

To demonstrate using a browser and API, we will investigate Facebook's site. Currently, Facebook is the world's largest social network in terms of monthly active users, and therefore, its user data is extremely valuable.
The website
Here is an example Facebook page for Packt Publishing athttps://www.facebook.com/PacktPub:
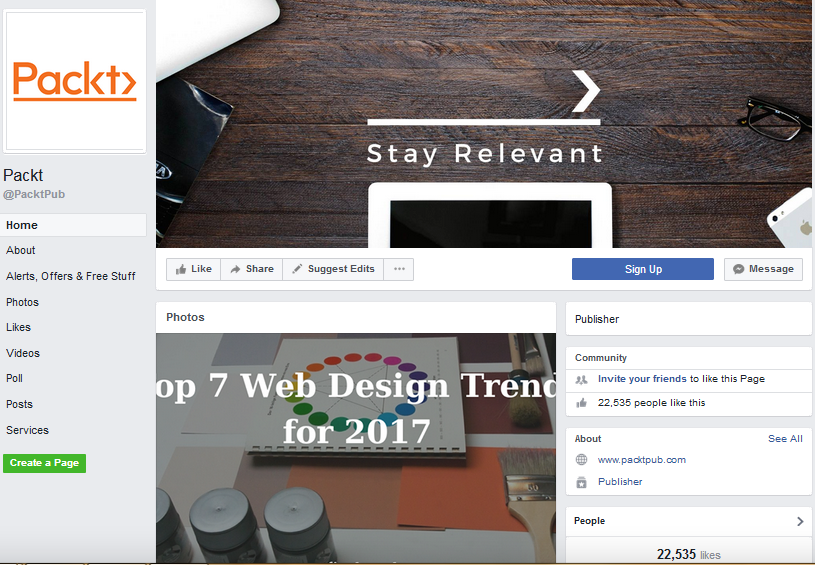
Viewing the source of this page, you would find that the first few posts are available, and that later posts are loaded with AJAX when the browser scrolls. Facebook also has a mobile interface, which, as mentioned in Chapter 1, Introduction to Web Scraping, is often easier to scrape. The same page using the mobile interface is available at https://m.facebook.com/PacktPub:
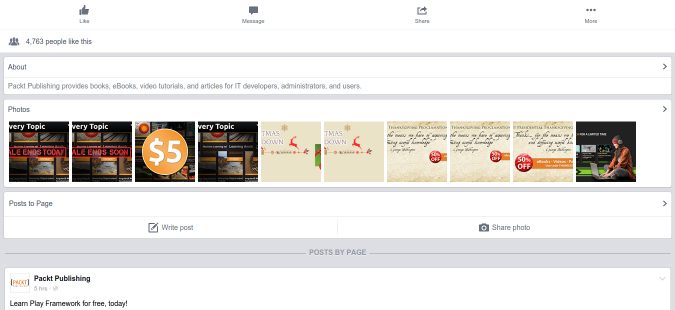
If we interacted with the mobile website and then checked...