

All DataFrames can add new columns to themselves. However, as usual, whenever a DataFrame is adding a new column from another DataFrame or Series, the indexes align first before the new column is created.
This recipe uses the employee dataset to append a new column containing the maximum salary of that employee's department.
- Import the
employeedata and select theDEPARTMENTandBASE_SALARYcolumns in a new DataFrame:
>>> employee = pd.read_csv('data/employee.csv')
>>> dept_sal = employee[['DEPARTMENT', 'BASE_SALARY']]- Sort this smaller DataFrame by salary within each department:
>>> dept_sal = dept_sal.sort_values(['DEPARTMENT', 'BASE_SALARY'],
ascending=[True, False])- Use the
drop_duplicatesmethod to keep the first row of eachDEPARTMENT:
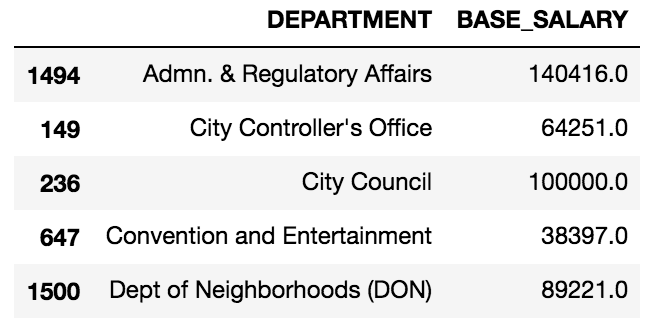
>>> max_dept_sal = dept_sal.drop_duplicates(subset='DEPARTMENT') >>> max_dept_sal.head()
- Put the
DEPARTMENT...