

Storm is a distributed, fault-tolerant, and highly scalable platform for processing streaming data in a real-time manner. It became an Apache top-level project in September 2014, and was previously an Apache Incubator project since September 2013.
Real-time processing on a massive scale has become a requirement of businesses. Apache Storm provides the capability to process data (a.k.a tuples or stream) as and when it arrives in a real-time manner with distributed computing options. The ability to add more machines to the Storm cluster makes Storm scalable. Then, the third most important thing that comes with storm is fault tolerance. If the storm program (also known as topology) is equipped with reliable spout, it can reprocess the failed tuples lost due to machine failure and also give fault tolerance. It is based on XOR magic, which will be explained in Chapter 2, The Storm Anatomy.
Storm was originally created by Nathan Marz and his team at BackType. The project was made open source after it was acquired by Twitter. Interestingly, Storm received a tag as Real Time Hadoop.
Storm is best suited for many real-time use cases. A few of its interesting use cases are explained here:
ETL pipeline: ETL stands for Extraction, Transformation, and Load. It is a very common use case of Storm. Data can be extracted or read from any source. Here, the data can be complex XML, a JDBC result set row, or simply a few key-value records. Data (also known as tuples in Storm) can be enriched on the fly with more information, transformed into the required storage format, and stored in a NoSQL/RDBMS data store. All of these things can be achieved at a very high throughput in a real-time manner with simple storm programs. Using the Storm ETL pipeline, you can ingest into a big data warehouse at high speed.
Trending topic analysis: Twitter uses such use cases to know the trending topics within a given time frame or at present. There are numerous use cases, and finding the top trends in a real-time manner is required. Storm can fit well in such use cases. You can also perform running aggregation of values with the help of any database.
Regulatory check engine: Real-time event data can pass through a business-specific regulatory algorithm, which can perform a compliance check in a real-time manner. Banks use these for trade data checks in real time.
Storm can ideally fit into any use case where there is a need to process data in a fast and reliable manner, at a rate of more than 10,000 messages processing per second, as soon as data arrives. Actually, 10,000+ is a small number. Twitter is able to process millions of tweets per second on a large cluster. It depends on how well the Storm topology is written, how well it is tuned, and the cluster size.
Storm program (a.k.a topologies) are designed to run 24x7 and will not stop until someone stops them explicitly.
Storm is written using both Clojure as well as Java. Clojure is a Lisp, functional programming language that runs on JVM and is best for concurrency and parallel programming. Storm leverages the mature Java library, which was built over the last 10 years. All of these can be found inside the storm/lib folder.
Before Storm became popular, real-time or near-real-time processing problems were solved using intermediate brokers and with the help of message queues. Listener or worker processes run using the Python or Java languages. For parallel processing, code was dependent on the threading model supplied using the programming language itself. Many times, the old style of working did not utilize CPU and memory very well. In some cases, mainframes were used as well, but they also became outdated over time. Distributed computing was not so easy. There were either many intermediate outputs or hops in this old style of working. There was no way to perform a fail replay automatically. Storm addressed all of these pain areas very well. It is one of the best real-time computation frameworks available for use.
Here are Storm's key features; they address the aforementioned problems:
Simple to program: It's easy to learn the Storm framework. You can write code in the programming language of your choice and can also use the existing libraries of that programming language. There is no compromise.
Storm already supports most programming languages: However, even if something is not supported, it can be done by supplying code and configuration using the JSON protocol defined in the Storm Data Specification Language (DSL).
Horizontal scalability or distributed computing is possible: Computation can be multiplied by adding more machines to the Storm cluster without stopping running programs, also known as topologies.
Fault tolerant: Storm manages worker and machine-level failure. Heartbeats of each process are tracked to manage different types of failure, such as task failure on one machine or an entire machine's failure.
Guaranteed message processing: There is a provision of performing auto and explicit ACK within storm processes on messages (tuples). If ACK is not received, storm can do a reply of a message.
Free, open source, and lots of open source community support: Being an Apache project, Storm has free distribution and modifying rights without any worry about the legal aspect. Storm gets a lot of attention from the open source community and is attracting a large number of good developers to contribute to the code.
The Storm cluster can be set up in four flavors based on the requirement. If you want to set up a large cluster, go for distributed installation. If you want to learn Storm, then go for a single machine installation. If you want to connect to an existing Storm cluster, use client mode. Finally, if you want to perform development on an IDE, simply unzip the storm TAR and point to all dependencies of the storm library. At the initial learning phase, a single-machine storm installation is actually what you need.
A developer can download storm from the distribution site, unzip it somewhere in $HOME, and simply submit the Storm topology as local mode. Once the topology is successfully tested locally, it can be submitted to run over the cluster.
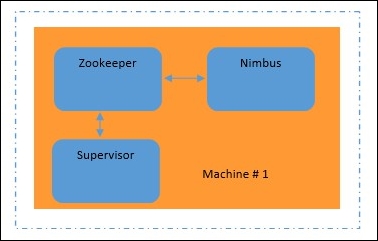
This flavor is best for students and medium-scale computation. Here, everything runs on a single machine, including Zookeeper, Nimbus, and Supervisor. Storm/bin is used to run all commands. Also, no extra Storm client is required. You can do everything from the same machine. This case is well demonstrated in the following figure:
This option is required when you have a large-scale computation requirement. It is a horizontal scaling option. The following figure explains this case in detail. In this figure, we have five physical machines, and to increase fault tolerance in the systems, we are running Zookeeper on two machines. As shown in the diagram, Machine 1 and Machine 2 are a group of Zookeeper machines; one of them is the leader at any point of time, and when it dies, the other becomes the leader. Nimbus is a lightweight process, so it can run on either machine, 1 or 2. We also have Machine 3, Machine 4, and Machine 5 dedicated for performing actual processing. Each one of these machines (3, 4, and 5) requires a supervisor daemon to run over there. Machines 3, 4, and 5 should know where the Nimbus/Zookeeper daemon is running and that entry should be present in their storm.yaml.

So, each physical machine (3, 4, and 5) runs one supervisor daemon, and each machine's storm.yaml points to the IP address of the machine where Nimbus is running (this can be 1 or 2). All Supervisor machines must add the Zookeeper IP addresses (1 and 2) to storm.yaml. The Storm UI daemon should run on the Nimbus machine (this can be 1 or 2).
The Storm client is required only when you have a Storm cluster of multiple machines. To start the client, unzip the Storm distribution and add the Nimbus IP address to the storm.yaml file. The Storm client can be used to submit Storm topologies and check the status of running topologies from command-line options. Storm versions older than 0.9 should put the yaml file inside $STORM_HOME/.storm/storm.yaml (not required for newer versions).
Installing Java and Python is easy. Let's assume our Linux machine is ready with Java and Python:
A Linux machine (Storm version 0.9 and later can also run on Windows machines)
Java 6 (
set export PATH=$PATH:$JAVA_HOME/bin)Python 2.6 (required to run Storm daemons and management commands)
We will be making lots of changes in the storm configuration file (that is, storm.yaml), which is actually present under $STORM_HOME/config. First, we start the Zookeeper process, which carries out coordination between Nimbus and the Supervisors. Then, we start the Nimbus master daemon, which distributes code in the Storm cluster. Next, the Supervisor daemon listens for work assigned (by Nimbus) to the node it runs on and starts and stops the worker processes as necessary.
ZeroMQ/JZMQ and Netty are inter-JVM communication libraries that permit two machines or two JVMs to send and receive process data (tuples) between each other. JZMQ is a Java binding of ZeroMQ. The latest versions of Storm (0.9+) have now been moved to Netty. If you download an old version of Storm, installing ZeroMQ and JZMQ is required. In this book, we will be considering only the latest versions of Storm, so you don't really require ZeroMQ/JZMQ.
Zookeeper is a coordinator for the Storm cluster. The interaction between Nimbus and worker nodes is done through Zookeeper. The installation of Zookeeper is well explained on the official website at http://zookeeper.apache.org/doc/trunk/zookeeperStarted.html#sc_InstallingSingleMode.
The setup can be downloaded from:
https://archive.apache.org/dist/zookeeper/zookeeper-3.3.5/zookeeper-3.3.5.tar.gz. After downloading, edit the zoo.cfg file.
The following are the Zookeeper commands that are used:
Alternatively, use jps to find <pid> and then use kill -9 <pid> to kill the processes.