

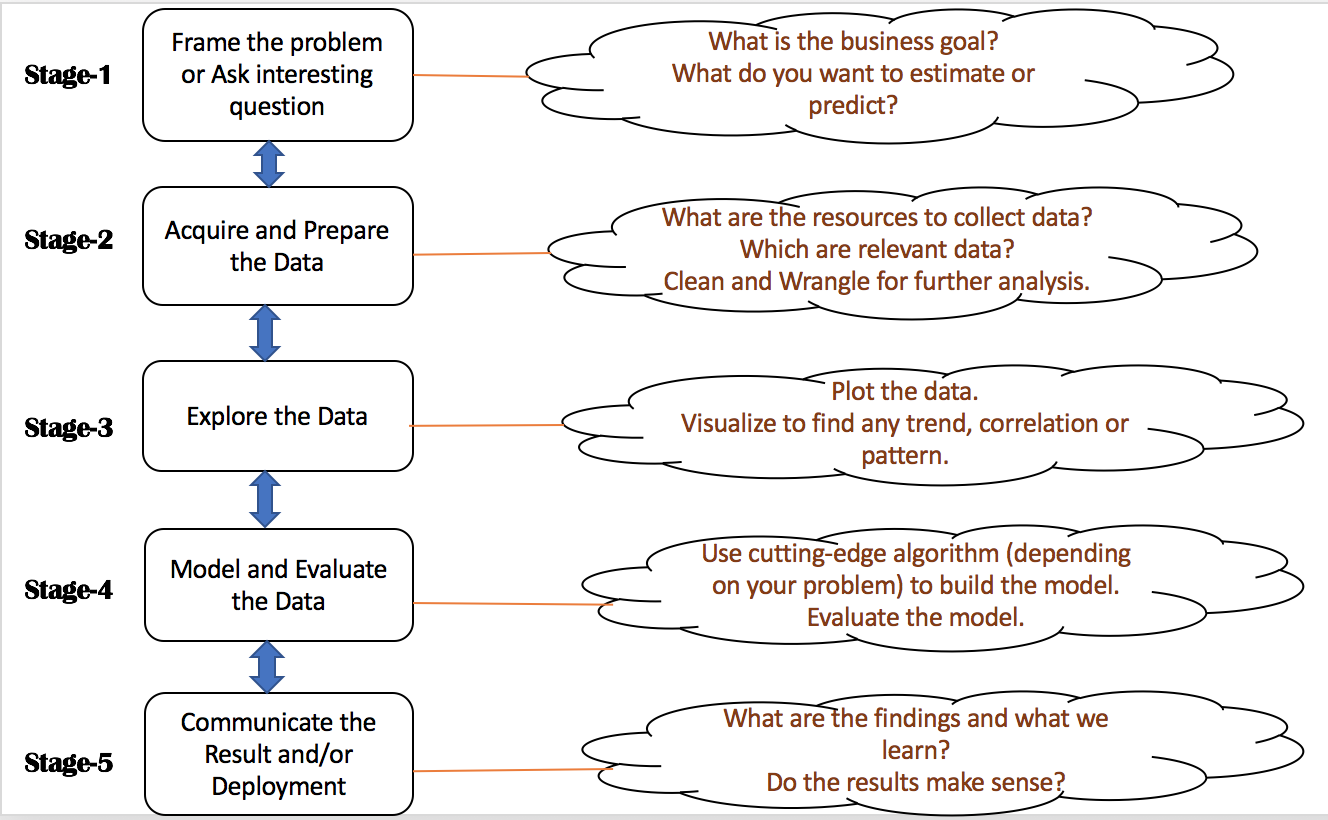
Data is everywhere and the amount of digital data that exists is growing rapidly, that is projected to grow to 180 zettabytes by 2025. Data Science is a field that tries to extract insights and meaningful information from structured and unstructured data through various stages such as asking questions, getting the data, exploring the data, modeling the data, and communicating result as shown in the following diagaram:
Data scientists or analysts often need to load or collect data from various resources having different input formats into R. Although R has its own native data format, data usually exists in text formats, such as Comma Separated Values (CSV), JavaScript Object Notation (JSON), and Extensible Markup Language (XML). This chapter provides recipes to load such data into your R system for processing.
Raw, real-world datasets are often messy with missing values, unusable format, and outliers. Very rarely can we start analyzing data immediately after loading it. Often, we will need to preprocess the data to clean, impute, wrangle, and transform it before embarking on analysis. This chapter provides recipes for some common cleaning, missing value imputation, outlier detection, and preprocessing steps.