

Deep Neural Network (DNN): This can be defined as a multilayer perceptron with many hidden layers. All the weights of the layers are fully connected to each other, and receive connections from the previous layer. The weights are initialized with either supervised or unsupervised learning.
Recurrent Neural Networks (RNN): RNN is a kind of deep learning network that is specially used in learning from time series or sequential data, such as speech, video, and so on. The primary concept of RNN is that the observations from the previous state need to be retained for the next state. The recent hot topic in deep learning with RNN is Long short-term memory (LSTM).
Deep belief network (DBN): This type of network [9] [10] [11] can be defined as a probabilistic generative model with visible and multiple layers of latent variables (hidden). Each hidden layer possesses a statistical relationship between units in the lower layer through learning. The more the networks tend to move to higher layers, the more complex relationship becomes. This type of network can be productively trained using greedy layer-wise training, where all the hidden layers are trained one at a time in a bottom-up fashion.
Boltzmann machine (BM): This can be defined as a network that is a symmetrically connected, neuron-like unit, which is capable of taking stochastic decisions about whether to remain on or off. BMs generally have a simple learning algorithm, which allows them to uncover many interesting features that represent complex regularities in the training dataset.
Restricted Boltzmann machine (RBM): RBM, which is a generative stochastic Artificial Neural Network, is a special type of Boltzmann Machine. These types of networks have the capability to learn a probability distribution over a collection of datasets. An RBM consists of a layer of visible and hidden units, but with no visible-visible or hidden-hidden connections.
Convolutional neural networks: Convolutional neural networks are part of neural networks; the layers are sparsely connected to each other and to the input layer. Each neuron of the subsequent layer is responsible for only a part of the input. Deep convolutional neural networks have accomplished some unmatched performance in the field of location recognition, image classification, face recognition, and so on.
Deep auto-encoder: A deep auto-encoder is a type of auto-encoder that has multiple hidden layers. This type of network can be pre-trained as a stack of single-layered auto-encoders. The training process is usually difficult: first, we need to train the first hidden layer to restructure the input data, which is then used to train the next hidden layer to restructure the states of the previous hidden layer, and so on.
Gradient descent (GD): This is an optimization algorithm used widely in machine learning to determine the coefficient of a function (f), which reduces the overall cost function. Gradient descent is mostly used when it is not possible to calculate the desired parameter analytically (for example, linear algebra), and must be found by some optimization algorithm.
In gradient descent, weights of the model are incrementally updated with every single iteration of the training dataset (epoch).
The cost function, J (w), with the sum of the squared errors can be written as follows:
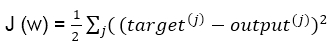
The direction of magnitude of the weight update is calculated by taking a step in the reverse direction of the cost gradient, as follows:
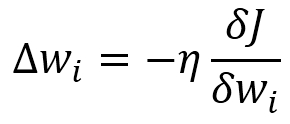
In the preceding equation, η is the learning rate of the network. Weights are updated incrementally after every epoch with the following rule:
for one or more epochs,
for each weight i,
wi:= w + ∆wi
end
end
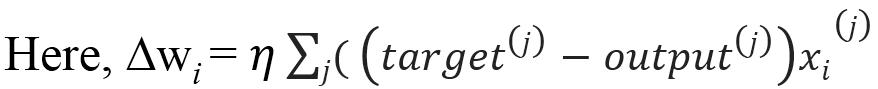
Popular examples that can be optimized using gradient descent are Logistic Regression and Linear Regression.
Stochastic Gradient Descent (SGD): Various deep learning algorithms, which operated on a large amount of datasets, are based on an optimization algorithm called stochastic gradient descent. Gradient descent performs well only in the case of small datasets. However, in the case of very large-scale datasets, this approach becomes extremely costly . In gradient descent, it takes only one single step for one pass over the entire training dataset; thus, as the dataset's size tends to increase, the whole algorithm eventually slows down. The weights are updated at a very slow rate; hence, the time it takes to converge to the global cost minimum becomes protracted.
Therefore, to deal with such large-scale datasets, a variation of gradient descent called stochastic gradient descent is used. Unlike gradient descent, the weight is updated after each iteration of the training dataset, rather than at the end of the entire dataset.
until cost minimum is reached
for each training sample j:
for each weight i
wi:= w + ∆wi
end
end
end
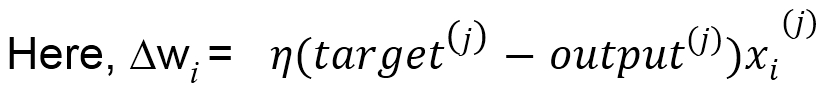
In the last few years, deep learning has gained tremendous popularity, as it has become a junction for research areas of many widely practiced subjects, such as pattern recognition, neural networks, graphical modelling, machine learning, and signal processing.
The other important reasons for this popularity can be summarized by the following points:
In recent years, the ability of GPU (Graphical Processing Units) has increased drastically
The size of data sizes of the dataset used for training purposes has increased significantly
Recent research in machine learning, data science, and information processing has shown some serious advancements
Detailed descriptions of all these points will be provided in an upcoming topic in this chapter.