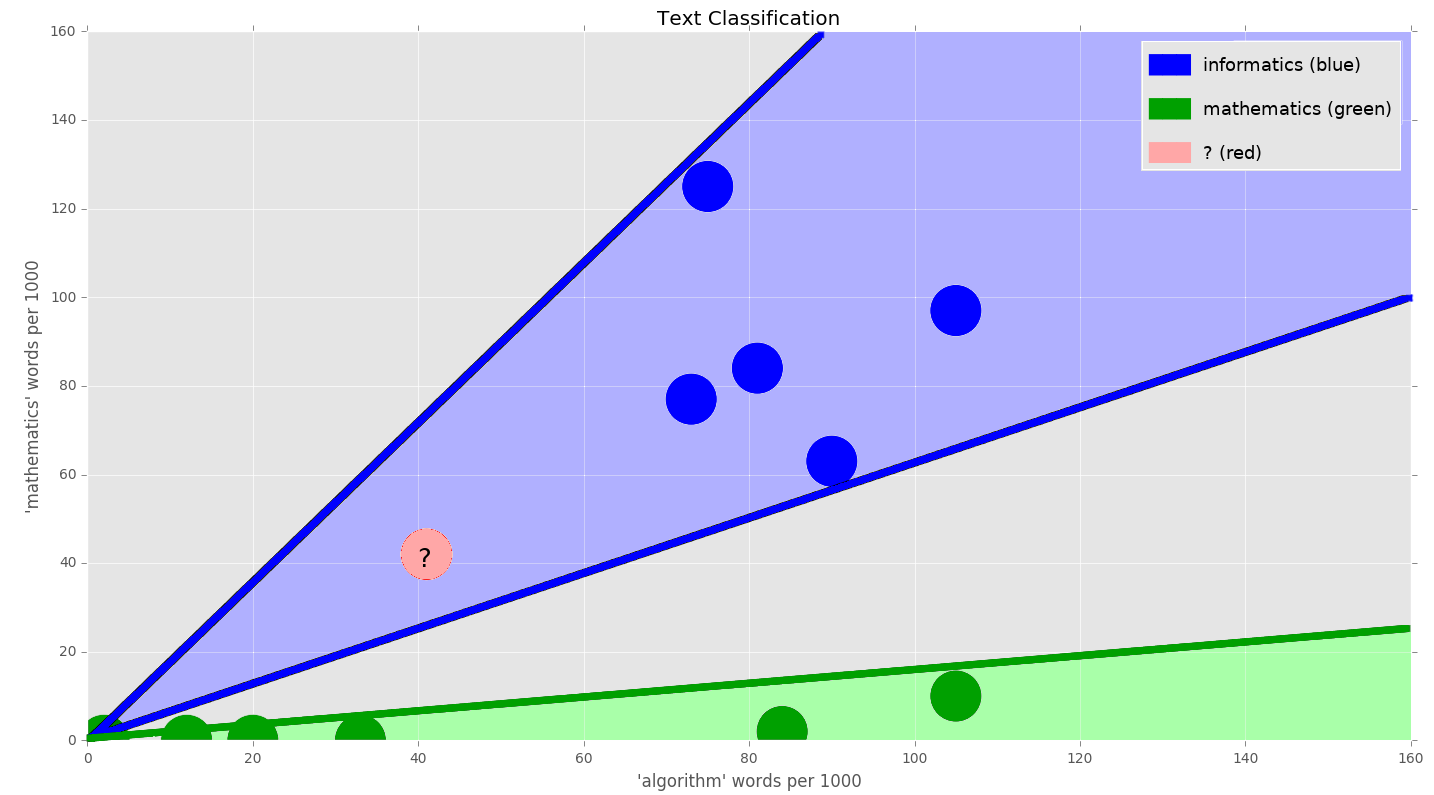
We are given the following word counts relating to the keywords algorithm and computer, for documents of the classes, in the informatics and mathematics subject classifications:
Algorithm words per 1,000 | Computer words per 1,000 | Subject classification |
153 | 150 | Informatics |
105 | 97 | Informatics |
75 | 125 | Informatics |
81 | 84 | Informatics |
73 | 77 | Informatics |
90 | 63 | Informatics |
20 | 0 | Mathematics |
33 | 0 | Mathematics |
105 | 10 | Mathematics |
2 | 0 | Mathematics |
84 | 2 | Mathematics |
12 | 0 | Mathematics |
41 | 42 | ? |
Those documents having a high incidence of the words algorithm and computer are in the informatics class. The mathematicsclass happens to contain documents with a high incidence of the word algorithm in some cases, for example, a document concerned with the Euclidean algorithm from the field of number theory. But, since the mathematics class tends to be applied less than informatics in the area of algorithms, the word computer comes up less frequently in the documents.
We would like to classify a document that has 41 instances of the word algorithm per 1,000 words, and 42 instances of the word computer per 1,000 words:
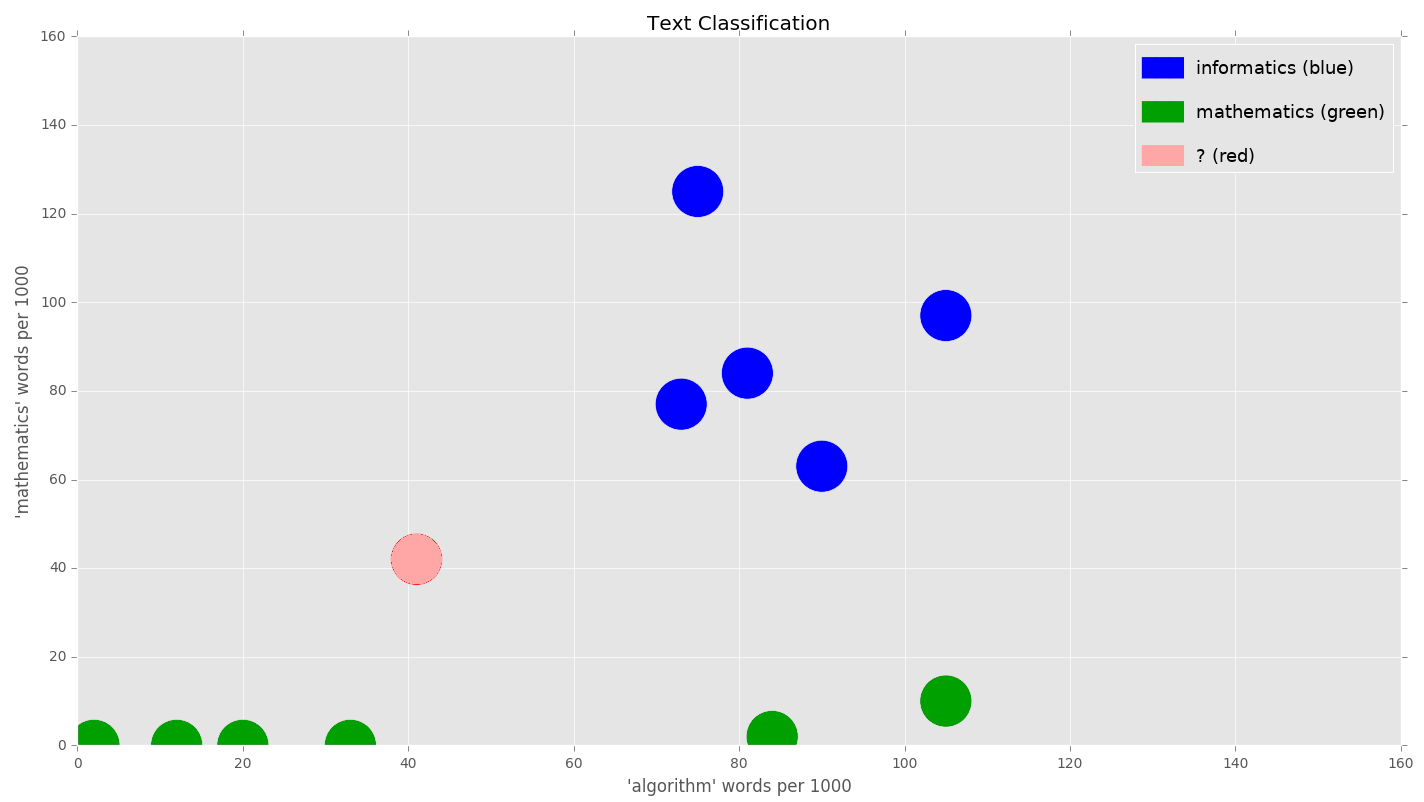
Using, for example, the 1-NN algorithm and the Manhattan or Euclidean distance would result in the document in question being assigned to the mathematicsclass. However, intuitively, we should instead use a different metric to measure the distance, as the document in question has a much higher incidence of the word computer than other known documents in the class of mathematics.
Another candidate metric for this problem is a metric that would measure the proportion of the for the words or the angle between the instances in documents. Instead of the angle, you could take the cosine of the angle, cos(θ), and then use the well-known dot product formula to calculate cos(θ).
Let's use a=(ax,ay), b=(bx,by). Use the following formula:
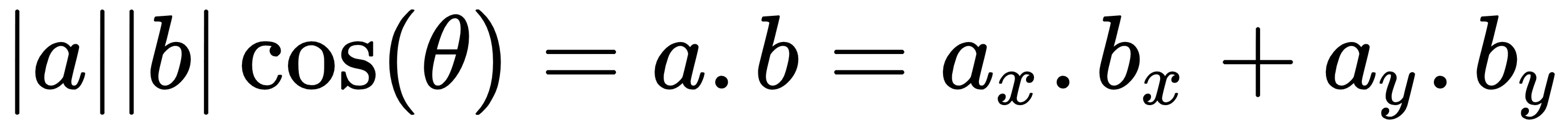
This will derive the following:
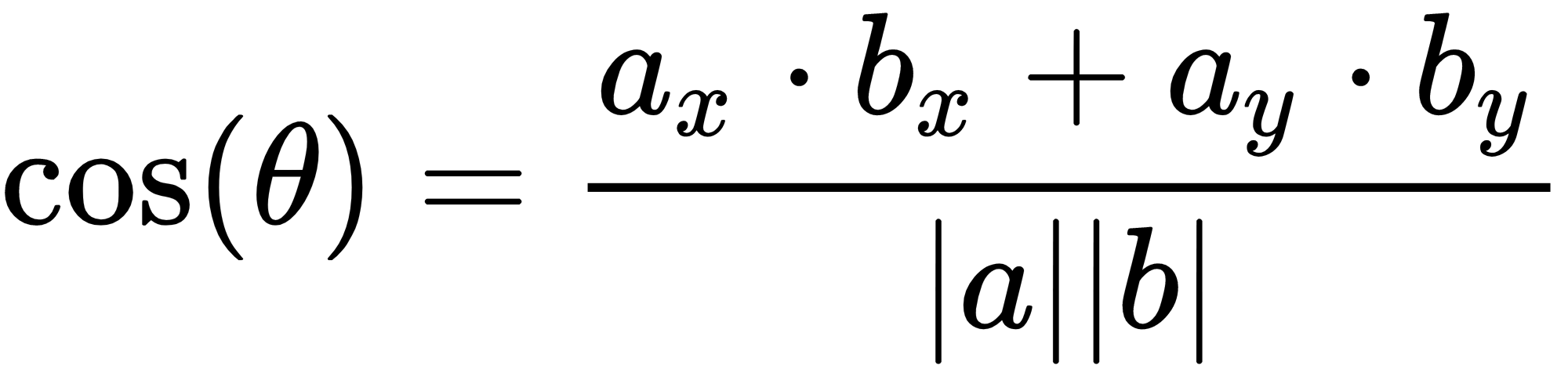
Using the cosine distance metric, you could classify the document in question to the informatics class: