

It is necessary to appreciate the nature of the constraints and potentially sub-optimal conditions one may face when dealing with problems requiring machine learning. An understanding of the nature of these issues, the impact of their presence, and the methods to deal with them will be addressed throughout the discussions in the coming chapters. Here, we present a brief introduction to the practical issues that confront us:
Data quality and noise: Missing values, duplicate values, incorrect values due to human or instrument recording error, and incorrect formatting are some of the important issues to be considered while building machine learning models. Not addressing data quality can result in incorrect or incomplete models. In the next chapter, we will highlight some of these issues and some strategies to overcome them through data cleansing.
Imbalanced datasets: In many real-world datasets, there is an imbalance among labels in the training data. This imbalance in a dataset affects the choice of learning, the process of selecting algorithms, model evaluation and verification. If the right techniques are not employed, the models can suffer large biases, and the learning is not effective. Detailed in the next few chapters are various techniques that use meta-learning processes, such as cost-sensitive learning, ensemble learning, outlier detection, and so on, which can be employed in these situations.
Data volume, velocity, and scalability: Often, a large volume of data exists in raw form or as real-time streaming data at high speed. Learning from the entire data becomes infeasible either due to constraints inherent to the algorithms or hardware limitations, or combinations thereof. In order to reduce the size of the dataset to fit the resources available, data sampling must be done. Sampling can be done in many ways, and each form of sampling introduces a bias. Validating the models against sample bias must be performed by employing various techniques, such as stratified sampling, varying sample sizes, and increasing the size of experiments on different sets. Using big data machine learning can also overcome the volume and sampling biases.
Overfitting: One of the core problems in predictive models is that the model is not generalized enough and is made to fit the given training data too well. This results in poor performance of the model when applied to unseen data. There are various techniques described in later chapters to overcome these issues.
Curse of dimensionality: When dealing with high-dimensional data, that is, datasets with a large number of features, scalability of machine learning algorithms becomes a serious concern. One of the issues with adding more features to the data is that it introduces sparsity, that is, there are now fewer data points on average per unit volume of feature space unless an increase in the number of features is accompanied by an exponential increase in the number of training examples. This can hamper performance in many methods, such as distance-based algorithms. Adding more features can also deteriorate the predictive power of learners, as illustrated in the following figure. In such cases, a more suitable algorithm is needed, or the dimensionality of the data must be reduced.
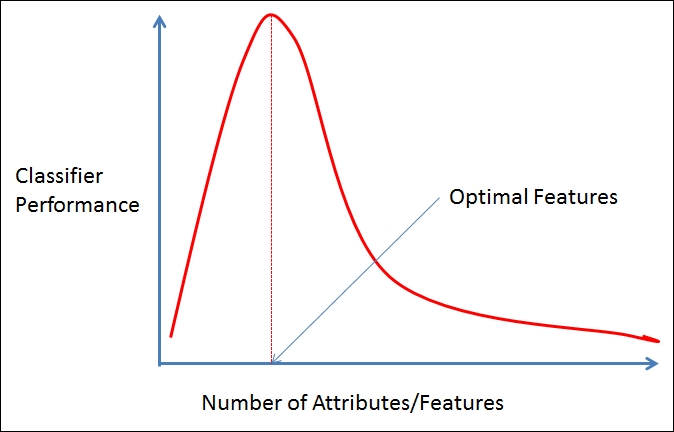
Curse of dimensionality illustrated in classification learning, where adding more features deteriorates classifier performance.