

We have looked at the components of spark framework, its advantages/disadvantages, and the scenarios where it best fits in solution design. In the following section, we will delve deeper into the internals of Spark, its architectural abstractions, and workings. Spark works in a master salve model and the following diagram shows the layered architecture for it:
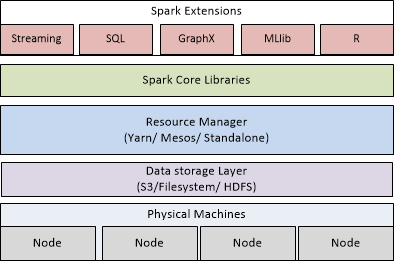
If we start bottom up from the layered architecture depicted in the preceding diagram:
- The physical machines or the nodes are abstracted by a data storage layer (that could a HDFS/distributed file system/AWS S3). This data storage layer provides the APIs for storage and retrieval of final/intermediate data sets generated during the execution.
- The resource manager layer on top of the data storage obfuscates the underlying storage and resource orchestration from spark set up and execution model, thus providing the users a spark setup that could leverage any of the available resource managers...