

By now you have been introduced to the notion of Big Data, its features, and its characteristics, as well as the most widely used Big Data analytics tools and frameworks such as Hadoop, HDFS, MapReduce framework, relational and non-relational databases, and Apache Spark project. They will be explored more thoroughly in the next few chapters of this book, but now the time has finally come to present the true hero and the main subject of this book-the R language. Although R as a separate language on its own has been with us since the mid 90s, it is derived from a more archaic S language developed by John Chambers in the mid 1970s. During Chambers' days in Bell Laboratories, one of the goals of his team was to design a user-friendly, interactive, and quick-in-deployment interface for statistical analysis and data visualizations. As they frequently had to deal with non-standard data analyses, and different data formats, the flexibility of this new tool, and its ability to make the most of the previously used Fortran algorithms, were the highest-order priorities. Also, the project was developed to implement certain graphical capabilities in order to visualize the outputs of numeric computations. The first version was run on a Honeywell operated machine, which wasn't the ideal platform, owing to a number of limitations and impracticalities.
The continuous work on S language progressed quite quickly and by 1981 Chambers and his colleagues were able to release a Unix implementation of the S environment along with a first book-cum-manual titled S: A Language and System for Data Analysis. In fact S was a hybrid-an environment or an interface allowing access to Fortran-based statistical algorithms through a set of built-in functions, operating on data with the flexibility of custom programmable syntax, for those users who wished to go beyond default statistical methods and implement more sophisticated computations. This hybrid, quasi object-oriented and functional programming language-like, statistical computing tool created a certain amount of ambiguity and confusion, even amongst its original developers. It is a well-known story that John Chambers, Richard Becker, and other Bell Labs engineers working on S at that time had considerable problems in categorizing their software as either a programming language, a system, or an environment. More importantly, however, S found a fertile ground in Academia and statistical research, which resulted in a sharp increase in external contributions from a growing community of S users. Future versions of S would enhance the functional and object-based structure of the S environment by allowing users to store their data, subsets, outputs of the computations, and even functions and graphs as separate objects. Also, since the third release of S in 1986, the core of the environment has been written in the C language, and the interface with Fortran modules has become accessible dynamically through the evaluator directly from S functions, rather than through a preprocessor and compilation, which was the case in the earlier versions. Of course, the new releases of the modernized and polished S environment were followed by a number of books authored by Chambers, Becker, and now also Allan Wilks, in which they explained the structure of the S syntax and frequently used statistical functions. The S environment laid the foundations for the R programming language, which has been further redesigned in 1990s by Robert Gentleman and Ross Ihaka from the University of Auckland in New Zealand. Despite some differences (a comprehensive list of differences between the S and R languages is available at https://cran.r-project.org/doc/FAQ/R-FAQ.html#R-and-S ), the code written in the S language runs almost unaltered in the R environment. In fact R and also the S-Plus language are the implementations of S-in its more evolved versions, and it is advisable to treat them as such. Probably the most striking difference between S and R, comes from the fact that R blended in an evaluation model based on the lexical scoping adopted from Steele and Sussman's Scheme programming language. The implementation of lexical scoping in R allowed you to assign free variables, depending on the environment in which a function referencing such variables was created, whereas in S free variables could have only been defined globally. The evaluation model used in R meant that the functions, in comparison with S, were more expressive and written in a more natural way giving the developers or analysts more flexibility and greater capabilities by defining variables specific to particular functions within their own environments. The link provided earlier, lists other minor, or very subtle, differences between both languages-many of which are sometimes not very apparent unless they are explicitly referred to in error messages when attempting to run a line of R code.
Currently, R comes in various shapes or forms, as there are several open source and commercial implementations of the language. The most popular, and the ones used throughout this book, are the free R GUI available to download from the R Project CRAN website at https://cran.r-project.org/ and our preferred and also free-of-charge RStudio IDE available from https://www.rstudio.com/ . Owing to their popularity and functionalities, both implementations deserve a few words of introduction.
The most generic R implementation is a free, open source project managed and distributed by the R Foundation for Statistical Computing headquartered in Vienna (Austria) at the Institute for Statistics and Mathematics. It is a not-for-profit organization, founded and set up by the members of the R Development Core Team, which includes a number of well-known academics in statistical research, R experts, and some of the most prolific R contributors over the past several years. Amongst its members, there are still the original fathers of the S and R languages such as John Chambers, Robert Gentleman, and Ross Ihaka, as well as the most influential R developers: Dirk Eddelbuettel, Peter Dalgaard, Bettina Grun, and Hadley Wickham to mention just a few. The team is responsible for the supervision and the management of the R core source code, approval of changes and alterations to the source code, and the implementation of community contributions. Through the web pages of the Comprehensive R Archive Network (CRAN) ( https://cran.r-project.org/ ), the R Development Core Team releases new versions of the R base installation and publishes recent third-party packages created by independent R developers and R community members. They also release research-oriented, open access, refereed periodic R Journals, and organize extremely popular annual useR! conferences, which regularly gather hundreds of passionate R users from around the world.
The R core is the basis for enterprise-ready open source and commercial license products developed by RStudio operating from Boston, MA and led by the Chief Scientist Dr. Hadley Wickham-a creator of numerous crucial data analysis and visualization packages for R, for example, ggplot2, rggobi, plyr, reshape, and many more. Their IDE is probably the best and most user-friendly R interface currently available to R users, and if you still don't have it, we recommend that you install it on your personal computer as soon as possible. The RStudio IDE consists of an easy-to-navigate workspace view, with a console window, and an editor, equipped with code highlighting and a direct code execution facility, as well as additional views allowing user-friendly control over plots and visualizations, file management within and outside the working directory, core and third-party packages, history of functions and expressions, management of R objects, code debugging functionalities, and also a direct access to help and support files.
As the R core is a multi-platform tool, RStudio is also available to users of the Windows, Mac, or Linux operating systems. We will be using RStudio desktop edition as well as the open source version of the RStudio Server throughout this book extensively, so please make sure you download and install the desktop free version on your machine in order to be able to follow some of the examples included in Chapter 2, Introduction to R Programming Language and Statistical Environment and Chapter 3, Unleashing the Power of R from Within. When we get to cloud computing (Online Chapter, Pushing R Further, https://www.packtpub.com/sites/default/files/downloads/5396_6457OS_PushingRFurther.pdf) we will explain how to install and use RStudio Server on a Linux run server.
The following are screenshots of graphical user interfaces (on Mac OS X) of both the R base installation, available from CRAN, and the RStudio IDE for desktop. Please note that for Windows users, GUIs may look a little different than the attached examples; however, the functionalities remain the same in most cases. RStudio Server has the same GUI as the desktop version; there are however some very minor differences in available options and settings:

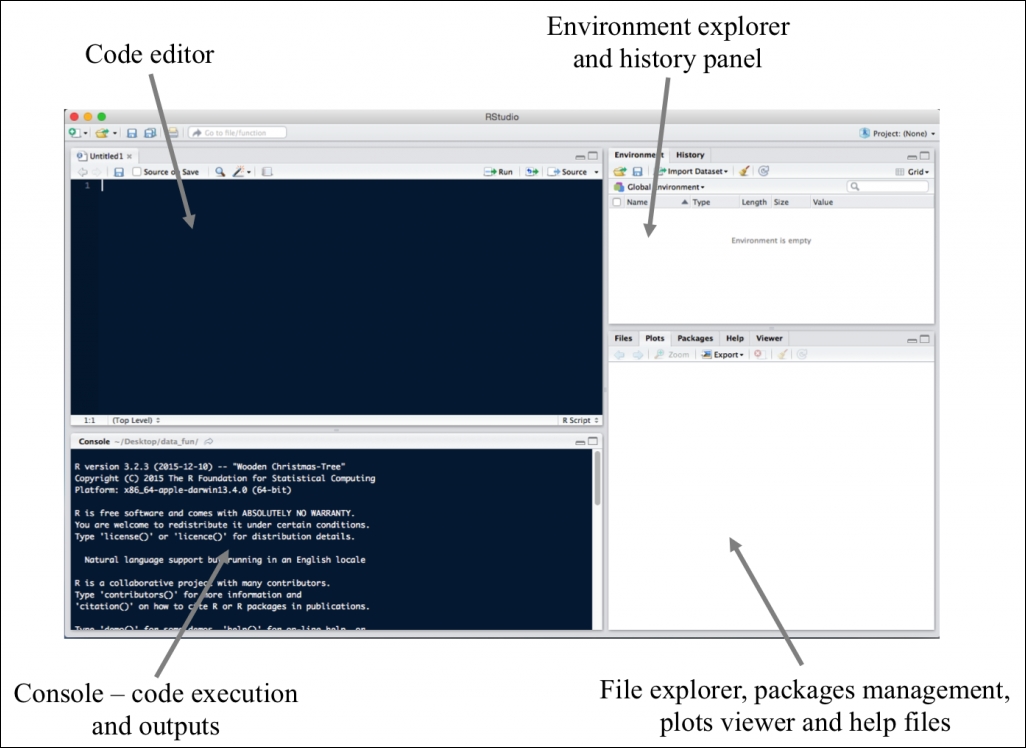
After many years of R being used almost exclusively in Academia and research, recent years have witnessed an increased interest in the R language coming from business customers and the financial world. Companies such as Google and Microsoft have turned to R for its high flexibility and simplicity of use. In July 2015, Microsoft completed the acquisition of Revolution Analytics-a Big Data and predictive analytics company that gained its reputation for their own implementations of R with built-in support for Big Data processing and analysis.
Note
The exponential growth in popularity of the R language made it one of the 20 most commonly used programming languages according to TIOBE Programming Community Index in years 2014 and 2015 (http://www.tiobe.com/index.php/content/paperinfo/tpci/index.html). Moreover KDnuggets (http://www.kdnuggets.com/)-a leading data mining and analytics blog, listed R as one of the essential must-have skills for a career in data science along with knowledge of Python and SQL.
The growth of R does not surprise. Thanks to its vibrant and talented community of enthusiastic users, it is currently the world's most widely-used statistical programming language with nearly 8,400 third-party packages available in the CRAN (as of June 2016) and many more libraries featured on BioConductor, Forge.net, and other repositories, not to mention hundreds of packages under development on GitHub, as well as many other unachieved and accessible only through the personal blogs and websites of individual researchers and organizations.
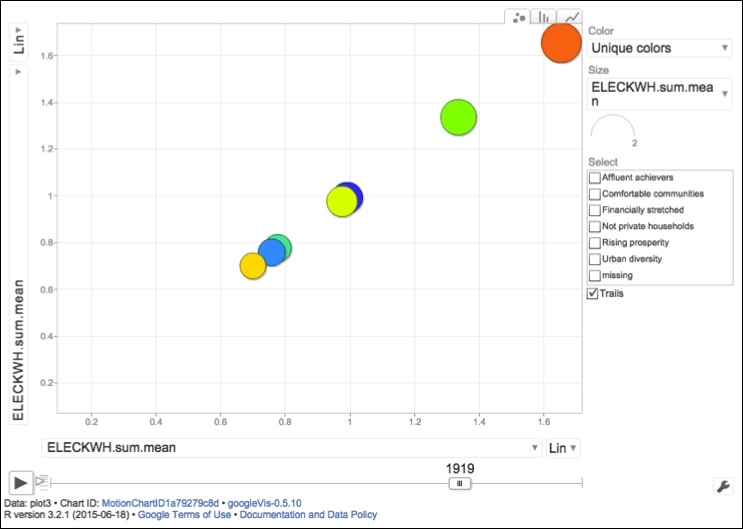
Apart from the obvious selling points of the R language, such as its open source license, a lack of any setup fees, unlimited access to a comprehensive set of ready-made statistical functions, and a highly active community of users, R is also widely praised for its data visualization capabilities and ability to work with data of many different formats. Popular and very influential newspapers and magazines such as the Washington Post, Guardian, the Economist, or the New York Times, use R on a daily basis to produce highly informative diagrams and info graphics, in order to explain complex political events or social and economical phenomena. The availability of static graphics through extremely powerful packages such as ggplot2 or lattice, has lately been extended even further to offer interactive visualizations using the shiny or ggobi frameworks, and a number of external packages (for example rCharts created and maintained by Ramnath Vaidyanathan) that support JavaScript libraries for spatial analysis, for example leaflet.js, or interactive data-driven documents through morris.js, D3.js, and others. Moreover, R users can now benefit from Google Visualization API charts, such as the famous motion graph, directly through googleVis package developed by Markus Gesmann, Diego de Castillo, and Joe Cheng (the following screenshot shows that googleVis package in action):
As mentioned earlier, R works with data coming from a large array of different sources and formats. This is not just limited to physical file formats such as traditional comma-separated or tab-delimited formats, but it also includes less common files such as JSON (a widely used format in web applications and modern NoSQL databases and that we will explore in detail in Chapter 6, R with Non-Relational and (NoSQL) Databases) or images, other statistical packages and proprietary formats such as Excel workbooks, Stata, SAS, SPSS, and Minitab files, scrapping data from the Internet, or direct access to SQL or NoSQL databases as well as other Big Data containers (such as Amazon S3), or files stored in the HDFS. We will explore most of the data import capabilities of R in a number of real-world examples throughout this book. However if you would like to get a feel for a variety of data import methods in R right now, please visit the CRAN page at https://cran.r-project.org/manuals.html, which lists a set of the most essential manuals including the R Data Import/Export document outlining the import and export methods of data to and from R.
Finally, the code in the R language can easily be called from other programming platforms such as Python or Julia. Moreover, R itself is able to implement functions and statements from other programming languages such as the C family, Java, SQL, Python, and many others. This allows for greater veracity and helps to integrate the R language into existing data science workflows. We will explore many examples of such implementations throughout this book.