

K-means is a clustering algorithm that tries to cluster related data points together. However, we should know its working principle and mathematical operations.
Suppose we have n data points, xi, i = 1...n, that need to be partitioned into k clusters. Now that the target here is to assign a cluster to each data point, K-means aims to find the positions, μi, i=1...k, of the clusters that minimize the distance from the data points to the cluster. Mathematically, the K-means algorithm tries to achieve the goal by solving an equation that is an optimization problem:
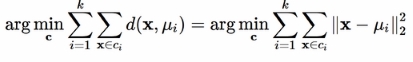
In the previous equation, ci is a set of data points, which when assigned to cluster i and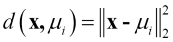 is the Euclidean distance to be calculated (we will explain why we should use this distance measurement shortly). Therefore, we can see that the overall clustering operation using K-means is not a trivial one, but a NP-hard optimization problem. This also means that the K-means algorithm...
is the Euclidean distance to be calculated (we will explain why we should use this distance measurement shortly). Therefore, we can see that the overall clustering operation using K-means is not a trivial one, but a NP-hard optimization problem. This also means that the K-means algorithm...