

Sometimes, it may happen that an existing Hadoop cluster's capacity is not adequate enough to handle all the data you may want to process. In this case, you can add new nodes to the existing Hadoop cluster without any downtime for the existing cluster. Hadoop supports horizontal scalability.
To perform this recipe, you should have a Hadoop cluster running. Also, you will need one more machine. If you are using AWS EC2, then you can launch an EC2 instance that's similar to what we did in the previous recipes. You will also need the same security group configurations in order to make the installation process smooth.
To add a new instance to an existing cluster, simply install and configure Hadoop the way we did for the previous recipe. Make sure that you put the same configurations in core-site.xml and yarn-site.xml, which will point to the correct master node.
Once all the configurations are done, simply execute commands to start the newly added datanode and nodemanager:
/usr/local/hadoop/sbin/hadoop-daemon.sh start datanode /usr/local/hadoop/sbin/yarn-daemon.sh start nodemanager
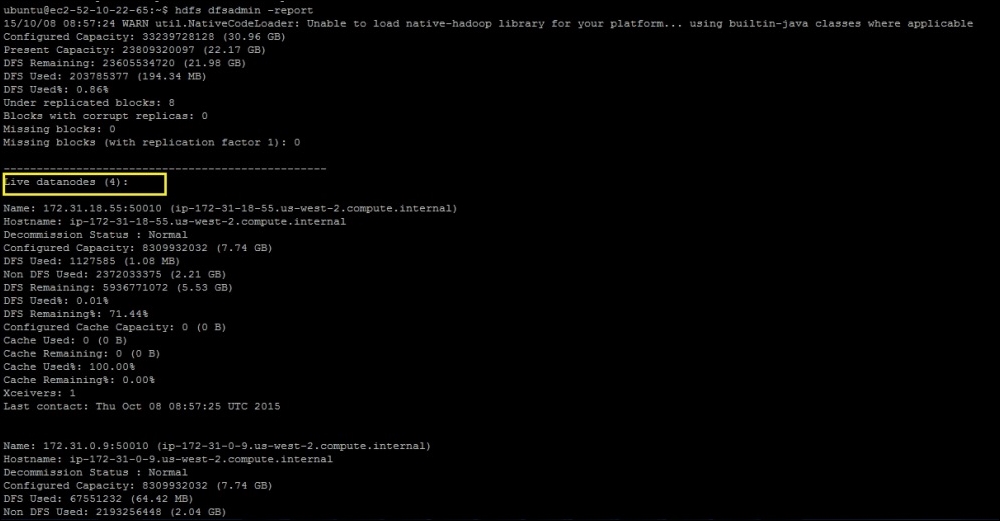
If you take a look at the cluster again, you will find that the new node is registered. You can use the dfsadmin command to take a look at the number of nodes and amount of capacity that's been used:
hdfs dfsadmin -report
Here is a sample output for the preceding command:
Hadoop supports horizontal scalability. If the resources that are being used are not enough, we can always go ahead and add new nodes to the existing cluster without hiccups. In Hadoop, it's always the slave that reports to the master. So, while making configurations, we always configure the details of the master and do nothing about the slaves. This architecture helps achieve horizontal scalability as at any point of time, we can add new nodes by only providing the configurations of the master, and everything else is taken care of by the Hadoop cluster. As soon as the daemons start, the master node realizes that a new node has been added and it becomes part of the cluster.