in general, but especially to estimate statistical uncertainty. It turns out (Chapter 6, Probability Theory Shown by Simulation) that almost no mathematics is used to express the statistical uncertainty for any complex estimator. The Monte Carlo simulation method is a data-driven and computational tool. It is the perfect tool for data scientists to make statistical inferences without getting lost in the world of mathematics.
Another application of Monte Carlo simulation is multi-dimensional integrals, which can be solved via Monte Carlo techniques, typically by drawing random numbers out of an interval at which the integral is defined. Closely related to this is numerical optimization. Here, the Monte Carlo approach can be used to first solve optimization problems with complicated objective functions using a stochastic approach. The aim to introduce randomness is to avoid to converge / trap into a local optima when searching for an optima in non-convex (or non-concave) optimization functions, (more on this in Chapter 5, Monte Carlo Methods for Optimization Problems).
The great thing about Monte Carlo simulation is that the procedure is simple, independent of the complexity of the estimator/estimation of interest. Doing even the most complicated Monte Carlo simulation can be broken down into simple steps:
Identify a mathematical model – the estimation you want to apply.
Define the parameters in your model.
Create random data according to those parameters. Typically, we generate independent data sets under the conditions of interest.
-
Simulate and analyze the output of your estimations. This is typically done by computing the numerical value of the estimator/test statistic. On the original data, this should be T(X). For each simulated data set we get
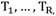 , that is, the numerical values of the estimator for each simulated data. If is large enough, the distribution of gives a good approximation of the true sampling distribution of the estimator/test. Moreover, the sample mean of the estimates is an estimate of the true mean. The 0,025 and 0,975 quantiles of this distribution is an estimator of the confidence interval of the point estimate from T(X).
, that is, the numerical values of the estimator for each simulated data. If is large enough, the distribution of gives a good approximation of the true sampling distribution of the estimator/test. Moreover, the sample mean of the estimates is an estimate of the true mean. The 0,025 and 0,975 quantiles of this distribution is an estimator of the confidence interval of the point estimate from T(X).
Generally speaking, with Monte Carlo simulation we approximate the sampling distribution of an estimator or test statistic. The particular set of related conditions are usually parameters fitted from the original data and conditions from a null hypothesis. With Monte Carlo simulations, we can successfully express the statistical uncertainty of an estimator or receive the relevant values (for example, the p-value) of a hypothesis test.