

Many metrics can be used to measure whether or not a program is learning to perform its task more effectively. For supervised learning problems, many performance metrics measure the number of prediction errors. There are two fundamental causes of prediction error: a model's bias and its variance. Assume that you have many training sets that are all unique, but equally representative of the population. A model with a high bias will produce similar errors for an input regardless of the training set it was trained with; the model biases its own assumptions about the real relationship over the relationship demonstrated in the training data. A model with high variance, conversely, will produce different errors for an input depending on the training set that it was trained with. A model with high bias is inflexible, but a model with high variance may be so flexible that it models the noise in the training set. That is, a model with high variance over-fits the training data, while a model with high bias under-fits the training data. It can be helpful to visualize bias and variance as darts thrown at a dartboard. Each dart is analogous to a prediction from a different dataset. A model with high bias but low variance will throw darts that are far from the bull's eye, but tightly clustered. A model with high bias and high variance will throw darts all over the board; the darts are far from the bull's eye and each other.
A model with low bias and high variance will throw darts that are closer to the bull's eye, but poorly clustered. Finally, a model with low bias and low variance will throw darts that are tightly clustered around the bull's eye, as shown in the following diagram:
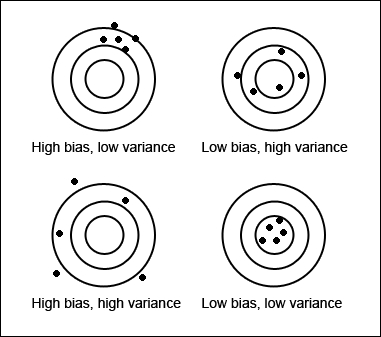
Ideally, a model will have both low bias and variance, but efforts to decrease one will frequently increase the other. This is known as the bias-variance trade-off. We will discuss the biases and variances of many of the models introduced in this book.
Unsupervised learning problems do not have an error signal to measure; instead, performance metrics for unsupervised learning problems measure some attributes of the structure discovered in the data.
Most performance measures can only be calculated for a specific type of task. Machine learning systems should be evaluated using performance measures that represent the costs associated with making errors in the real world. While this may seem obvious, the following example describes the use of a performance measure that is appropriate for the task in general but not for its specific application.
Consider a classification task in which a machine learning system observes tumors and must predict whether these tumors are malignant or benign. Accuracy, or the fraction of instances that were classified correctly, is an intuitive measure of the program's performance. While accuracy does measure the program's performance, it does not differentiate between malignant tumors that were classified as being benign, and benign tumors that were classified as being malignant. In some applications, the costs associated with all types of errors may be the same. In this problem, however, failing to identify malignant tumors is likely to be a more severe error than mistakenly classifying benign tumors as being malignant.
We can measure each of the possible prediction outcomes to create different views of the classifier's performance. When the system correctly classifies a tumor as being malignant, the prediction is called a true positive. When the system incorrectly classifies a benign tumor as being malignant, the prediction is a false positive. Similarly, a false negative is an incorrect prediction that the tumor is benign, and a true negative is a correct prediction that a tumor is benign. These four outcomes can be used to calculate several common measures of classification performance, including accuracy, precision, and recall.
Accuracy is calculated with the following formula, where TP is the number of true positives, TN is the number of true negatives, FP is the number of false positives, and FN is the number of false negatives:
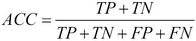
Precision is the fraction of the tumors that were predicted to be malignant that are actually malignant. Precision is calculated with the following formula:
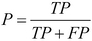
Recall is the fraction of malignant tumors that the system identified. Recall is calculated with the following formula:
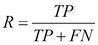
In this example, precision measures the fraction of tumors that were predicted to be malignant that are actually malignant. Recall measures the fraction of truly malignant tumors that were detected.
The precision and recall measures could reveal that a classifier with impressive accuracy actually fails to detect most of the malignant tumors. If most tumors are benign, even a classifier that never predicts malignancy could have high accuracy. A different classifier with lower accuracy and higher recall might be better suited to the task, since it will detect more of the malignant tumors.
Many other performance measures for classification can be used; we will discuss some, including metrics for multilabel classification problems, in later chapters. In the next chapter, we will discuss some common performance measures for regression tasks.