

The Spark action has been recently added in Oozie and the general XSD is shown in the following figure:
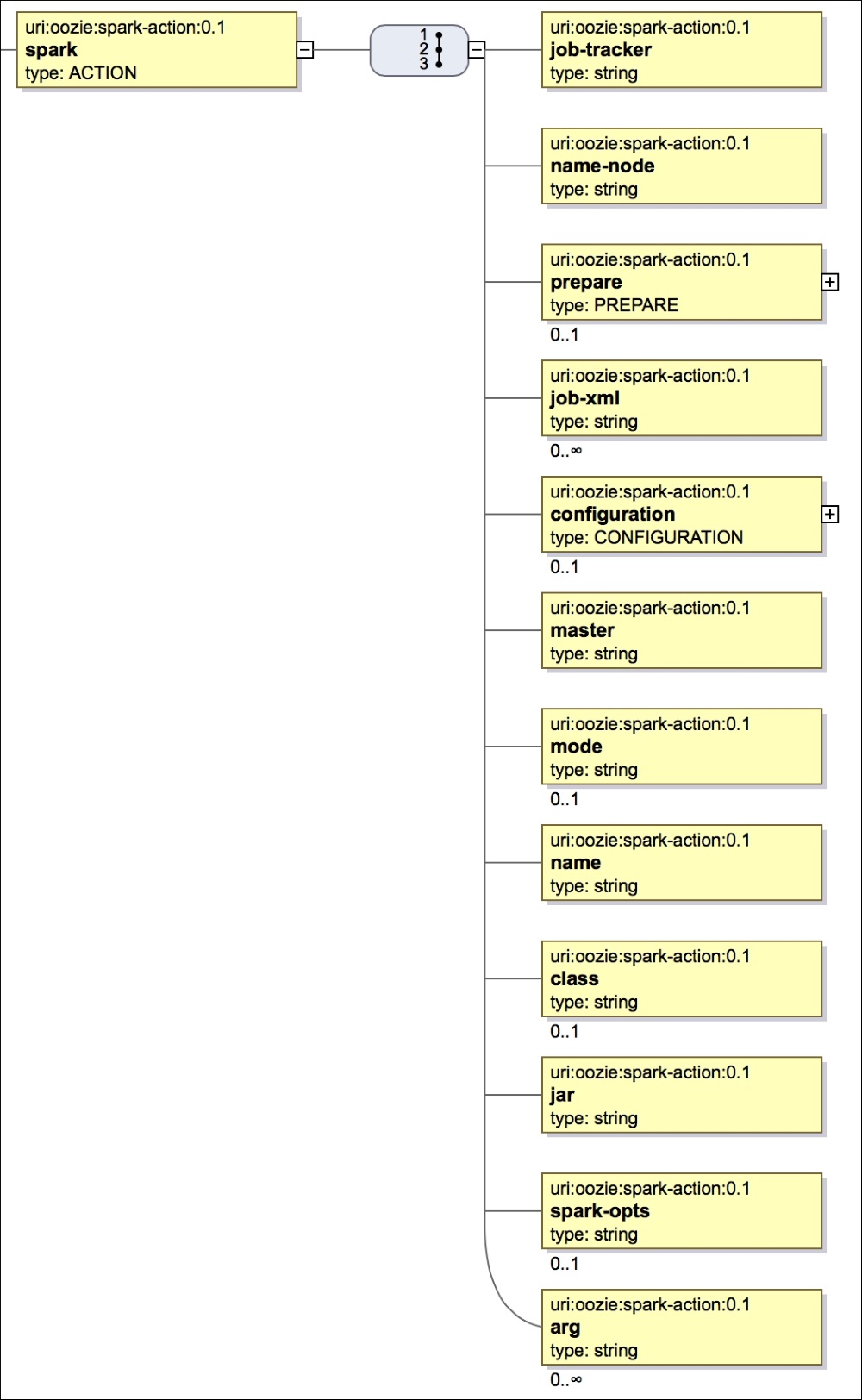
Spark SVG action
The general schema is as follows:
<action> <job-tracker> // Job tracker details <name-node> // Name node details <prepare> // Create or Delete directory <job-xml> // Any job xml properties <configuration> // Hadoop job configuration <master> // Spark master details <mode> // Spark driver mode <name> // Spark Job name <class> // Spark main class <spark-opts> // Spark Job options <arg> // Arguments for the job </action>
The <master> element tells about the URL of Spark master. Spark can run in different cluster configurations, namely Spark standalone, Mesos, and Yarn. Depending on which cluster manager you are using, the master URL will change...