

Now, let's look at the important machine learning algorithms and some brief details about each of them. In-depth implementation aspects for each of the algorithms will be covered in later chapters. These algorithms are either classified under the problem type or the learning type. There is a simple classification of the algorithms given but it is intuitive and not necessarily exhaustive.
There are many ways of classifying or grouping machine learning algorithms, and in this book we will use the learning model based grouping. In each chapter, starting from Chapter 5, Decision Tree based learning, we will cover one or more learning models and associated algorithms. The following concept model depicts a listing of learning models:
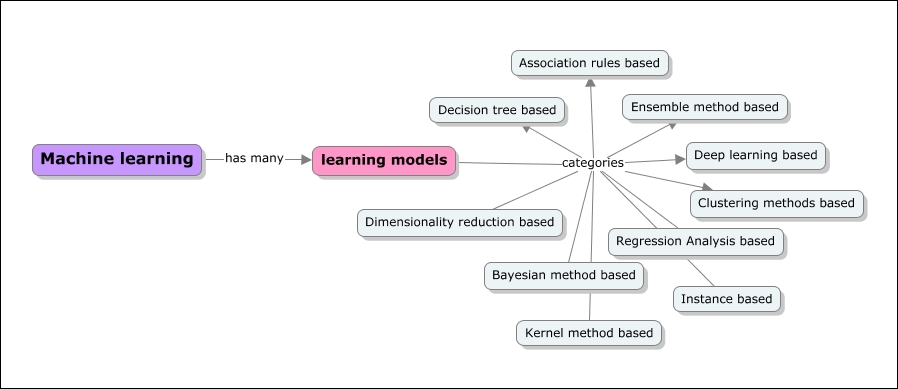
Decision tree based algorithms define models that are iteratively or recursively constructed based on the data provided. The goal of Decision tree based algorithms is to predict the value of a target variable given a set of input variables. Decision trees help solve classification and regression problems using tree based methods. Decisions fork in tree structures until a prediction decision is made for a given record. Some of the algorithms are as follows:
Bayesian methods are those that explicitly apply the Bayesian inference theorem and again solve classification and regression problems. Bayesian methods facilitate subjective probability in modeling. The following are some of the Bayesian based algorithms:
When we hear about kernel methods, the first thing that comes to mind is Support Vector Machines (SVM). These methods are usually a group of methods in themselves. kernel methods are concerned with pattern analysis and as explained in the preceding sections, that crux of pattern analysis includes various mapping techniques. Here, the mapping datasets include vector spaces. Some examples of kernel method based learning algorithms are listed as follows:
SVM
Linear discriminant analysis (LDA)
Clustering, like regression, describes a class of problems and a class of methods. Clustering methods are typically organized by the modeling approaches such as centroid-based and hierarchical. These methods organize data into groups by assessing the similarity in the structure of input data:
Similar to kernel methods, artificial neural networks are again a class of pattern matching techniques, but these models are inspired by the structure of biological neural networks. These methods are again used to solve classifications and regression problems. They relate to Deep learning modeling and have many subfields of algorithms that help solve specific problems in context.
Like clustering methods, dimensionality reduction methods work iteratively and on the data structure in an unsupervised manner. Given the dataset and the dimensions, more dimensions would mean more work in the Machine learning implementation. The idea is to iteratively reduce the dimensions and bring more relevant dimensions forward. This technique is usually used to simplify high-dimensional data and then apply a supervised learning technique. Some example dimensionality reduction methods are listed as follows:
As the name suggests, ensemble methods encompass multiple models that are built independently and the results of these models are combined and responsible for overall predictions. It is critical to identify what independent models are to be combined or included, how the results need to be combined, and in what way to achieve the required result. The subset of models that are combined is sometimes referred to as weaker models as the results of these models need not completely fulfill the expected outcome in isolation. This is a very powerful and widely adopted class of techniques. The following are some of the Ensemble method algorithms:
Instances are nothing but subsets of datasets, and instance based learning models work on an identified instance or groups of instances that are critical to the problem. The results across instances are compared, which can include an instance of new data as well. This comparison uses a particular similarity measure to find the best match and predict. Instance based methods are also called case-based or memory-based learning. Here the focus is on the representation of the instances and similarity measures for comparison between instances. Some of the instance based learning algorithms are listed as follows:
Regression is a process of refining the model iteratively based on the error generated by the model. Regression also is used to define a machine learning problem type. Some example algorithms in regression are:
Given the variables, association rule based learning algorithms extract and define rules that can be applied on a dataset and demonstrate experienced-based learning, and thus prediction. These rules when associated in a multi-dimensional data context can be useful in a commercial context as well. Some of the examples of Association rule based algorithms are given as follows: