

If you choose to install Splunk on a Linux machine, these are the instructions you need to follow. Take your time and do not rush the installation. For this Linux installation, the steps assume you will run Splunk in your user profile's home directory:
- Decompress the .tgz file you downloaded. The result of the decompression is a splunk folder and all the related Splunk files contained inside.
- Change the working directory to $SPLUNK_HOME/bin.
- Run the following command to start Splunk for the first time:
./splunk start
- Accept the Splunk license when prompted.
- Splunk will start successfully and the end results should appear like this:
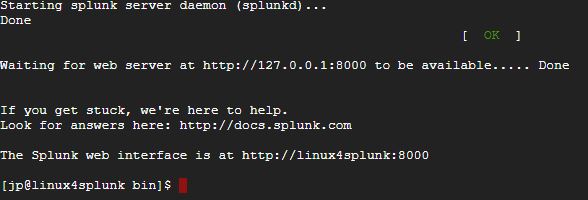
Tip from the Fez: In most organizational environments, it is common to install Splunk in /opt/. When installing on Linux, it is best practice to adjust the ulimit settings and disable transparent hugh page functionality for Splunk applications that will be loading data in real time, supporting a community of users.
Tip from the Fez: Unlike Windows installations, Splunk Linux installations aren't automatically configured to start upon reboot of the Splunk server. Ensure that you configure your Splunk instance on Linux for what is known as boot start so that if the Linux instance is restarted, Splunk will automatically restart with the operating system.
Tip from the Fez: In an enterprise environment, create a Linux user specifically for running Splunk and use that. Do not run Splunk as the Linux root user or an individuals user.


