

Refer to the following for more information about k-means and k-means++:
K-means algorithm suffers from at least two shortcomings:
- The worst-case time complexity of the algorithm is super polynomial in the input size, meaning that it is not bounded above by any polynomial
- Standard algorithm can perform arbitrarily poor in comparison to the optimal clustering because it finds only an approximation of the real optimum
Try it out yourself: put four pins on a map, as shown in the following image. After running clustering several times, you may notice that the algorithm often converges to the suboptimal solution:
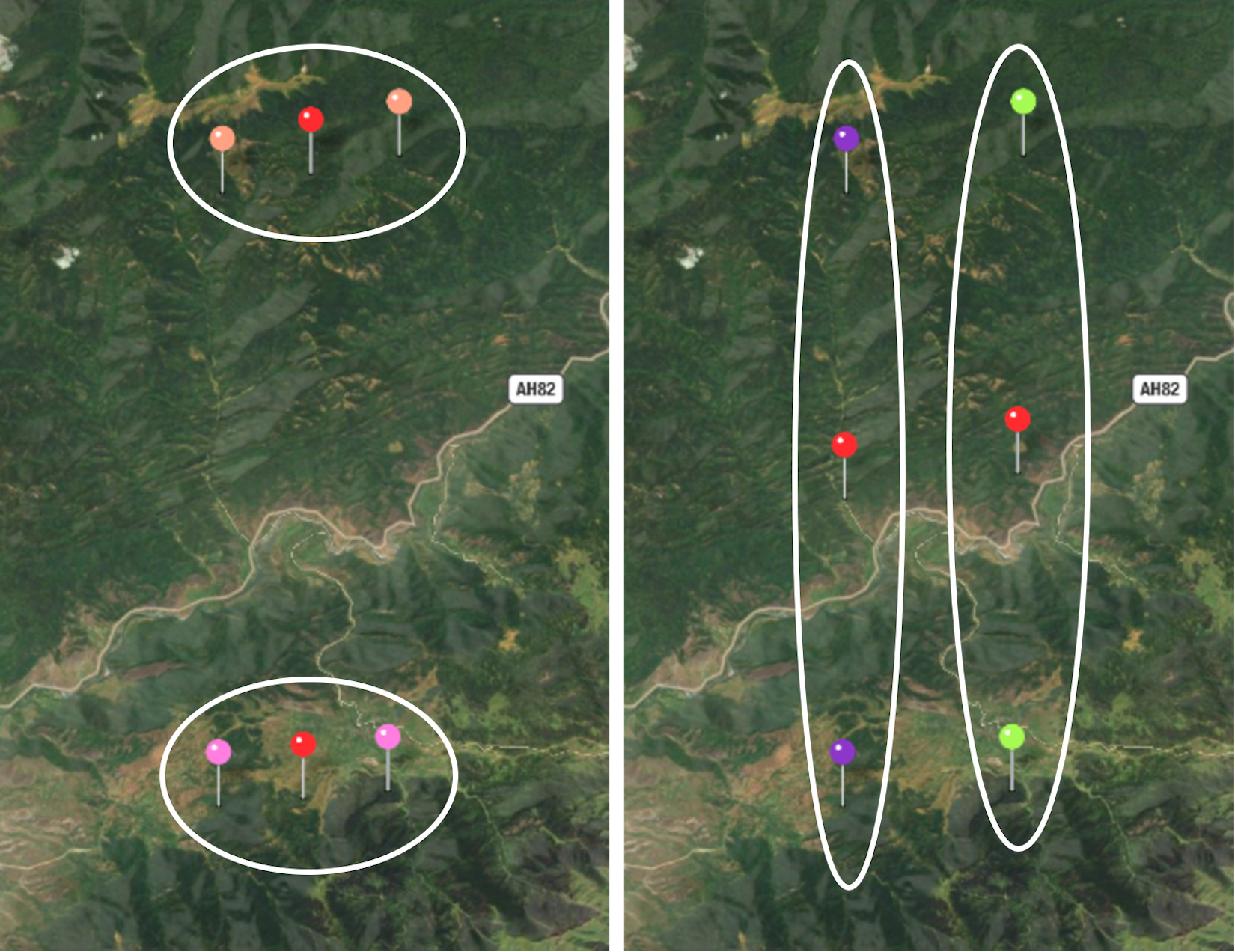
Figure 4.4: Optimal and non-optimal clustering results on the same dataset