

The last thing we have to do before we start actually writing some code and analyzing data using Spark is to get some data to analyze. There's some really cool movie ratings data out there from a site called grouplens.org. They actually make their data publicly available for researchers like us, so let's go grab some. I can't actually redistribute that myself because of the licensing agreements around it, so I have to walk you through actually going to the grouplens website and downloading its MovieLens dataset onto your computer, so let's go get that out of the way right now.
If you just go to grouplens.org, you should come to this web page:
This is a collection of movie ratings data, which has over 40 million movie ratings available in the complete dataset, so this qualifies as big data. The way it works is that people go to MovieLens.org, shown as follows, and rate movies that they've seen. If you want, you can create an account there and play with it yourself; it's actually pretty good. I've had a go myself: Godfather, meh, not really my cup of tea. Casablanca - of course, great movie. Four and a half stars for that. Spirited Away - love that stuff:
The more you rate the better your recommendations become, and it's a good way to actually get some ideas for some new movies to watch, so go ahead and play with it. Enough people have done this; they've actually amassed, like I said, over 40 million ratings, and we can actually use that data for this book. At first, we will run this just on your desktop, as we're not going to be running Spark on a cluster until later on. For now, we will use a smaller dataset, so click on the datasets tab on grouplens.org and you'll see there are many different datasets you can get. The smallest one is 100,000 ratings:
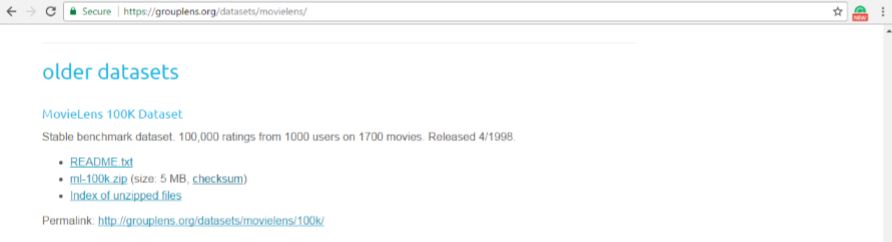
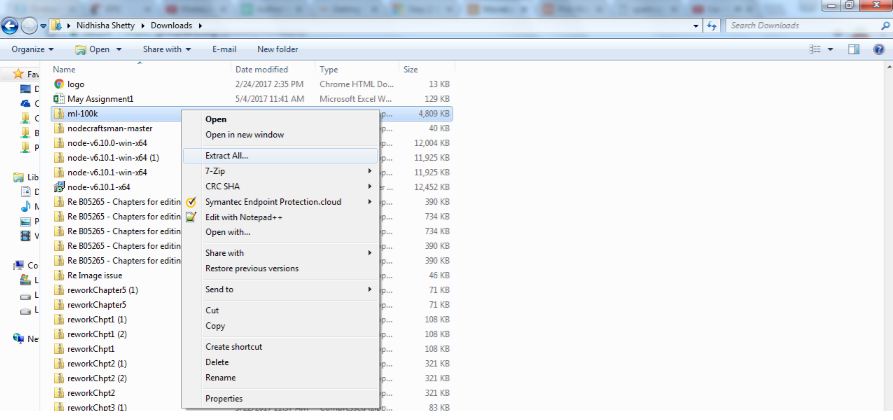
One thing to keep in mind is that this dataset was released in 1998, so you're not going to see any new movies in here. Movies such as Star Wars, some of the Star Trek movies, and some of the more popular classics, will all be in there, so you'll still recognize some of the movies that we're working with. Go ahead and click on the ml-100k.zip file to download that data, and once you have that, go to your Downloads folder, right-click on the folder that came down, and extract it:

You should end up with a ml-100k folder as shown here:
Now remember, at the beginning of this chapter we set up a home for all of your stuff for this book in the C folder in SparkCourse. So navigate to your C:\SparkCourse directory now, and copy the ml-100k folder into your C:\SparkCourse folder:

This will give you everything you need. Now, inside this ml-100k folder, you should see something like the screenshot shown as follows. There's a u.data file that contains all the actual movie ratings and a u.item file that contains the lookup table for all the movie IDs to movie names. We will use both of these files extensively in the chapters coming up:
At this point, you should have an ml-100k folder inside your SparkCourse folder.
All the housekeeping is out of the way now. You've got Spark set up on your computer running on top of the JDK in a Python development environment, and we have some data to play with from MovieLens, so let's actually write some Spark code.