

Another approach to the same problem is offered by the TSVM, proposed by T. Joachims (in Transductive Inference for Text Classification using Support Vector Machines, Joachims T., ICML Vol. 99/1999). The idea is to keep the original objective with two sets of slack variables: the first for the labeled samples and the other for the unlabeled ones:
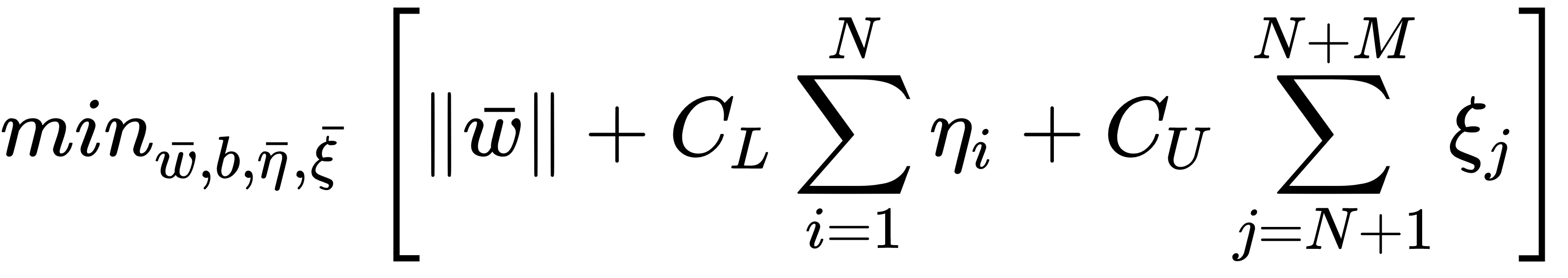
As this is a transductive approach, we need to consider the unlabeled samples as variable-labeled ones (subject to the learning process), imposing a constraint similar to the supervised points. As for the previous algorithm, we assume we have N labeled samples and M unlabeled ones; therefore, the conditions become as follows:
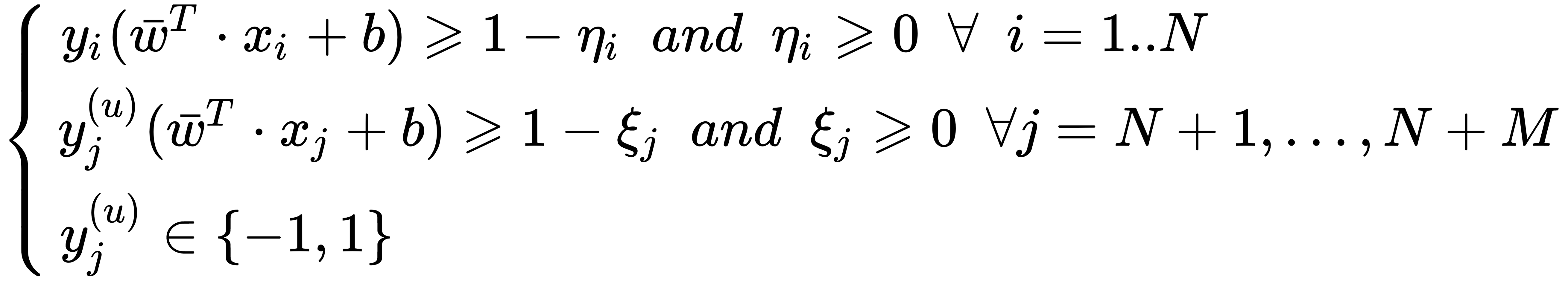
The first constraint is the classical SVM one and it works only on labeled samples. The second one uses the variable y(u)j with the corresponding slack variables ξj to impose a similar condition on the unlabeled samples, while the third one is necessary to constrain the labels to being...