Joblib is a Python library created by the developers of scikit-learn. Its main mission is to improve the performance of long-running Python functions. Joblib achieves these improvements through caching and parallelization using multiprocessing or threading under the hood. Install Joblib as follows:
$ pip3 install joblib
We will reuse the code from the previous example, only changing the parallel() function. Refer to the joblib_demo.py file in this book's code bundle:
def parallel(nprocs):
start = timeit.default_timer()
Parallel(nprocs)(delayed(simulate)(i) for i in xrange(10, 50))
end = timeit.default_timer() - start
print(nprocs, "Parallel time", end)
return end
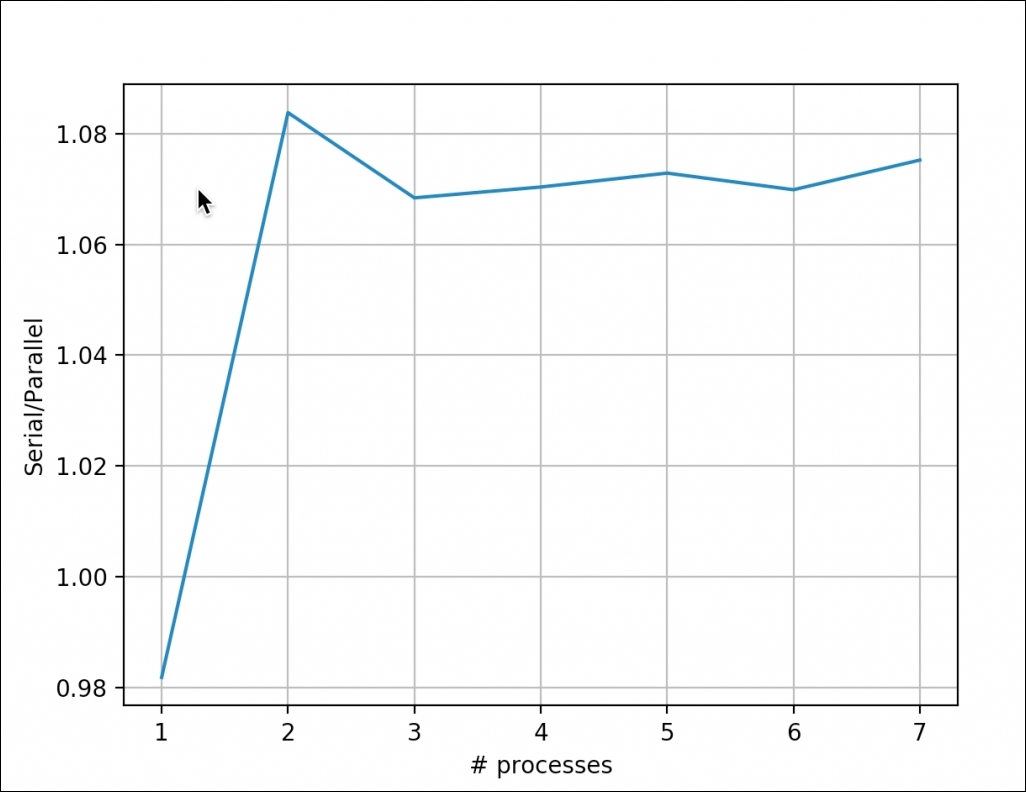
Refer to the following plot for the end result (the number of processors is hardware dependent):