

The main objective of this chapter is to see how machine learning helps detect cancer through the SVM and KNN models. The following screenshot is an example of the final output that we are trying to achieve in this project:
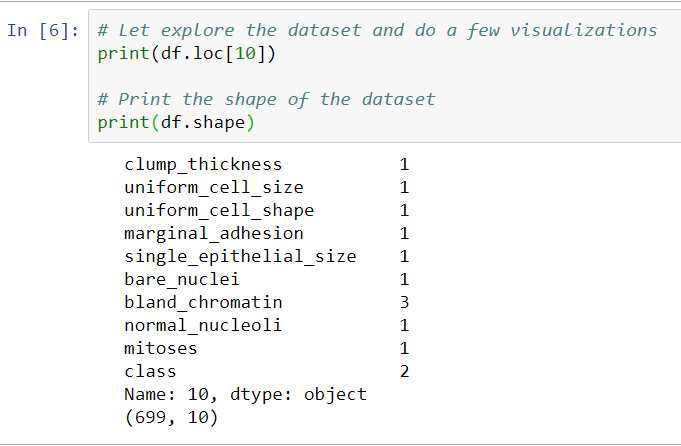
We will receive the information shown in the preceding screenshot for approximately 700 cells in our dataset. This will include factors such as clump_thickness, marginal_adhesion, bare_nuclei, bland_chromatin, and mitoses, all of which are properties that would be valuable for a pathologist. In the screenshot, you can see that the class is 4, which means that it is malignant; so, this particular cell is cancerous. A class of 2, on the other hand, would be benign, or healthy.
Now, let's take a look at the models that we will be training as the chapter progresses in the following screenshot:
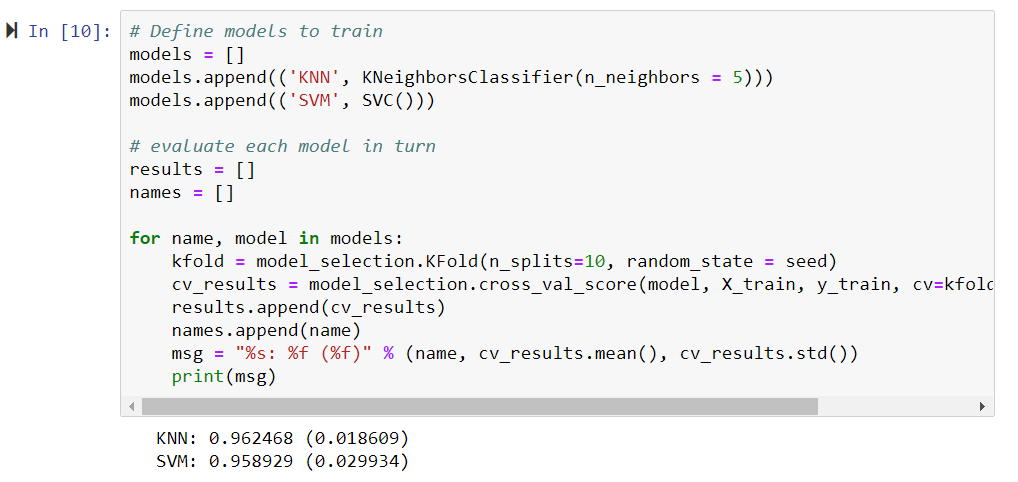
Based on the cell's information, both models have predicted that the cell is cancerous, or malignant. In this project, we will go through the steps required to achieve this goal. We will start by downloading and installing packages with Anaconda, we will move on to starting a Jupyter Notebook, and then you will learn how to program these machine learning models in Python.