

Data Integration involves a number of sub processes that range from acquiring raw data to enriching the data before the data is used for consumption. There are many tools and technologies available that can sometimes be used independently or together to suit the specific business needs. These range from the packaged tools that natively operate on Big Data, to enabled technologies that let us develop tools that can work on our specific use case.
The following figure depicts the key aspects that are to be considered while choosing the right tools and technologies for Data Integration of structured data and unstructured data:
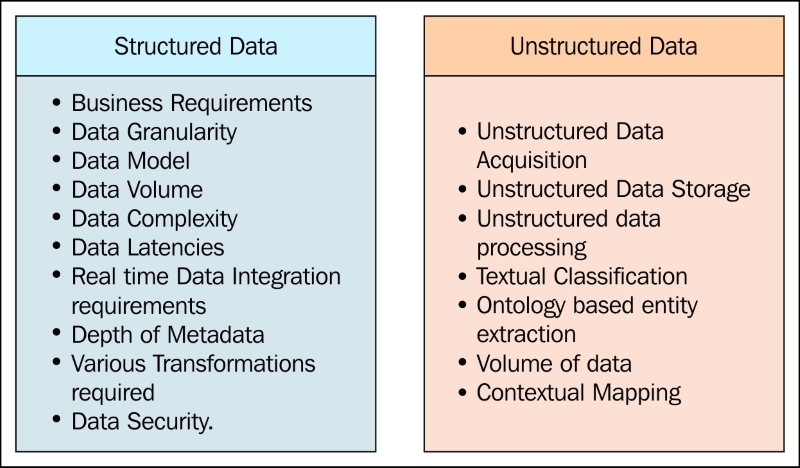
The key considerations for choosing an Integration tool
Based on the preceding considerations and the associated trade-offs, you can choose a cloud-based Data Integration tool or an on-premise data Integration tool. The primary driver for making this choice is the cost associated for in-house deployment vs. pay-as-you-go benefits of SaaS models...