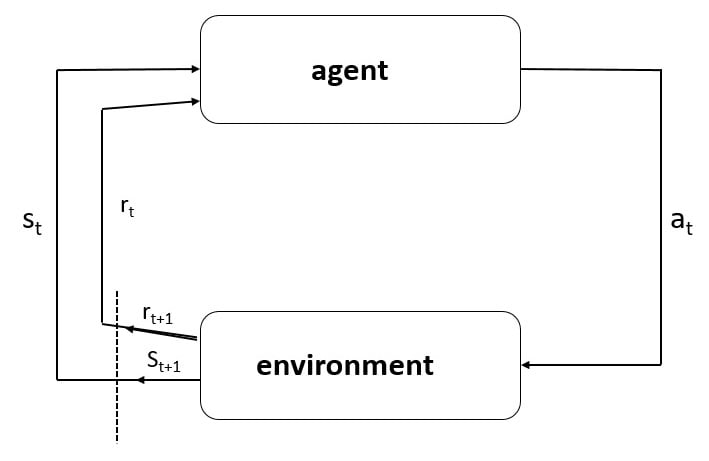
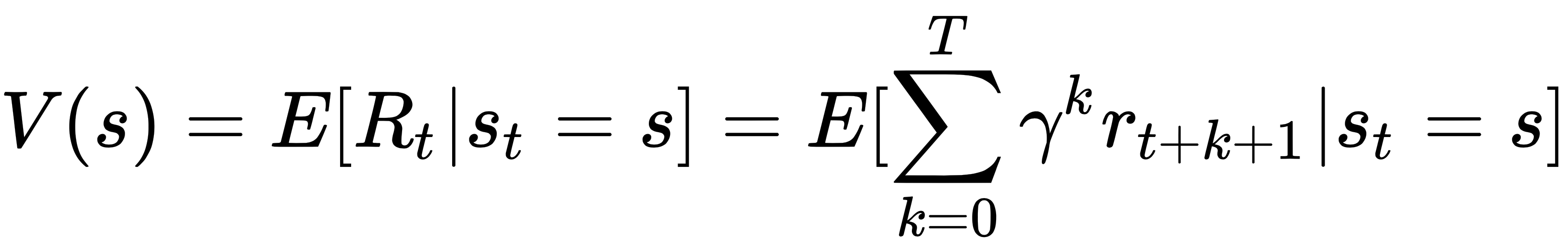At a very basic level, RL involves an agent and an environment. An agent is an artificial intelligence entity that has certain goals, must remain vigilant about things that can come in the way of these goals, and must, at the same time, pursue the things that help in the attaining of these goals. An environment is everything that the agent can interact with. Let me explain further with an example that involves an industrial mobile robot.
For example, in a setting involving an industrial mobile robot navigating inside a factory, the robot is the agent, and the factory is the environment.
The robot has certain pre-defined goals, for example, to move goods from one side of the factory to the other without colliding with obstacles such as walls and/or other robots. The environment is the region available for the robot to navigate and includes all the places the robot can go to, including the obstacles that the robot could crash in to. So the primary task of the robot, or more precisely, the agent, is to explore the environment, understand how the actions it takes affects its rewards, be cognizant of the obstacles that can cause catastrophic crashes or failures, and then master the art of maximizing the goals and improving its performance over time.
In this process, the agent inevitably interacts with the environment, which can be good for the agent regarding certain tasks, but could be bad for the agent regarding other tasks. So, the agent must learn how the environment will respond to the actions that are taken. This is a trial-and-error learning approach, and only after numerous such trials can the agent learn how the environment will respond to its decisions.
Let's now come to understand what the state space of an agent is, and the actions that the agent performs to explore the environment.