

Principle component analysis (PCA) is a linear and deterministic algorithm that tries to capture similarities within the data. Once similarities are found, it can be used to remove unnecessary dimensions from high-dimensional data. It works using the concepts of eigenvectors and eigenvalues. A simple example will help you understand eigenvectors and eigenvalues, given that you have a basic understanding of the matrix:
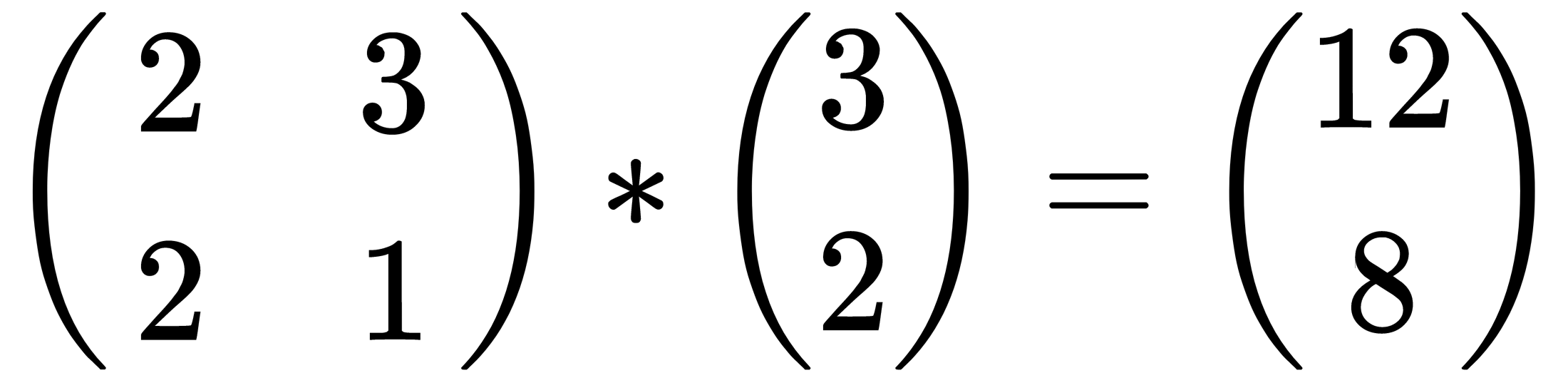
This is equivalent to the following:

This is the case of eigenvector, and 4 is the eigenvalue.
The PCA approach is simple. It starts with subtracting the mean from the data; then, it finds the covariance matrix and calculates its eigenvectors and eigenvalues. Once you have the eigenvector and eigenvalue, order them from highest to lowest and thus now we can ignore the component with less significance. If the eigenvalues are small, the loss is negligible. If you have data with n dimensions and you calculate n eigenvectors and eigenvalues, you can select...