

Now that you are fully armed with the basic understanding of physical and theoretical limitations, it is time to learn about different types of replication. It is important to have a clear image of these types to make sure that the right choice can be made and the right tool can be chosen. In this section, synchronous as well as asynchronous replication will be covered.
Let's dig into some important concepts now. The first distinction we can make is whether to replicate synchronously or asynchronously.
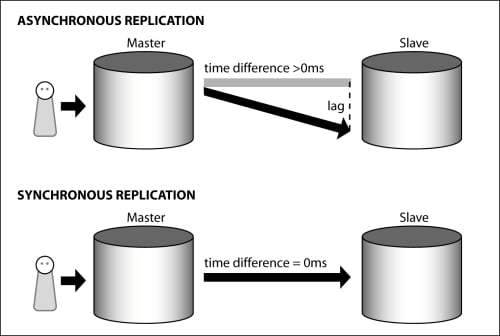
What does this mean? Let's assume we have two servers and we want to replicate data from one server (the master) to the second server (the slave). The following diagram illustrates the concept of synchronous and asynchronous replication:
We can use a simple transaction like the one shown in the following:
BEGIN;
INSERT INTO foo VALUES ('bar');
COMMIT;In the case of asynchronous replication, the data can be replicated after the transaction has been committed on the master. In other words, the slave is never ahead of the master; and in the case of writing, it is usually a little behind the master. This delay is called lag.
Synchronous replication enforces higher rules of consistency. If you decide to replicate synchronously (how this is done practically will be discussed in Chapter 5, Setting Up Synchronous Replication), the system has to ensure that the data written by the transaction will be at least on two servers at the time the transaction commits. This implies that the slave does not lag behind the master and that the data seen by the end users will be identical on both the servers.
Tip
Some systems will also use a quorum server to decide. So, it is not always about just two or more servers. If a quorum is used, more than half of the servers must agree on an action inside the cluster.
As you have learned earlier in the section about the speed of light and latency, sending unnecessary messages over the network can be expensive and time-consuming. If a transaction is replicated in a synchronous way, PostgreSQL has to make sure that the data reaches the second node, and this will lead to latency issues.
Synchronous replication can be more expensive than asynchronous replication in many ways, and therefore, people should think twice about whether this overhead is really needed and justified. In the case of synchronous replication, confirmations from a remote server are needed. This, of course, causes some additional overhead. A lot has been done in PostgreSQL to reduce this overhead as much as possible. However, it is still there.
When a transaction is replicated from a master to a slave, many things have to be taken into consideration, especially when it comes to things such as data loss.
Let's assume that we are replicating data asynchronously in the following manner:
A transaction is sent to the master.
It commits on the master.
The master dies before the commit is sent to the slave.
The slave will never get this transaction.
In the case of asynchronous replication, there is a window (lag) during which data can essentially be lost. The size of this window might vary, depending on the type of setup. Its size can be very short (maybe as short as a couple of milliseconds) or long (minutes, hours, or days). The important fact is that data can be lost. A small lag will only make data loss less likely, but any lag larger than zero lag is susceptible to data loss. If data can be lost, we are about to sacrifice the consistency part of CAP (if two servers don't have the same data, they are out of sync).
If you want to make sure that data can never be lost, you have to switch to synchronous replication. As you have already seen in this chapter, a synchronous transaction is synchronous because it will be valid only if it commits to at least two servers.
A second way to classify various replication setups is to distinguish between single-master and multi-master replication.
"Single-master" means that writes can go to exactly one server, which distributes the data to the slaves inside the setup. Slaves may receive only reads, and no writes.
In contrast to single-master replication, multi-master replication allows writes to all the servers inside a cluster. The following diagram shows how things work at a conceptual level:

The ability to write to any node inside the cluster sounds like an advantage, but it is not necessarily one. The reason for this is that multimaster replication adds a lot of complexity to the system. In the case of only one master, it is totally clear which data is correct and in which direction data will flow, and there are rarely conflicts during replication. Multimaster replication is quite different, as writes can go to many nodes at the same time, and the cluster has to be perfectly aware of conflicts and handle them gracefully. An alterative would be to use locks to solve the problem, but this approach will also have its own challenges.
One more way of classifying replication is to distinguish between logical and physical replication.
The difference is subtle but highly important:
Physical replication means that the system will move data as is to the remote box. So, if something is inserted, the remote box will get data in binary format, not via SQL.
Logical replication means that a change, which is equivalent to data coming in, is replicated.
Let's look at an example to fully understand the difference:
test=# CREATE TABLE t_test (t date); CREATE TABLE test=# INSERT INTO t_test VALUES (now()) RETURNING *; t ------------ 2013-02-08 (1 row) INSERT 0 1
We see two transactions going on here. The first transaction creates a table. Once this is done, the second transaction adds a simple date to the table and commits.
In the case of logical replication, the change will be sent to some sort of queue in logical form, so the system does not send plain SQL, but maybe something such as this:
test=# INSERT INTO t_test VALUES ('2013-02-08');
INSERT 0 1Note that the function call has been replaced with the real value. It would be a total disaster if the slave were to calculate now() once again, because the date on the remote box might be a totally different one.
Tip
Some systems do use statement-based replication as the core technology. MySQL, for instance, uses a so-called bin-log statement to replicate, which is actually not too binary but more like some form of logical replication. Of course, there are also counterparts in the PostgreSQL world, such as pgpool, Londiste, and Bucardo.
Physical replication will work in a totally different way; instead of sending some SQL (or something else) over, which is logically equivalent to the changes made, the system will send binary changes made by PostgreSQL internally.
Here are some of the binary changes our two transactions might have triggered (but by far, this is not a complete list):
Added an 8 K block to
pg_classand put a new record there (to indicate that the table is present).Added rows to
pg_attributeto store the column names.Performed various changes inside the indexes on those tables.
Recorded the commit status, and so on.
The goal of physical replication is to create a copy of your system that is (largely) identical on the physical level. This means that the same data will be in the same place inside your tables on all boxes. In the case of logical replication, the content should be identical, but it makes no difference whether it is in the same place or not.
Physical replication is very convenient to use and especially easy to set up. It is widely used when the goal is to have identical replicas of your system (to have a backup or to simply scale up).
In many setups, physical replication is the standard method that exposes the end user to the lowest complexity possible. It is ideal for scaling out the data.
Logical replication is usually a little harder to set up, but it offers greater flexibility. It is also especially important when it comes to upgrading an existing database. Physical replication is totally unsuitable for version jumps because you cannot simply rely on the fact that every version of PostgreSQL has the same on-disk layout. The storage format might change over time, and therefore, a binary copy is clearly not feasible for a jump from one version to the next.
Logical replication allows decoupling of the way data is stored from the way it is transported and replicated. Using a neutral protocol, which is not bound to any specific version of PostgreSQL, it is easy to jump from one version to the next.
Since PostgreSQL 9.4, there is something called Logical Decoding. It allows users to extract internal changes sent to the XLOG as SQL again. Logical decoding will be needed for a couple of replication techniques outlined in this book.