

The significance of DataFrames and the Catalyst Optimizer (and Project Tungsten) is the increase in performance of PySpark queries when compared to non-optimized RDD queries. As shown in the following figure, prior to the introduction of DataFrames, Python query speeds were often twice as slow as the same Scala queries using RDD. Typically, this slowdown in query performance was due to the communications overhead between Python and the JVM:
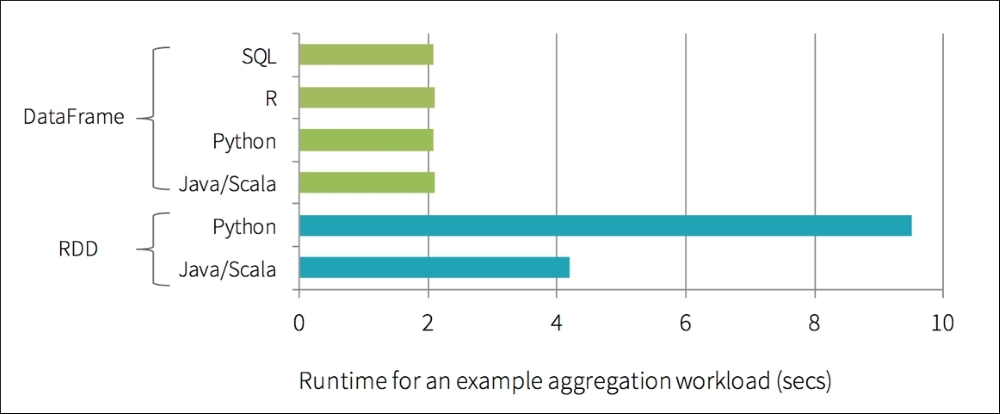
Source: Introducing DataFrames in Apache-spark for Large Scale Data Science at http://bit.ly/2blDBI1
With DataFrames, not only was there a significant improvement in Python performance, there is now performance parity between Python, Scala, SQL, and R.