

One of the important aspects of enterprise data that we learned in the earlier section is the data consolidation and sharing that requires unconstrained collection and access to more data. Every time change is encountered in business, it is captured and recorded as data. This data is usually in a raw form and unless processed cannot be of any value to the business. Innovative analysis tools and software are now available that helps convert this data into valuable information. Many cheap storage options are now available and enterprises are encouraged to store more data and for a long time.
In this section, we will define the core aspects of Big Data, the paradigm shift and attempt to define Big Data.
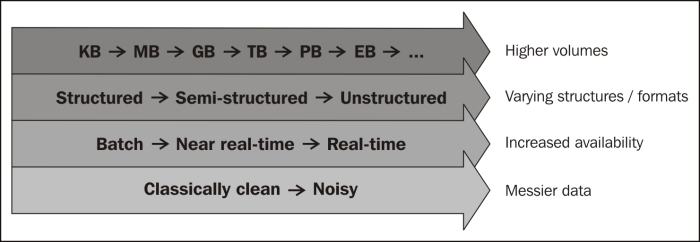
A scale of terabytes, petabytes, exabytes, and higher is what the market refers to in terms of volumes. Traditional database engines cannot scale to handle these volumes. The following figure lists the orders of magnitude that represents data volumes:

Data formats generated and consumed may not be structured (for example, relational data that can be normalized). This data is generated by large/small scientific instruments, social networking sites, and so on. This can be streaming data that is heterogeneous in nature and can be noisy (for example, videos, mails, tweets, and so on). These formats are not supported by any of the traditional datamarts, data store/data mining applications today.
Traditionally, business/enterprise data used to be consumed in batches, in specific windows and subject to processing. With the recent innovation in advanced devices and the invasion of interconnect, data is now available in real time and the need for processing insights in real time has become a prime expectation.
With all the above comes a need for processing efficiency. The processing windows are getting shorter than ever. A simple parallel processing framework like MapReduce has attempted to address this need.
With all that we tried understanding previously; let's now define Big Data.
Big Data can be defined as an environment comprising of tools, processes, and procedures that fosters discovery with data at its center. This discovery process refers to our ability to derive business value from data and includes collecting, manipulating, analyzing, and managing data.
We are talking about four discrete properties of data that require special tools, processes, and procedures to handle:
Increased volumes (to the degree of petabytes, and so on)
Increased availability/accessibility of data (more real time)
Increased formats (different types of data)
Increased messiness (noisy)
There is a paradigm shift seen as we now have technology to bring this all together and analyze it.
In this section, we will discuss various data formats in the context of Big Data. Data is categorized into three main data formats/types:
Structured: Typically, data stored in a relational database can be categorized as structured data. Data that is represented in a strict format is called structured data. Structured data is organized in semantic chunks called entities. These entities are grouped and relations can be defined. Each entity has fixed features called attributes. These attributes have a fixed data type, pre-defined length, constraints, default value definitions, and so on. One important characteristic of structured data is that all entities of the same group have the same attributes, format, length, and follow the same order. Relational database management systems can hold this kind of data.
Semi-structured: For some applications, data is collected in an ad-hoc manner and how this data would be stored or processed is unknown at that stage. Though the data has a structure, it sometimes doesn't comply with a structure that the application is expecting it to be in. Here, different entities can have different structures with no pre-defined structure. This kind of data is defined to be semi-structured. For example, scientific data, bibliographic data, and so on. Graph data structures can hold this kind of data. Some characteristics of semi-structured data are listed as follows:
Organized in semantic entities
Similar entities are grouped together
Entities in the same group may not have the same attributes
Order of attributes isn't important
There might be optional attributes
Same attributes might have varying sizes
Same attributes might be of varying type
Unstructured: Unstructured data refers to the data that has no standard structure and it could mean structure in its isolation. For example, videos, images, documents emails, and so on. File-based storage systems support storing this kind of data. Some key characteristics of unstructured data is listed as follows:
Data can be of any type
Does not have any constraints or follow any rules
It is very unpredictable
Has no specific format or sequence
Data is often a mix of structured, semi-structured, and unstructured data. Unstructured data usually works behind the scenes and eventually converts to structured data.
Here are a few points for us to ponder:
Data can be manifested in a structured way (for example, storing in a relational format would mean structure), and there are structured ways of expressing unstructured data, for example, text.
Applications that process data need to understand the structure of data.
The data that an application produces is usually in a structure that it alone can most efficiently use, and here comes a need for transformation. These transformations are usually complex and the risk of losing data as a part of this process is high.
In the next section that introduces data analytics, we will apply the multi-structured data requirements and take a deep dive on how data of various formats can be processed.
What does it need for a platform to support multi-structured data in a unified way? How native support for each varying structures can be provided, again in a unified way, abstracting end user from the complexity while running analytical processing over the data? The chapters that follow explain how Greenplum UAP can be used to integrate and process data.