

Let's say we have some task, T. We use a model,
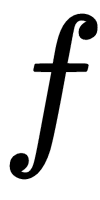
, parameterized by some parameter,
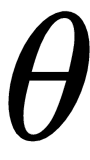
, and train the model to minimize the loss. We minimize the loss using gradient descent and find the optimal parameter
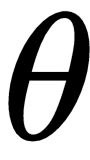
for the model.
Let's recall the update rule of a gradient descent:

So, what are the key elements that make up our gradient descent? Let's see:
- Parameter

- Learning rate

- Update direction
We usually set the parameter
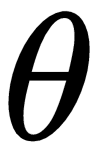
to some random value and try to find the optimal value during our training process, and we set the value of learning rate

to a small number or decay it over time and an update direction that follows the gradient. Can we learn all of these key elements of the gradient descent by meta learning so that we can learn quickly from a few data points? We've already seen, in the last chapter, how MAML finds the optimal initial parameter
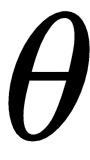
that's generalizable across tasks. With the optimal initial parameter, we can take fewer gradient steps and learn quickly on a new task.
So, now can...