

In the preceding chapter on forms, we logged in to the example website using a manually created account and skipped automating the account creation part, because the registration form requires passing a CAPTCHA. This is how the registration page at http://example.webscraping.com/user/register looks:
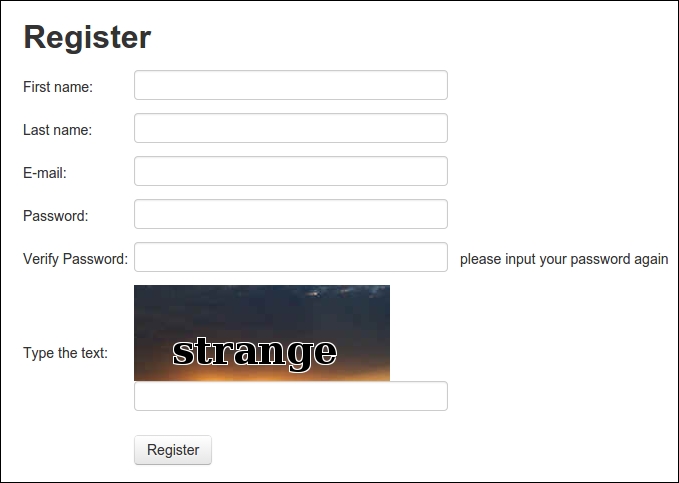
Note that each time this form is loaded, a different CAPTCHA image will be shown. To understand what the form requires, we can reuse the parse_form() function developed in the preceding chapter.
>>> import cookielib, urllib2, pprint
>>> REGISTER_URL = 'http://example.webscraping.com/user/register'
>>> cj = cookielib.CookieJar()
>>> opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(cj))
>>> html = opener.open(REGISTER_URL).read()
>>> form = parse_form(html)
>>> pprint.pprint(form)
{'_formkey': '1ed4e4c4-fbc6-4d82-a0d3-771d289f8661',
'_formname': 'register',
'_next': '/',
'email': '',
'first_name': ...