

Errors need to be evaluated in order to measure the effectiveness of the model in order to improve the model's performance further by tuning various knobs. Error components consist of a bias component, variance component, and pure white noise:
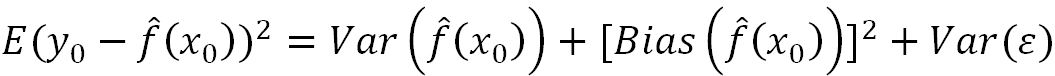
Out of the following three regions:
- The first region has high bias and low variance error components. In this region, models are very robust in nature, such as linear regression or logistic regression.
- Whereas the third region has high variance and low bias error components, in this region models are very wiggly and vary greatly in nature, similar to decision trees, but due to the great amount of variability in the nature of their shape, these models tend to overfit on training data and produce less accuracy on test data.
- Last but not least, the middle region, also called the second region, is the ideal sweet spot, in which both bias and variance components are moderate, causing it to create...