

Matching networks are yet another simple and efficient one-shot learning algorithm published by Google's DeepMind team. It can even produce labels for the unobserved class in the dataset.
Let's say we have a support set, S, containing K examples as
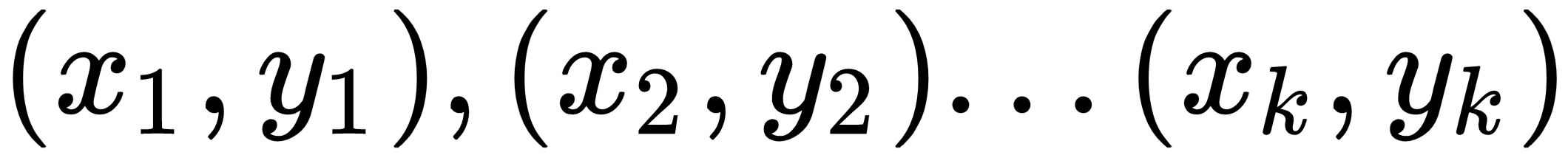
. When given a query point (a new unseen example),

, the matching network predicts the class of

by comparing it with the support set.
We can define this as
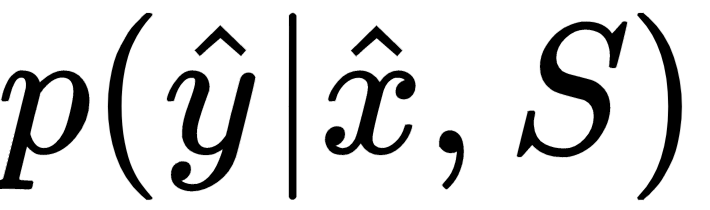
, where
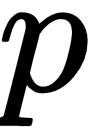
is the parameterized neural network,
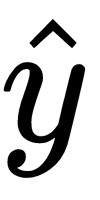
is the predicted class for the query point,

, and
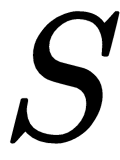
is the support set.
will return the probability of

belonging to each of the classes in the dataset. Then, we select the class of

as the one that has the highest probability. But how does this work exactly? How is this probability computed? Let's us see that now.
The output,
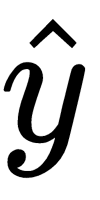
, for the query point,

, can be predicted as follows:
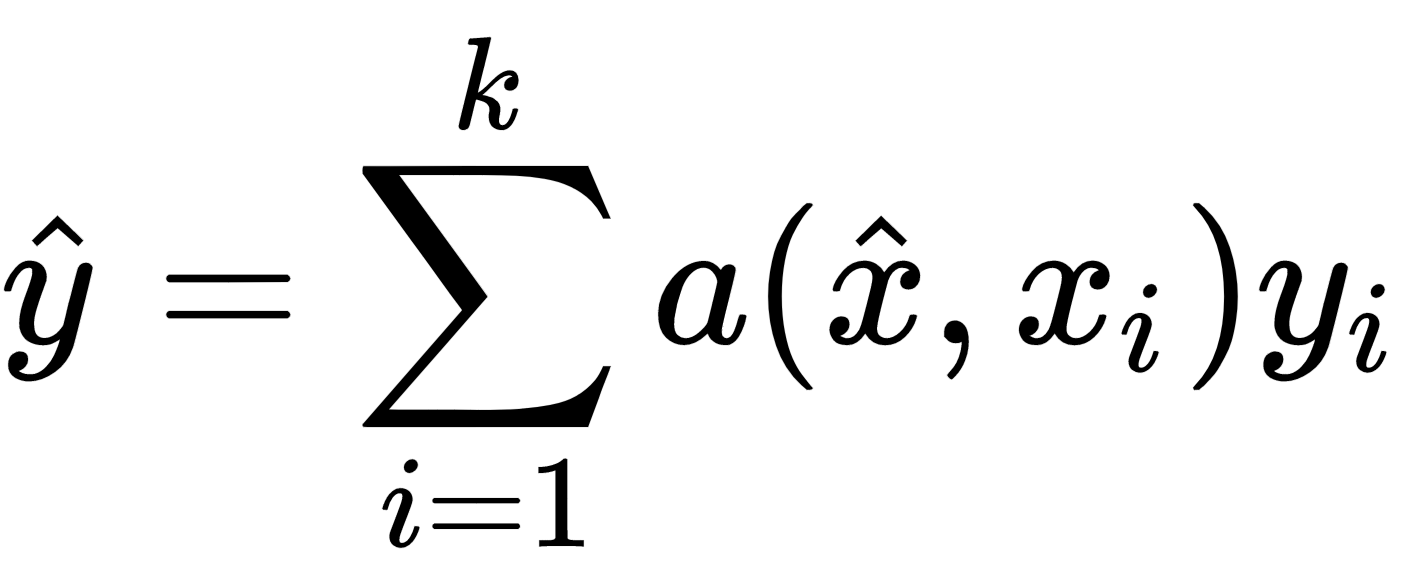
Let's decipher this equation.
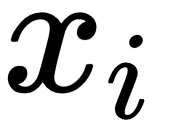
and
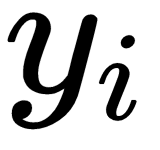
are the input and labels of the support set.

is the query input— the input to which we want to predict the label....