

Machine learning has become increasingly important for data science analysis as it has been for a multitude of other fields. A defining characteristic of machine learning is the ability of a model to be trained on a set of representative data and then later used to solve similar problems. There is no need to explicitly program an application to solve the problem. A model is a representation of the real-world object.
For example, customer purchases can be used to train a model. Subsequently, predictions can be made about the types of purchases a customer might subsequently make. This allows an organization to tailor ads and coupons for a customer and potentially providing a better customer experience.
Training can be performed in one of several different approaches:
Supervised learning: The model is trained with annotated, labeled, data showing corresponding correct results
Unsupervised learning: The data does not contain results, but the model is expected to find relationships on its own
Semi-supervised: A small amount of labeled data is combined with a larger amount of unlabeled data
Reinforcement learning: This is similar to supervised learning, but a reward is provided for good results
There are several approaches that support machine learning. In Chapter 6, Machine Learning, we will illustrate three techniques:
Decision trees: A tree is constructed using features of the problem as internal nodes and the results as leaves
Support vector machines: This is used for classification by creating a hyperplane that partitions the dataset and then makes predictions
Bayesian networks: This is used to depict probabilistic relationships between events
A Support Vector Machine (SVM) is used primarily for classification type problems. The approach creates a hyperplane to categorize data, which can be envisioned as a geometric plane that separates two regions. In a two-dimensional space, it will be a line. In a three-dimensional space, it will be a two-dimensional plane. In Chapter 6, Machine Learning, we will demonstrate how to use the approach using a set of data relating to the propensity of individuals to camp. We will use the Weka class, SMO, to demonstrate this type of analysis.
The following figure depicts a hyperplane using a distribution of two types of data points. The lines represent possible hyperplanes that separate these points. The lines clearly separate the data points except for one outlier.
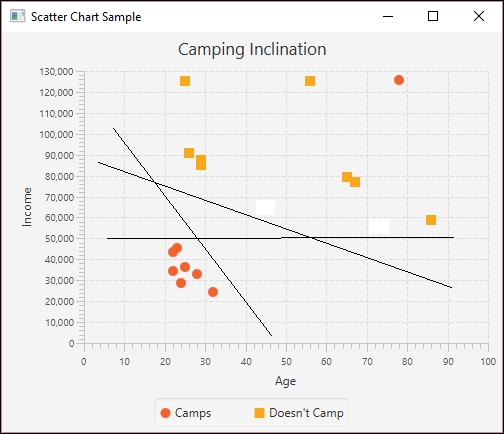
Once the model has been trained, the possible hyperplanes are considered and predictions can then be made using similar data.